
Matlab生成歸一化直方圖
使用matlab的函式histogram可以直接得到資料的直方圖,但這並不是歸一化的直方圖。
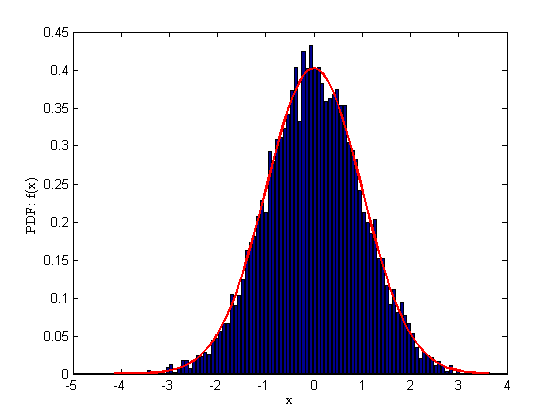
使用如下程式碼可以得到歸一化的直方圖
x = randn(10000, 1);
numOfBins = 100;
[histFreq, histXout] = hist(x, numOfBins);
binWidth = histXout(2)-histXout(1);
figure;
bar(histXout, histFreq/binWidth/sum(histFreq));
xlabel('x');
ylabel('PDF: f(x)');
hold on
% fit a normal dist to check the pdf 結果示意:
相關推薦
Matlab生成歸一化直方圖
使用matlab的函式histogram可以直接得到資料的直方圖,但這並不是歸一化的直方圖。 使用如下程式碼可以得到歸一化的直方圖 x = randn(10000, 1); numOfBins = 100; [histFreq, histXout] = hist(x, numOf
C++ 實現matlab資料歸一化函式mapminmax
matlab驗證了我的資料處理方法,今天換成了c++版,實現matlab的mapminmax()函式。程式碼如下: void normalize(float *data) { int datamax = 1; //設定歸一化的範圍 int datamin = 0;
歸一化灰度直方圖 Matlab
影象直方圖描述的是影象各個灰度級的統計特性,他表示影象每一灰度級與該灰度級出現頻率的對應關係,因為灰度級不是連續的,自然,灰度直方圖是一個離散函式。橫座標是灰度級g,縱座標是Ng,如果總的畫素
MATLAB中實現資料 [0,1] 歸一化
記錄一下,在做機器學習時,資料處理部分要花很多精力。資料處理的方式有很多種,今天記錄的是[0,1]歸一化,該法可以避免在較大數值範圍內的特性凌駕於較小數值範圍內的特性,先看下原理。 設序列代表特性A,對它們進行變換 則得到的新序列 下面看程式碼: clc clear all %
Matlab 歸一化函式premnmx
(1)基本演算法:函式目的是把資料處理成[-1,1]之間,演算法是: 如a=[2,4,3,5],那麼計算過程就是: 2*(2-2)/(5-2)-1=-1; 2*(4-2)/(5-2)-1=1/3=0.6666; 2*(3-2)/(5-2)-1=-0.6666 2*(5-2)/(5-2
機器學習中訓練集和測試集歸一化-matlab
本文不是介紹如何使用matlab對資料集進行歸一化,而是通過matlab來介紹一下資料歸一化的概念。 以下內容是自己的血淚史,因為歸一化的錯誤,自己的實驗過程至少走了兩個星期的彎路。由此可見機器學習中一些基礎知識和概念還是應該紮實掌握。 背景介紹:
Matlab Tricks(七)—— 矩陣列/列的歸一化/單位化(normalize)
對矩陣的每一列進行歸一化(單位化) D = randn(20, 50); % 標準正態分佈 D = D*diag(1./sqrt(sum(D.*D)));
Matlab三種歸一化方法
歸一化的具體作用是歸納統一樣本的統計分佈性。歸一化在0-1之間是統計的概率分佈,歸一化在-1--+1之間是統計的座標分佈。歸一化有同一、統一和合一的意思。無論是為了建模還是為了計算,首先基本度量單位要同一,神經網路是以樣本在事件中的統計分別機率來進行訓練(概率計算)和預測的,且sigmoid函式的取值
MATLAB實現影象灰度歸一化
在許多影象處理系統中,對影象進行歸一化都是必備的預處理過程。一般而言,對於灰度影象(或彩色通道的每個顏色分量)進行灰度歸一化就是:使其畫素的灰度值分佈在0~255之間,避免影象對比度不足(影象畫素亮度分佈不平衡)從而對後續處理帶來干擾。 一種常見的影象歸一化原
matlab隨機數及行、列歸一化
(1) 按照【正態分佈】生成一定範圍內的隨機數 A1=normrnd(0.9533,0.0022,[23,10000]); (均值,標準差,[行數,列數]) (2) 按【均勻分佈】生成一定範圍內的隨機數 w1=unifrnd(0,1,10000,23); (上限,下限,
資料歸一化matlab及python 實現
歸一化的目的簡而言之,是使得沒有可比性的資料變得具有可比性,同時又保持相比較的兩個資料之間的相對關係。 歸一化首先在維數非常多的時候,可以防止某一維或某幾維對資料影響過大,其次可以程式可以執行更快。 資料歸一化應該針對屬性,而不是針對每條資料,針對每條資
MATLAB資料矩陣單位化,歸一化,標準化
Y = -0.9261 0.4840 -0.7522 0.9640 1.1002 0.2177 0.0358 0.6225 -1.1419 1.5457 1.3487 1.1224 1.0886 1.6449 1.6257
Python基礎day-18[面向對象:繼承,組合,接口歸一化]
ini 關系 acl 報錯 子類 wan 使用 pytho 減少 繼承: 在Python3中默認繼承object類。但凡是繼承了object類以及子類的類稱為新式類(Python3中全是這個)。沒有繼承的稱為經典類(在Python2中沒有繼承object以及他的子類都是
轉:數據標準化/歸一化normalization
簡單 此外 urn csdn bsp center sum 又能 超出 轉自:數據標準化/歸一化normalization 這裏主要講連續型特征歸一化的常用方法。離散參考[數據預處理:獨熱編碼(One-Hot Encoding)]。 基礎知識參考: [均值、方差與協方
numpy 矩陣歸一化
ges 矩陣歸一化 mali zeros sha ati ret turn tile new_value = (value - min)/(max-min) def normalization(datingDatamat): max_arr = datingData
【深度學習】批歸一化(Batch Normalization)
學習 src 試用 其中 put min 平移 深度 優化方法 BN是由Google於2015年提出,這是一個深度神經網絡訓練的技巧,它不僅可以加快了模型的收斂速度,而且更重要的是在一定程度緩解了深層網絡中“梯度彌散”的問題,從而使得訓練深層網絡模型更加容易和穩定。所以目前
Hulu機器學習問題與解答系列 | 二十三:神經網絡訓練中的批量歸一化
導致 xsl 泛化能力 恢復 不同 詳細 過程 ice ini 來看看批量歸一化的有關問題吧!記得進入公號菜單“機器學習”,復習之前的系列文章噢。 今天的內容是 【神經網絡訓練中的批量歸一化】 場景描述 深度神經網絡的訓練中涉及諸多手調參數,如學習率,權重衰減系數,
softmax_loss的歸一化問題
outer bubuko prot 歸一化 實現 大小 定義 num blog cnn網絡中,網絡更新一次參數是根據loss反向傳播來,這個loss是一個batch_size的圖像前向傳播得到的loss和除以batch_size大小得到的平均loss。 softmax_l
機器學習數據預處理——標準化/歸一化方法總結
目標 out enc 並不是 depend 區間 standards ima HA 通常,在Data Science中,預處理數據有一個很關鍵的步驟就是數據的標準化。這裏主要引用sklearn文檔中的一些東西來說明,主要把各個標準化方法的應用場景以及優缺點總結概括,以來充當