
自然語言處理6 -- 情感分析
系列文章,請多關注
Tensorflow原始碼解析1 – 核心架構和原始碼結構
帶你深入AI(1) - 深度學習模型訓練痛點及解決方法
自然語言處理1 – 分詞
自然語言處理2 – jieba分詞用法及原理
自然語言處理3 – 詞性標註
自然語言處理4 – 句法分析
自然語言處理5 – 詞向量
自然語言處理6 – 情感分析
1 概述
情感分析是自然語言處理中常見的場景,比如淘寶商品評價,餓了麼外賣評價等,對於指導產品更新迭代具有關鍵性作用。通過情感分析,可以挖掘產品在各個維度的優劣,從而明確如何改進產品。比如對外賣評價,可以分析菜品口味、送達時間、送餐態度、菜品豐富度等多個維度的使用者情感指數,從而從各個維度上改進外賣服務。
情感分析可以採用基於情感詞典的傳統方法,也可以採用基於深度學習的方法,下面詳細講解
2 基於情感詞典的傳統方法
2.1 基於詞典的情感分類步驟
基於情感詞典的方法,先對文字進行分詞和停用詞處理等預處理,再利用先構建好的情感詞典,對文字進行字串匹配,從而挖掘正面和負面資訊。如下圖
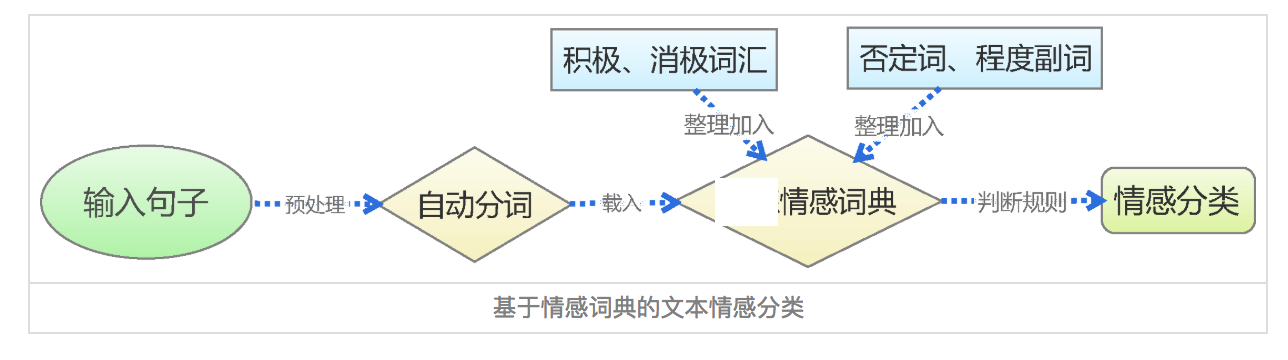
2.2 情感詞典
情感詞典包含正面詞語詞典、負面詞語詞典、否定詞語詞典、程度副詞詞典等四部分。如下圖
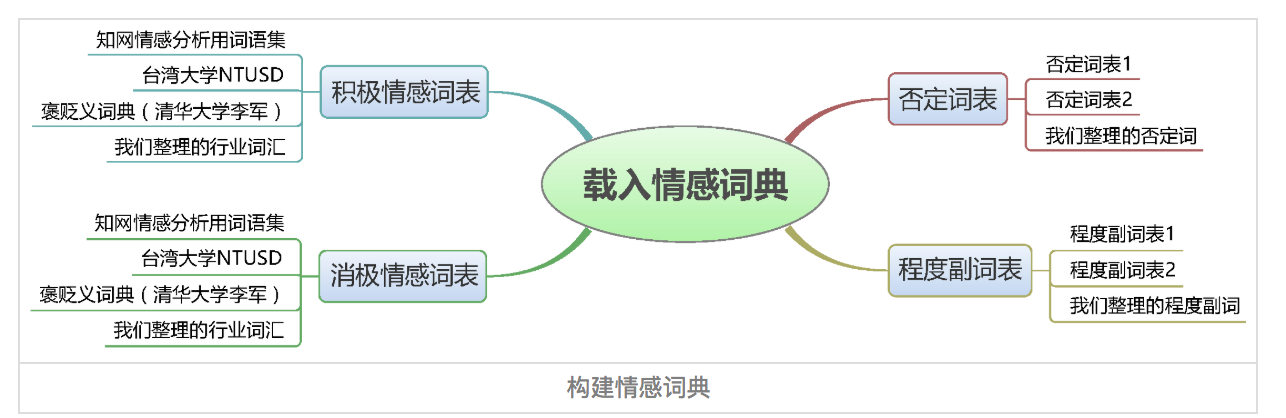
詞典包含兩部分,詞語和權重,如下
正面: 很快 1.75 挺快 1.75 還好 1.2 很萌 1.75 服務到位 1 負面: 無語 2 醉了 2 沒法吃 2 不好 2 太差 5 太油 2.5 有些油 1 鹹 1 一般 0.5 程度副詞: 超級 2 超 2 都 1.75 還 1.5 實在 1.75 否定詞: 不 1 沒 1 無 1 非 1 莫 1 弗 1 毋 1
情感詞典在整個情感分析中至關重要,所幸現在有很多開源的情感詞典,如BosonNLP情感詞典,它是基於微博、新聞、論壇等資料來源構建的情感詞典,以及知網情感詞典等。當然我們也可以通過語料來自己訓練情感詞典。
2.3 情感詞典文字匹配演算法
基於詞典的文字匹配演算法相對簡單。逐個遍歷分詞後的語句中的詞語,如果詞語命中詞典,則進行相應權重的處理。正面詞權重為加法,負面詞權重為減法,否定詞權重取相反數,程度副詞權重則和它修飾的詞語權重相乘。如下圖
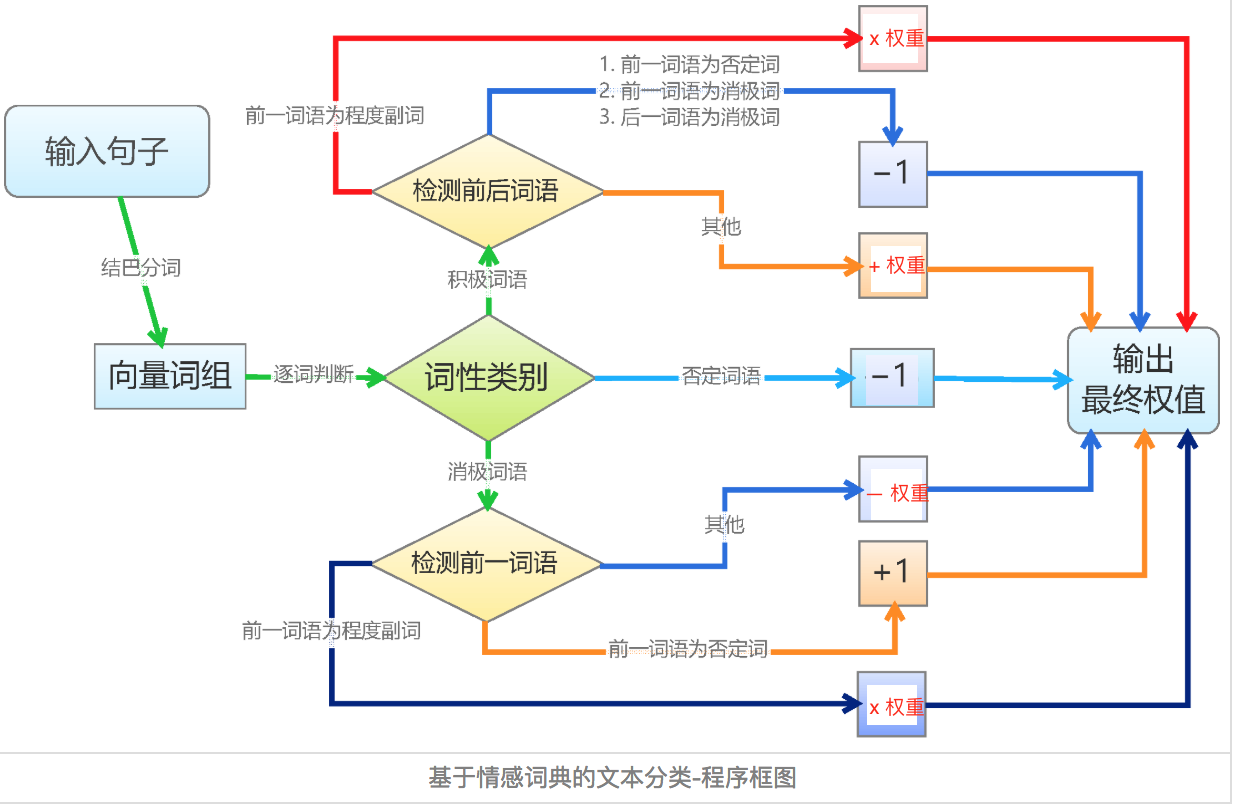
利用最終輸出的權重值,就可以區分是正面、負面還是中性情感了。
2.4 缺點
基於詞典的情感分類,簡單易行,而且通用性也能夠得到保障。但仍然有很多不足
- 精度不高。語言是一個高度複雜的東西,採用簡單的線性疊加顯然會造成很大的精度損失。詞語權重同樣不是一成不變的,而且也難以做到準確。
- 新詞發現。對於新的情感詞,比如給力,牛逼等等,詞典不一定能夠覆蓋
- 詞典構建難。基於詞典的情感分類,核心在於情感詞典。而情感詞典的構建需要有較強的背景知識,需要對語言有較深刻的理解,在分析外語方面會有很大限制。
3 基於深度學習的演算法
近年來,深度學習在NLP領域內也是遍地開花。在情感分類領域,我們同樣可以採用深度學習方法。基於深度學習的情感分類,具有精度高,通用性強,不需要情感詞典等優點。
3.1 基於深度學習的情感分類步驟
基於深度學習的情感分類,首先對語句進行分詞、停用詞、簡繁轉換等預處理,然後進行詞向量編碼,然後利用LSTM或者GRU等RNN網路進行特徵提取,最後通過全連線層和softmax輸出每個分類的概率,從而得到情感分類。

3.2 程式碼示例
下面通過程式碼來講解這個過程。下面是我週末寫的,2018年AI Challenger細粒度使用者評論情感分析比賽中的程式碼。專案資料來源於大眾點評,訓練資料10萬條,驗證1萬條。分析大眾點評使用者評論中,關於交通,菜品,服務等20個維度的使用者情感指數。分為正面、負面、中性和未提及四類。程式碼在驗證集上,目前f1 socre可以達到0.62。
3.2.1 分詞和停用詞預處理
資料預處理都放在了PreProcessor類中,主函式是process。步驟如下
- 讀取原始csv檔案,解析出原始語句和標註
- 錯別字,繁簡體,拼音,語義不明確等詞語的處理
- stop words停用詞處理
- 分詞,採用jieba分詞進行處理。分詞這兒有個trick,由於分詞後較多口語化的詞語不在詞向量中,所以對這部分詞語從jieba中del掉,然後再進行分詞。直到只有為數不多的詞語不在詞向量中為止。
- 構建詞向量到詞語的對映,並對詞語進行數字編碼。這一步比較常規。
class PreProcessor(object):
def __init__(self, filename, busi_name="location_traffic_convenience"):
self.filename = filename
self.busi_name = busi_name
self.embedding_dim = 256
# 讀取詞向量
embedding_file = "./word_embedding/word2vec_wx"
self.word2vec_model = gensim.models.Word2Vec.load(embedding_file)
# 讀取原始csv檔案
def read_csv_file(self):
reload(sys)
sys.setdefaultencoding('utf-8')
print("after coding: " + str(sys.getdefaultencoding()))
data = pd.read_csv(self.filename, sep=',')
x = data.content.values
y = data[self.busi_name].values
return x, y
# todo 錯別字處理,語義不明確詞語處理,拼音繁體處理等
def correct_wrong_words(self, corpus):
return corpus
# 去掉停用詞
def clean_stop_words(self, sentences):
stop_words = None
with open("./stop_words.txt", "r") as f:
stop_words = f.readlines()
stop_words = [word.replace("\n", "") for word in stop_words]
# stop words 替換
for i, line in enumerate(sentences):
for word in stop_words:
if word in line:
line = line.replace(word, "")
sentences[i] = line
return sentences
# 分詞,將不在詞向量中的jieba分詞單獨挑出來,他們不做分詞
def get_words_after_jieba(self, sentences):
# jieba分詞
all_exclude_words = dict()
while (1):
words_after_jieba = [[w for w in jieba.cut(line) if w.strip()] for line in sentences]
# 遍歷不包含在word2vec中的word
new_exclude_words = []
for line in words_after_jieba:
for word in line:
if word not in self.word2vec_model.wv.vocab and word not in all_exclude_words:
all_exclude_words[word] = 1
new_exclude_words.append(word)
elif word not in self.word2vec_model.wv.vocab:
all_exclude_words[word] += 1
# 剩餘未包含詞小於閾值,返回分詞結果,結束。否則新增到jieba del_word中,然後重新分詞
if len(new_exclude_words) < 10:
print("length of not in w2v words: %d, words are:" % len(new_exclude_words))
for word in new_exclude_words:
print word,
print("\nall exclude words are: ")
for word in all_exclude_words:
if all_exclude_words[word] > 5:
print "%s: %d," % (word, all_exclude_words[word]),
return words_after_jieba
else:
for word in new_exclude_words:
jieba.del_word(word)
raise Exception("get_words_after_jieba error")
# 去除不在詞向量中的詞
def remove_words_not_in_embedding(self, corpus):
for i, sentence in enumerate(corpus):
for word in sentence:
if word not in self.word2vec_model.wv.vocab:
sentence.remove(word)
corpus[i] = sentence
return corpus
# 詞向量,建立詞語到詞向量的對映
def form_embedding(self, corpus):
# 1 讀取詞向量
w2v = dict(zip(self.word2vec_model.wv.index2word, self.word2vec_model.wv.syn0))
# 2 建立詞語詞典,從而知道文字中有多少詞語
w2index = dict() # 詞語為key,索引為value的字典
index = 1
for sentence in corpus:
for word in sentence:
if word not in w2index:
w2index[word] = index
index += 1
print("\nlength of w2index is %d" % len(w2index))
# 3 建立詞語到詞向量的對映
# embeddings = np.random.randn(len(w2index) + 1, self.embedding_dim)
embeddings = np.zeros(shape=(len(w2index) + 1, self.embedding_dim), dtype=float)
embeddings[0] = 0 # 未對映到的詞語,全部賦值為0
n_not_in_w2v = 0
for word, index in w2index.items():
if word in self.word2vec_model.wv.vocab:
embeddings[index] = w2v[word]
else:
print("not in w2v: %s" % word)
n_not_in_w2v += 1
print("words not in w2v count: %d" % n_not_in_w2v)
del self.word2vec_model, w2v
# 4 語料從中文詞對映為索引
x = [[w2index[word] for word in sentence] for sentence in corpus]
return embeddings, x
# 預處理,主函式
def process(self):
# 讀取原始檔案
x, y = self.read_csv_file()
# 錯別字,繁簡體,拼音,語義不明確,等的處理
x = self.correct_wrong_words(x)
# stop words
x = self.clean_stop_words(x)
# 分詞
x = self.get_words_after_jieba(x)
# remove不在詞向量中的詞
x = self.remove_words_not_in_embedding(x)
# 詞向量到詞語的對映
embeddings, x = self.form_embedding(x)
# 列印
print("embeddings[1] is, ", embeddings[1])
print("corpus after index mapping is, ", x[0])
print("length of each line of corpus is, ", [len(line) for line in x])
return embeddings, x, y
3.2.2 詞向量編碼
詞向量編碼步驟主要有:
- 載入詞向量。詞向量可以從網上下載或者自己訓練。網上下載的詞向量獲取簡單,但往往缺失特定場景的詞語。比如大眾點評菜品場景下的魚香肉絲、幹鍋花菜等詞語,而且往往這些詞語在特定場景下還十分重要。而自己訓練則需要幾百G的語料,在高效能伺服器上連續訓練好幾天,成本較高。可以將兩種方法結合起來,也就是載入下載好的詞向量,然後利用補充語料進行增量訓練。
- 建立詞語到詞向量的對映,也就是找到文字中每個詞語的詞向量
- 對文字進行詞向量編碼,可以通過keras的Embedding函式,或者其他深度學習庫來搞定。
前兩步在上面程式碼中已經展示了,詞向量編碼程式碼示例如下
Embedding(input_dim=len(embeddings),
output_dim=len(embeddings[0]),
weights=[embeddings],
input_length=self.max_seq_length,
trainable=False,
name=embeddings_name))
3.2.3 構建LSTM網路
LSTM網路主要分為如下幾層
- 兩層的LSTM。
- dropout,防止過擬合
- 全連線,從而可以輸出類別
- softmax,將類別歸一化到[0, 1]之間
LSTM網路是重中之重,這兒可以優化的空間很大。比如可以採用更優的雙向LSTM,可以加入注意力機制。這兩個trick都可以提高最終準確度。另外可以建立分詞和不分詞兩種情況下的網路,最終通過concat合併。
class Model(object):
def __init__(self, busi_name="location_traffic_convenience"):
self.max_seq_length = 100
self.lstm_size = 128
self.max_epochs = 10
self.batch_size = 128
self.busi_name = busi_name
self.model_name = "model/%s_seq%d_lstm%d_epochs%d.h5" % (self.busi_name, self.max_seq_length, self.lstm_size, self.max_epochs)
self.yaml_name = "model/%s_seq%d_lstm%d_epochs%d.yml" % (self.busi_name, self.max_seq_length, self.lstm_size, self.max_epochs)
def split_train_data(self, x, y):
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.1)
# 超長的部分設定為0,截斷
x_train = sequence.pad_sequences(x_train, self.max_seq_length)
x_val = sequence.pad_sequences(x_val, self.max_seq_length)
# y弄成4分類,-2未提及,-1負面,0中性,1正面
y_train = keras.utils.to_categorical(y_train, num_classes=4)
y_val = keras.utils.to_categorical(y_val, num_classes=4)
return x_train, x_val, y_train, y_val
def build_network(self, embeddings, embeddings_name):
model = Sequential()
model.add(Embedding(input_dim=len(embeddings),
output_dim=len(embeddings[0]),
weights=[embeddings],
input_length=self.max_seq_length,
trainable=False,
name=embeddings_name))
model.add(LSTM(units=self.lstm_size, activation='tanh', return_sequences=True, name='lstm1'))
model.add(LSTM(units=self.lstm_size, activation='tanh', name='lstm2'))
model.add(Dropout(0.1))
model.add(Dense(4))
model.add(Activation('softmax'))
return model
def train(self, embeddings, x, y):
model = self.build_network(embeddings, "embeddings_train")
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
# 訓練,採用k-folder交叉訓練
for i in range(0, self.max_epochs):
x_train, x_val, y_train, y_val = self.split_train_data(x, y)
model.fit(x_train, y_train, batch_size=self.batch_size, validation_data=(x_val, y_val))
# 儲存model
yaml_string = model.to_yaml()
with open(self.yaml_name, 'w') as outfile:
outfile.write(yaml.dump(yaml_string, default_flow_style=True))
# 儲存model的weights
model.save_weights(self.model_name)
def predict(self, embeddings, x):
# 載入model
print 'loading model......'
with open(self.yaml_name, 'r') as f:
yaml_string = yaml.load(f)
model = model_from_yaml(yaml_string)
# 載入權重
print 'loading weights......'
model.load_weights(self.model_name, by_name=True)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
# 預測
x = sequence.pad_sequences(x, self.max_seq_length)
predicts = model.predict_classes(x) # 得到分類結果,它表徵的是類別序號
# 轉換
classes = [0, 1, -2, -1]
predicts = [classes[item] for item in predicts]
np.set_printoptions(threshold=np.nan) # 全部列印
print(np.array(predicts))
return predicts
3.2.4 softmax輸出類別
這一部分上面程式碼已經講到了,不在贅述。softmax只是一個歸一化,講資料歸一化到[0, 1]之間,從而可以得到每個類別的概率。我們最終取概率最大的即可。
3.3 基於深度學習的情感分析難點
基於深度學習的情感分析難點也很多
- 語句長度太長。很多使用者評論都特別長,分詞完後也有幾百個詞語。而對於LSTM,序列過長會導致計算複雜、精度降低等問題。一般解決方法有進行停用詞處理,無關詞處理等,從而縮減文字長度。或者對文字進行摘要,抽離出語句主要成分。
- 新詞和口語化的詞語特別多。使用者評論語句不像新聞那樣規整,新詞和口語化的詞語特別多。這個問題給分詞和詞向量帶來了很大難度。一般解決方法是分詞方面,建立使用者詞典,從而提高分詞準確度。詞向量方面,對新詞進行增量訓練,從而提高新詞覆蓋率。
4. 總結
文字情感分析是NLP領域一個十分重要的問題,對理解使用者意圖具有決定性的作用。通過基於詞典的傳統演算法和基於深度學習的演算法,可以有效的進行情感分析。當前情感分析準確率還有待提高,任重而道遠!
系列文章,請多關注
Tensorflow原始碼解析1 – 核心架構和原始碼結構
帶你深入AI(1) - 深度學習模型訓練痛點及解決方法
自然語言處理1 – 分詞
自然語言處理2 – jieba分詞用法及原理
自然語言處理3 – 詞性標註
自然語言處理4 – 句法分析
自然語言處理5 – 詞向量
自然語言處理6 – 情感分析