
論文筆記:ResNet v2
阿新 • • 發佈:2019-01-12
ResNet v2
1、四個問題
- 要解決什麼問題?
- 進一步提高ResNet的效能。
- 解釋為何Identity mapping(恆等對映)的效果會比較好。
- 用了什麼方法解決?
- 提出了一個新的殘差單元結構。
- 從理論和實驗上分析了identity mapping的有效性。
- 效果如何?
- 使用1001層的ResNet,在CIFAR-10資料集上錯誤率為4.62%,在CIFAR-100資料集上錯誤率為22.71%。都是目前最好的結果。
- ImageNet 2012資料集上,top-1錯誤率為20.1%,top-5錯誤率為4.8%,超過Inception v3,也是最優結果。
- 還存在什麼問題?
- ResNet模型可以有極深的深度,更強大的學習能力,同時也會帶來更多的引數,更大的計算量,如何對其進行壓縮,降低計算成本也是個需要考慮的問題。
2、論文概述
2.1、簡介
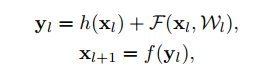
- 上式是原始殘差單元,公式引數說明:
- 和 分別是第 層網路的輸入和輸出。
- 表示殘差函式。
- 表示恆等對映(identity mapping)。
- 表示ReLU函式。
- 後面預設認為 , 。

- 原始殘差單元結構如a圖所示,改進的殘差單元結構如b圖所示。
- 為了理解跳躍連線(skip connection)的作用,作者實驗了各種不同的 (identity mapping),即圖中的灰色線部分。最終的實驗結果表明,保持一個clean information path有助於提升效果。
- 提出了預啟用(pre-activation)和後啟用(post-activation)。
- 預啟用:bn -> relu -> conv
- 後啟用:conv -> bn -> relu
- 在新的殘差結構中改進如下:
- 將啟用函式放到旁路,從shortcut中移除,保證clean information path。
- 旁路中的結構從 conv-bn-relu(後啟用) 轉換為 bn-relu-conv(預啟用)。
2.2、關於深度殘差網路結構的分析
- 原始殘差單元的數學表示,符號意義不做贅述。
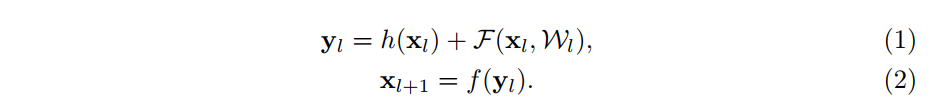
- 假設 (恆等對映), (啟用函式也是一個恆等對映)。
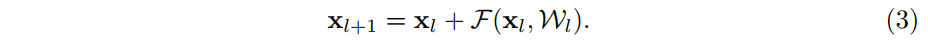
- 迴圈套用 ,可以得到下式:
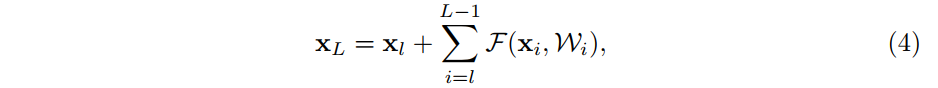
- 按照鏈式法則求導:
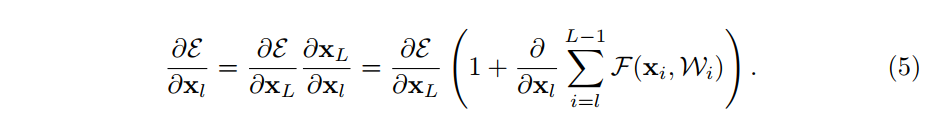
- 公式說明:
- 是loss函式值。
- 根據鏈式求導法則,可以求出梯度,如上式所示。
- 梯度 可以拆分成兩部分:對於第 層的梯度, ;以及每一層卷積層所擬合的殘差函式對應的梯度, 。
- 對於普通的沒有shortcut連線的網路來說,只存在 這一項,而對於ResNet來說,則額外引入了 。 的存在確保了較深層網路的梯度可以傳遞到較淺層網路去。
- 其實另外還有一點,引入了shortcut還減少了梯度消散的可能性。因為除非