
Elasticsearch1.x 拼音分詞實現全拼首字母中文混合搜尋
一、外掛簡介
elasticsearch-analysis-lc-pinyin是一款elasticsearch拼音分詞外掛,可以支援按照全拼、首字母,中文混合搜尋。
首先舉個栗子說明下,我們在淘寶搜尋框中輸入“jianpan” 可以搜尋到關鍵字包含“鍵盤”的商品。不僅僅輸入全拼,有時候我們輸入首字母、拼音和首字母、中文和首字母的混合輸入,比如:“鍵pan”、“j盤”、“jianp”、“jpan”、“jianp”、“jp” 等等,都應該匹配到鍵盤。通過elasticsearch-analysis-lc-pinyin這個外掛就能做到類似的搜尋

二、安裝外掛
elasticsearch-analysis-lc-pinyin一共有兩個版本分別是1.4.5和2.2.2,和es的版本對應
1.4.5 這個版本對應ES1.X
2.2.2這個版本對應ES2.X
請根據需要安裝對應的版本,下面地址中壓縮包已經包含了這兩個版本
當然也可以自己下載elasticsearch-analysis-lc-pinyin的原始碼自己maven build出來,這樣可以避免版本衝突
git 地址:http://git.oschina.net/music_code_m/elasticsearch-analysis-lc-pinyin
如下,我已將下載下來的包放在 /home/chennan/soft 目錄下,下面我將以elasticsearch1.4.5為例安裝elasticsearch-analysis-lc-pinyin-1.4.5拼音分詞器

進入到es的plugins目錄,下面是未安裝時的樣子

接著開啟終端命令列執行如下命令安裝外掛
./../bin/plugin --install analysis-lc-pinyin --url file:/home/chennan/soft/elasticsearch-analysis-lc-pinyin-1.4.5.zip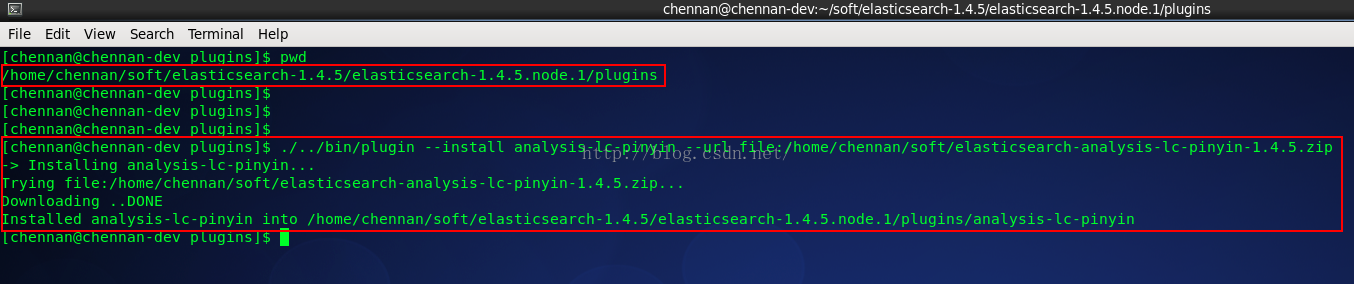
粗線上面結果就表示安裝成功了 ^ ^,安裝完成後會在plugins目錄下生成一個 analysis-lc-pinyin的目錄,如下
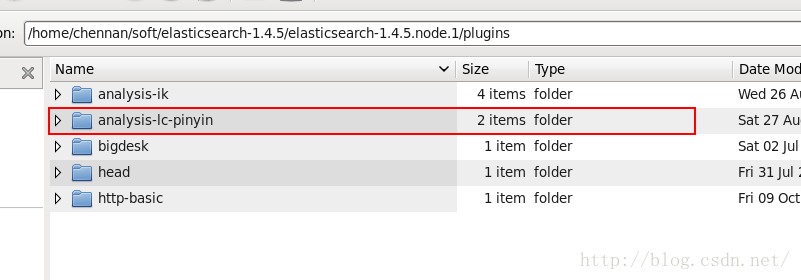
接下來配置elasticsearch.yml,在末尾加上如下配置,如下因為我也安裝了IK分詞器所以配置這樣,如果你沒有安裝IK可以將下面ik的部分刪除
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_max_word:
type: ik
use_smart: false
ik_smart:
type: ik
use_smart: true
lc:
alias: [lc_analyzer]
type: org.elasticsearch.index.analysis.LcPinyinAnalyzerProvider
lc_index:
type: lc
analysisMode: index
lc_search:
type: lc
analysisMode: search然後啟動es,這裡我啟動兩個節點。從啟動日誌中可以看到es成功載入了拼音外掛,如下
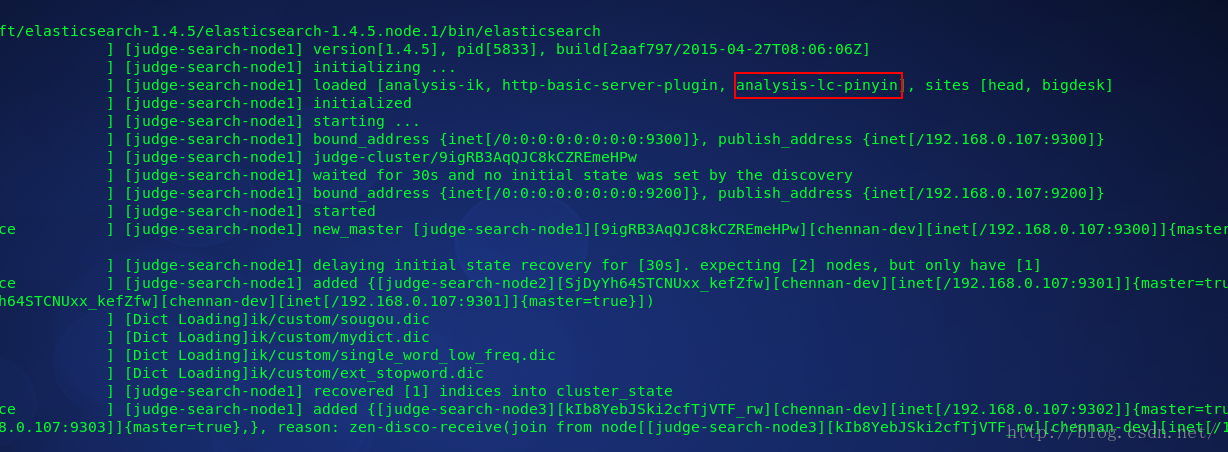
到這裡,外掛就安裝完成了。我們可以通過一個簡單的curl命令來測試分詞器時候正常工作
curl -XGET '192.168.0.107:9200/_analyze?analyzer=lc_search&pretty' -d 'dafeiji'輸入“dafeiji”可以切分出來“da”、“fei”、“ji” 證明一切都OK啦

接下來就來試試藉助這個拼音分詞器來執行搜尋,看看效果
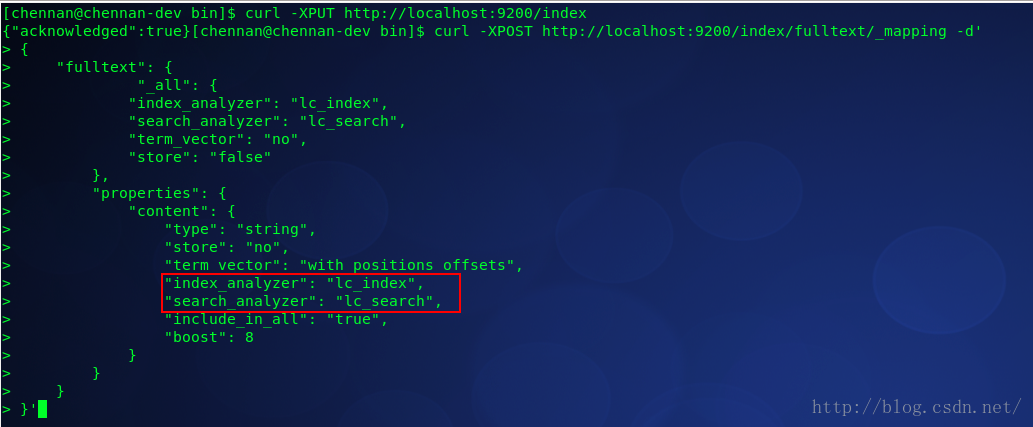
1、首先建立一個索引 ,然後執行putmapping , 這裡的索引名叫index,type叫fulltext,其中content這個欄位採用拼音分詞。注意這裡用到兩個不同的分詞器
索引過程採用:lc_index分詞器
搜尋過程採用:lc_search分詞器
curl -XPUT http://localhost:9200/index
curl -XPOST http://localhost:9200/index/fulltext/_mapping -d'
{
"fulltext": {
"_all": {
"index_analyzer": "lc_index",
"search_analyzer": "lc_search",
"term_vector": "no",
"store": "false"
},
"properties": {
"content": {
"type": "string",
"store": "no",
"term_vector": "with_positions_offsets",
"index_analyzer": "lc_index",
"search_analyzer": "lc_search",
"include_in_all": "true",
"boost": 8
}
}
}
}'
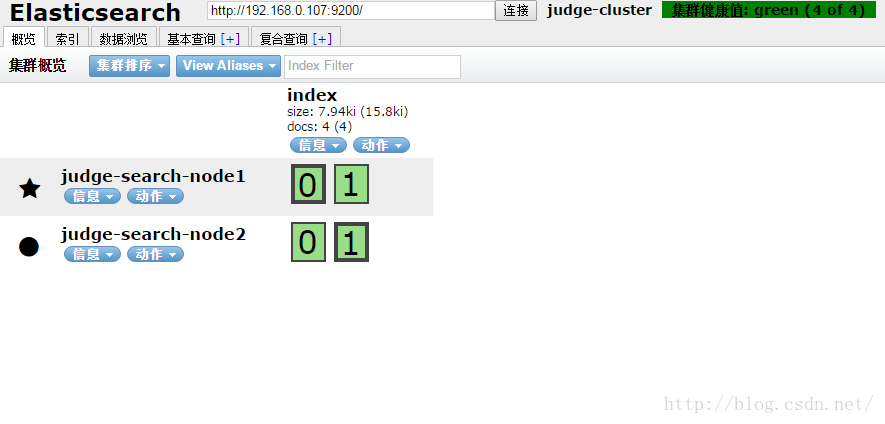
然後索引幾條資料,這裡索引的4個公司的名稱,陸金所、阿里巴巴、騰訊、百度、如下:
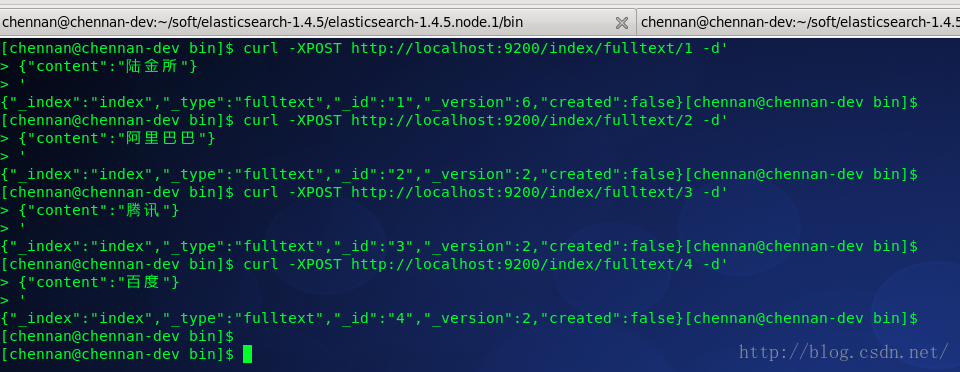
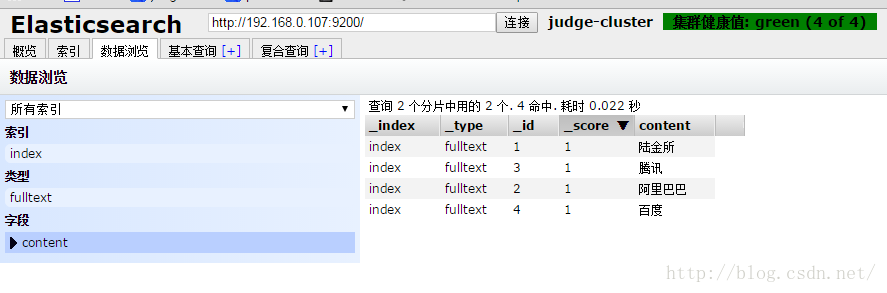
接下來執行幾個搜尋,查詢的DSL像這樣
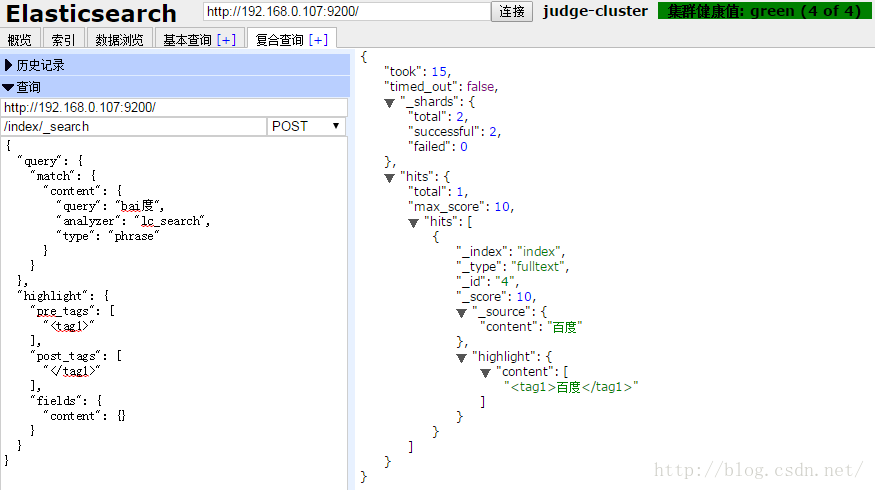
{
"query": {
"match": {
"content": {
"query": "bai度",
"analyzer": "lc_search",
"type": "phrase"
}
}
},
"highlight": {
"pre_tags": [
"<tag1>"
],
"post_tags": [
"</tag1>"
],
"fields": {
"content": {}
}
}
}搜尋“bai度”
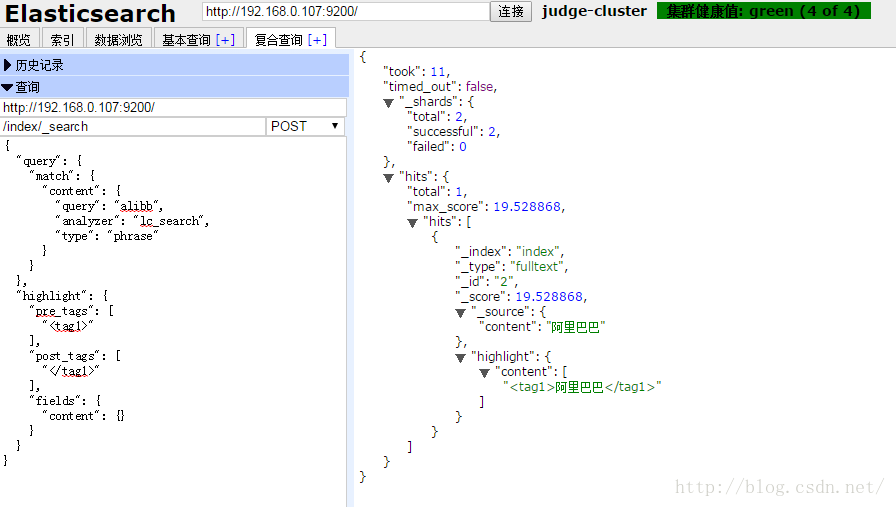
搜尋“阿li巴b”
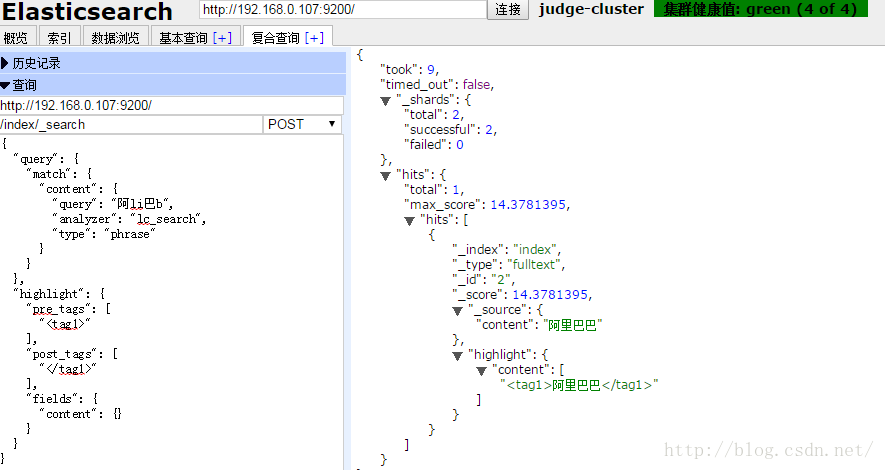
搜尋“ljs”
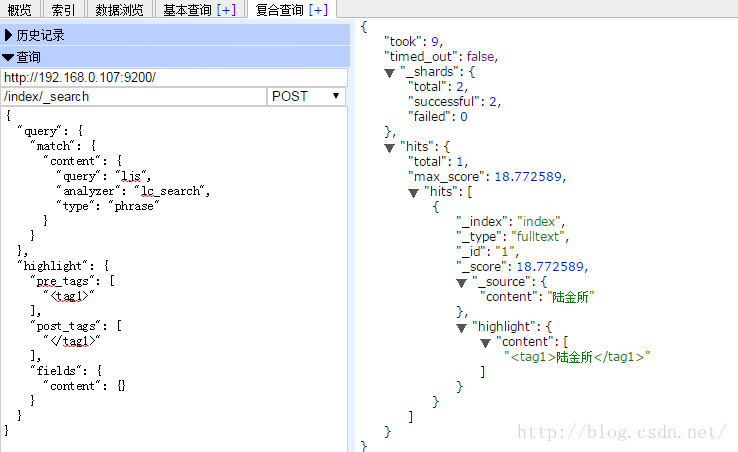
搜尋“alibb”
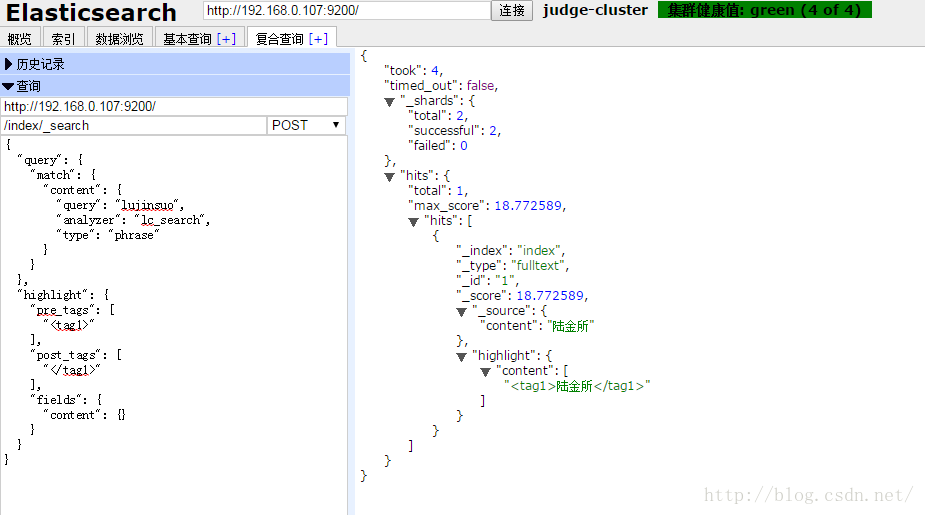
搜尋“lujinsuo”
下面使用es 客戶端來做查詢
@Test
public void testPinyinSearch() {
final String index = "index";
final String type = "fulltext";
SearchRequestBuilder requestBuilder = elasticIndexOperateHelper.getClient().prepareSearch(index).setTypes(type);
QueryBuilder pinyinSearch = QueryBuilders
.matchQuery("content", "lu金s")
.type(MatchQueryBuilder.Type.PHRASE)
.analyzer("lc_search")
.zeroTermsQuery(MatchQueryBuilder.ZeroTermsQuery.NONE);
SearchResponse response = requestBuilder
.setQuery(pinyinSearch)
.setHighlighterPreTags("</tag1>")
.setHighlighterPostTags("<tag1>")
.addHighlightedField("content")
.execute().actionGet();
System.out.println(response);
}查詢結果如下:
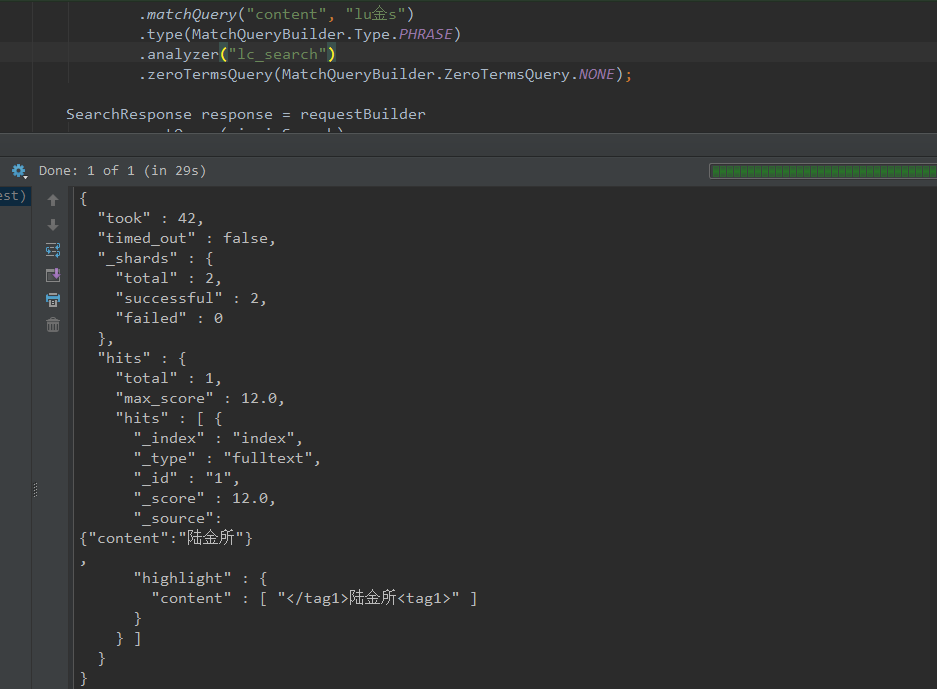
相關推薦
Elasticsearch1.x 拼音分詞實現全拼首字母中文混合搜尋
一、外掛簡介 elasticsearch-analysis-lc-pinyin是一款elasticsearch拼音分詞外掛,可以支援按照全拼、首字母,中文混合搜尋。 首先舉個栗子說明下,我們在淘寶搜尋框中輸入“jianpan” 可以搜尋到關鍵字包含“鍵盤”的商品。不僅僅輸入
java之獲取中文全拼/首字母工具(大小寫轉換)
java之獲取中文全拼/首字母工具(大小寫轉換) 需要jar包pinyin4j支援 maven地址 <dependency> <groupId>com.belerweb</groupId> <artif
java獲取中文全拼/首字母工具以及大小寫轉換
pom: <!--漢轉拼音 --> <dependency> <groupId>com.belerweb</groupId> <artifactId>
lucene6.6+拼音分詞+ik分詞實現
原來專案使用的是solr進行建立索引與查詢,最近想改為lucene。對於最新版的lucene網上的資料沒有solr多,並且solr很多功能直接配置就可以使用,但是lucene都要通過api進行封裝使用。下面是自己使用lucene6.6+拼音分詞和ik中文分詞實現的功能:
一種拼音分詞器的JAVA實現
原理很簡單,就是模式匹配。根據中文全拼的特點,即聲母和韻母配對,首先列舉出所有的聲母,再分別列舉出所有聲母對應的韻母集,分詞的過程就是遍歷匹配的過程。 publicclass SpellTool { static String result = "";//
elasticsearch實現中文分詞和拼音分詞混合查詢+CompletionSuggestion
引言 之前已經介紹瞭如何搭建elasticsearch服務端和簡單的索引建立,和中文分詞的支援。今天我們來說一說如何實現elasticsearch同時實現中文分詞和pinyin分詞。並且實現類似百度搜索欄的搜尋建議的功能。 混合查詢 實現混合查詢有很多
elasticsearch ik分詞實現 中文、拼音、同義詞搜尋
EasticSearch版本:1.5.2 2.1、在elasticsearch的plugins目錄下,新建analysis-pinyin資料夾,解壓上述壓縮包,將裡面的 放到analys
elasticsearch 拼音+ik分詞,spring data elasticsearch 拼音分詞
maven打包 vat tokenizer origin emp 下載源 case remove 解壓 elasticsearch 自定義分詞器 安裝拼音分詞器、ik分詞器 拼音分詞器: https://github.com/medcl/elasticsearch-an
JS實現獲取漢字首字母拼音、全拼音及混拼音的方法
pla 輸入 files sta add 參考 x11 lba odi 本文實例講述了JS實現獲取漢字首字母拼音、全拼音及混拼音的方法。分享給大家供大家參考,具體如下: 這裏需要用到一個js獲取漢字拼音的插件,可點擊此處本站下載。 運行效果如下: 完整示例代碼: ?
Lucene筆記20-Lucene的分詞-實現自定義同義詞分詞器-實現分詞器(良好設計方案)
一、目前存在的問題 在getSameWords()方法中,我們使用map臨時存放了兩個鍵值對用來測試,實際開發中,往往需要很多的這種鍵值對來處理,比如從某個同義詞詞典裡面獲取值之類的,所以說,我們需要一個類,根據key提供近義詞。 為了能更好的適應應用場景,我們先定義一個介面,其中定義一
Lucene筆記19-Lucene的分詞-實現自定義同義詞分詞器-實現分詞器
一、同義詞分詞器的程式碼實現 package com.wsy; import com.chenlb.mmseg4j.Dictionary; import com.chenlb.mmseg4j.MaxWordSeg; import com.chenlb.mmseg4j.analysis.MM
Lucene筆記18-Lucene的分詞-實現自定義同義詞分詞器-思路分析
一、實現自定義同義詞分詞器思路分析 前面文章我們提到同義詞分詞器,這裡我們先來分析下同義詞分詞器的設計思路。 首先我們有一個需要分詞的字串string,通過new StringReader(string)拿到Reader。 使用analyzer.tokenStream("co
基於java版jieba分詞實現的tfidf關鍵詞提取
基於java版jieba分詞實現的tfidf關鍵詞提取 文章目錄 基於java版jieba分詞實現的tfidf關鍵詞提取 為了改善我的 個性化新聞推薦系統的基於內容相似度的推薦演算法效果,我嘗試找尋關鍵詞提取效果可能優於本來使用的ansj的tfi
和我一起打造個簡單搜索之IK分詞以及拼音分詞
生產環境 ast ken ade usr block analyzer osi 繼續 elasticsearch 官方默認的分詞插件,對中文分詞效果不理想,它是把中文詞語分成了一個一個的漢字。所以我們引入 es 插件 es-ik。同時為了提升用戶體驗,引入 es-pinyi
和我一起打造個簡單搜尋之IK分詞以及拼音分詞
elasticsearch 官方預設的分詞外掛,對中文分詞效果不理想,它是把中文詞語分成了一個一個的漢字。所以我們引入 es 外掛 es-ik。同時為了提升使用者體驗,引入 es-pinyin 外掛。本文介紹這兩個 es 外掛的安裝。 環境 本文以及後續 es 系列文章都基於 5.5.3 這個版本的 el
Elasticsearch拼音分詞和IK分詞的安裝及使用
一、Es外掛配置及下載 1.IK分詞器的下載安裝 關於IK分詞器的介紹不再多少,一言以蔽之,IK分詞是目前使用非常廣泛分詞效果比較好的中文分詞器。做ES開發的,中文分詞十有八九使用的都是IK分詞器。 下載地址:https://github.com/medcl/elasticsearch-analysis
es配置中文和拼音分詞器
1.簡介 es預設使用standard分詞器 es還有其他分詞器比如simple writespace language 2.配置中文分詞器(需先安裝git maven unzip) git clone https://github.com/medcl/elasticse
ElasticSearch學習筆記(二)IK分詞器和拼音分詞器的安裝
ElasticSearch是自帶分詞器的,但是自帶的分詞器一般就只能對英文分詞,對英文的分詞只要識別空格就好了,還是很好做的(ES的這個分詞器和Lucene的分詞器很想,是不是直接使用Lucene的就不知道),自帶的分詞器對於中文就只能分成一個字一個字,這個顯然
使用 Elasticsearch ik分詞實現同義詞搜尋
1、首先需要安裝好Elasticsearch 和elasticsearch-analysis-ik分詞器 2、配置ik同義詞 Elasticsearch 自帶一個名為 synonym 的同義詞 filter。為了能讓 IK 和 synonym 同時工作,我們需要定義新的
Solr6.5配置中文分詞IKAnalyzer和拼音分詞pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安裝與配置 (一) 一文中介紹了solr6.5的安裝。這篇文章主要介紹建立Solr的Core並配置中文IKAnalyzer分詞和拼音檢索。 一、建立Core: 1、首先在solrhome(solrhome的路徑和配置見Solr6.5在Centos6上的安裝與配置