
技術面試的系統設計題(二)
可擴充套件性
基礎
現在您已經設計了一個可靠的抽象體系結構,下一步就是將其擴充套件。如果你從來沒有建立過大規模的系統,這個任務看起來有點令人生畏。
可擴充套件的Web開發
比較建議看一看視訊,視訊裡面講的非常雜亂,感覺沒有什麼邏輯,所以我整理的也是亂七八糟。他說的東西也是非常基礎的,但是鞏固一下也是很不錯的。
具體的一些技術方面的大致情況可以看看這篇博文,裡面講到了Web伺服器從基礎到複雜的擴充套件過程。比這個課更有邏輯。
垂直擴充套件
對於一臺伺服器使用更多的更好的硬體,如下資源
- CPU
- cores, L2 Cache, …
- Disk
- 介面:PATA, SATA, SAS, …
- RAID
- RAM
限制:沒有那麼多物理資源
水平擴充套件
不同於垂直擴充套件那樣選用最貴最好的伺服器,水平擴充套件接受了便宜的硬體設施,但是用了更多的便宜且更慢的伺服器實現了擴充套件。也就是,使用了大規模的叢集分散式。
負載均衡
通過Load Balancer將服務叢集黑盒化,那麼對於外界而言,他們始終以為訪問的是一個伺服器。
Load Balancer具有一個公開的IP地址,而後端伺服器不需要公開的IP地址,而是用內網IP地址。類似NAT協議那樣。
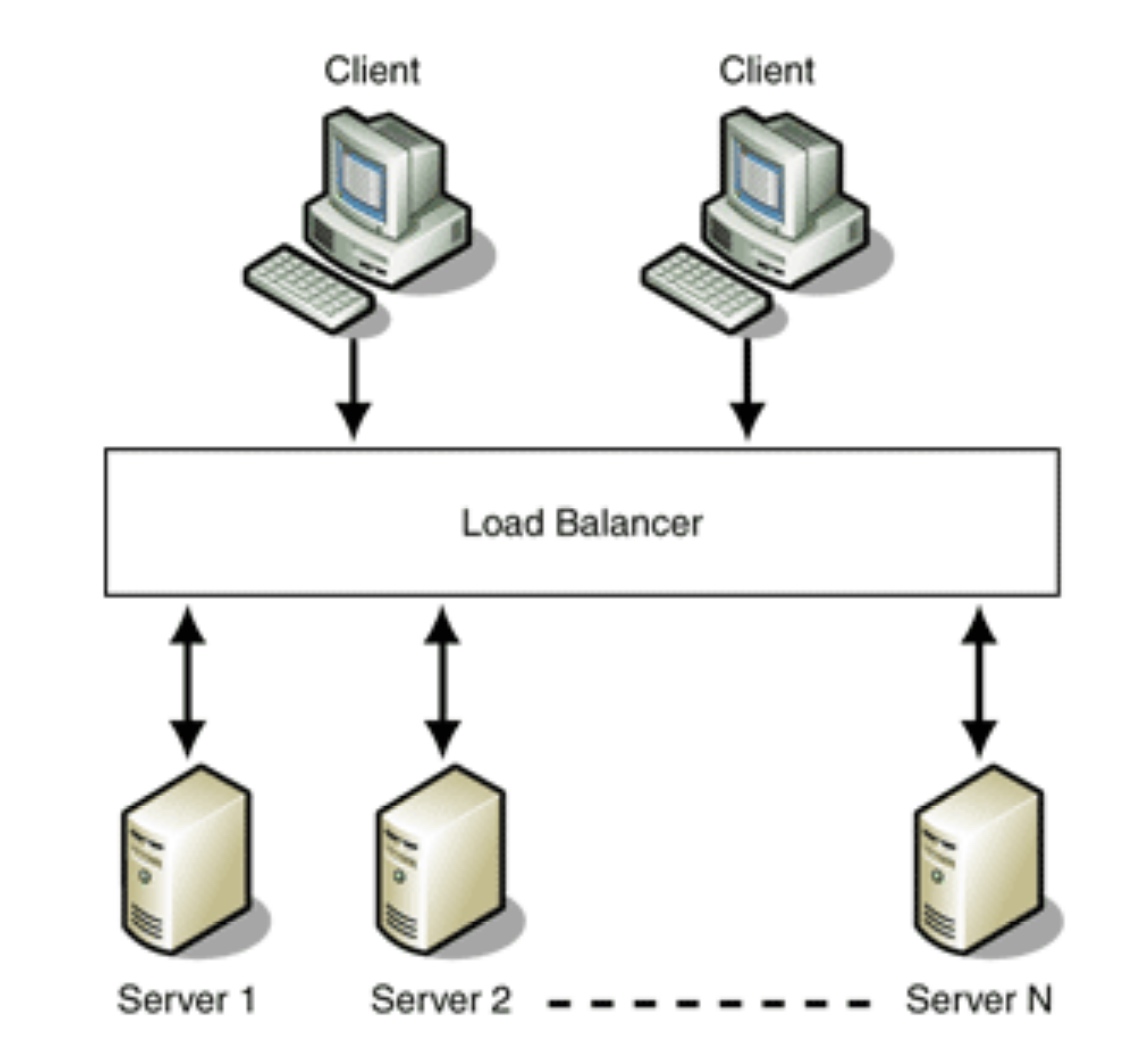
關於負載均衡的演算法由很多,比如,Round Robin演算法(一種以輪詢的方式依次將一個域名解析到多個IP地址的排程不同伺服器的計算方法。)
開源的DNS系統BIND對於同樣的域名請求,可能會返回不同的IP地址。
- 軟體
- ELB
- HAProxy
- LVS
- 硬體
- Barracuda
- Cisco
- Citrix
- F5
共享儲存
RR可能會導致伺服器1總是受到請求,從而導致堵塞。即,因為負載均衡演算法的缺陷,導致負載均衡效果不理想。
sticky session問題:如果你登陸一個網址好多次,你的cookies和session等資訊會分佈在不同的機器上。那麼如果你的請求被分發到一個新的機器上,那麼這些就不復存在了,你必須重新登陸,重新新增購物車,這明顯是不行的。
為了讓負載均衡器能夠明白每一個Server所處的狀態,為了讓所有Server的資訊都保持一致,我們會使用共享儲存的設計。
但是同樣的共享儲存也是有一定缺陷的:
- 如果所有系統都使用一塊硬碟,如果這塊硬碟掛了,那麼所有的伺服器都不能使用了。
- 如果按照功能進行分機和儲存相應的資料,如,處理使用者登入請求和使用者cookies的記錄,視訊媒體等儲存。如果最關鍵的那臺伺服器宕機了,整個服務也就都沒有用了。
於是,我們可以使用增加硬碟數量實現備份。比如,我們同時用兩塊硬碟儲存同一份資料的兩個副本,這樣雖然增加了一些overhead,但是能夠實現備份。(關於這點還有很多論文去解釋和設計相應的系統,比如raft一致性協議等等)。
同時我們也可以使用兩塊硬碟儲存一份資料的不同部分,當一塊在寫的時候,我們可以寫另一塊。並行地執行寫入程式。
Cacheing
HTML檔案
簡單地將HTML儲存下來,或者以HTML模板的形式儲存一些不怎麼需要更改的內容。
SQL Cache
查詢的快取,可見其他資料庫的設計情況。
Memcached
其他第三方記憶體資料庫,用於快取。還有比如,reids等等。
但是也需要一些別的協議或者機制來維護這類的快取,如,同步問題, 垃圾回收
複製
主從模式
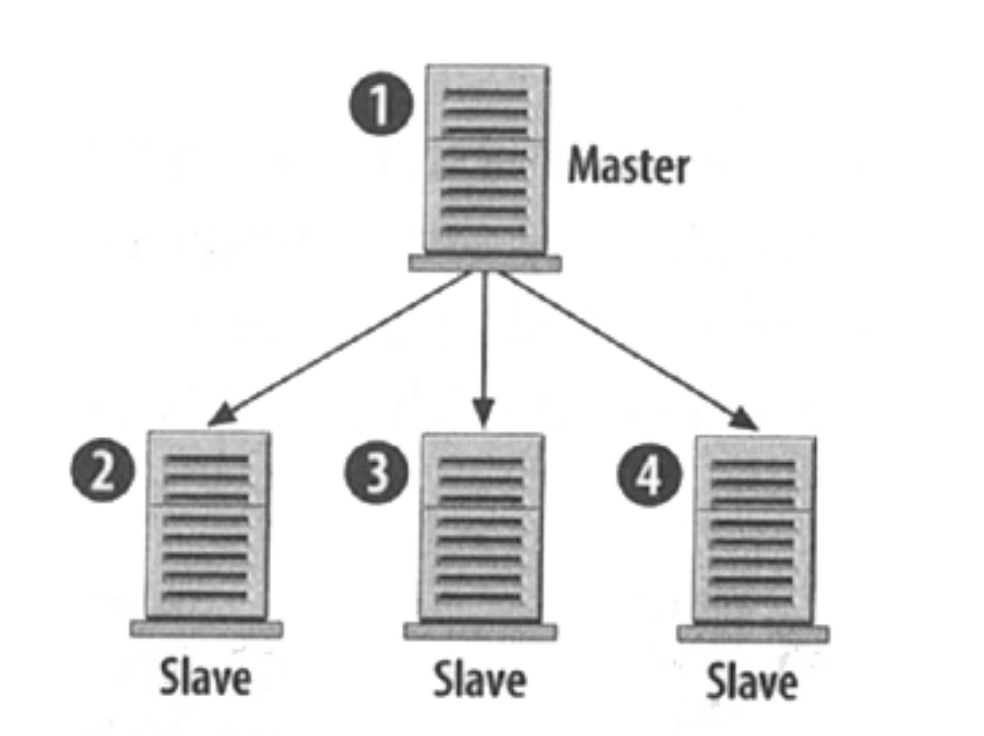
多主機模式

負載均衡+複製
有些類似資料庫讀寫分離或者資料庫的備份

資料分塊儲存

簡單易懂的可擴充套件
克隆
可擴充套件Web服務的公共伺服器通常是做為黑盒,並隱藏在負載平衡器後面。此負載平衡器將負載(來自使用者的請求)平均分配到您的組/應用程式伺服器群集上。這意味著,例如,如果小明與伺服器進行互動,則他的第一個請求可能在伺服器2進行處理,然後由伺服器9處理第二請求,然後第三請求上再次由伺服器2處理。
小明每次請求都應該得到相同(或者說一致)的結果,這與哪臺伺服器處理他的請求無關。
這是可擴充套件性的第一條黃金法則:每臺伺服器都包含完全相同的程式碼庫,不會在本地磁碟或記憶體中儲存任何與使用者相關的資料,如會話或配置檔案圖片。
會話需要儲存在所有應用程式伺服器均可訪問的集中式資料儲存中。它可以是外部資料庫或外部永續性快取,如Redis。外部持久快取比外部資料庫具有更好的效能。換句歡說,通過外部儲存是資料儲存不駐留在應用程式伺服器上。相反,它位於應用程式伺服器的資料中心內或附近的節點。
但是如何同時部署多臺呢?如何確保將程式碼更改併成功傳送到所有伺服器,而不是有些伺服器執行新程式碼而有些伺服器仍舊用舊程式碼?幸運的是,這個棘手的問題已經由偉大的工具Capistrano解決了。這需要一些學習,特別是如果你的Ruby不夠熟練中。
在將您的會話“外包”並從所有伺服器都能訪問的程式碼塊提供相同的程式碼後,就可以從這些伺服器之一(AWS稱之為AMI - Amazon Machine Image)建立映像檔案。將此AMI用作“超級克隆”所有的新例項都基於。每當你開始一個新的例項/克隆,只要做一個最新的程式碼的初始部署就足夠了!
資料庫
現在,所需的更改比僅新增更多克隆的伺服器更為激進,甚至可能需要一些勇氣。你可以選擇2個路徑:
路徑#1:是堅持使用MySQL,並保持野蠻的執行。聘請資料庫管理員告訴他做主從複製和讀寫分離(從從機讀取,寫入主機),並通過新增RAM來升級主伺服器。在幾個月的時間裡,你的資料庫管理員會想出“分片”,“反規範化”和“SQL調優”這樣的詞彙,並且會在接下來的幾周裡擔心必要的加班。那時,每一個新的動作來保持你的資料庫執行將比以前更昂貴和耗時。如果您選擇了Path#2,而您的資料集仍然很小並且易於遷移,那麼您可能會變得更好。
路徑#2:從頭開始正確反規範化,並且在任何資料庫查詢中不再包含連線。你可以使用MySQL,像NoSQL資料庫一樣使用它,或者你可以切換到一個更好,更容易擴充套件的NoSQL資料庫,比如MongoDB或者CouchDB。現在需要在應用程式程式碼中完成聯接。越早執行此步驟,您將來必須更改的程式碼越少。但即使您成功切換到最新,最好的NoSQL資料庫,並讓您的應用程式執行資料集連線,您的資料庫請求很快也會變得越來越慢。你將需要引入一個快取。(關於這一點,我不是很贊同,還是要根據應用場景分類,不是所有的場景適合使用NoSQL的,而且不同的NoSQL適用的地方也不同,HBase和Redis就很不一樣)
快取
對於“快取”,這兒指像Memcached或Redis這樣的記憶體快取(或者說,記憶體資料庫)。不要執行基於硬碟檔案的快取,它會使伺服器的克隆和自動擴充套件付出高昂的代價。
記憶體快取通常是一個簡單的KV鍵值儲存,它應該作為應用程式和資料儲存之間的緩衝層。無論何時您的應用程式必須讀取資料,它應該首先嚐試從快取中檢索資料。只有當它不在快取中時,才會嘗試從主資料來源獲取資料。
快取將每個資料集儲存在RAM中,所以能夠儘可能快地處理請求。例如,Redis可以在標準伺服器上託管時每秒執行幾十萬次讀取操作。還寫操作,特別是增量。
有兩種快取資料的模式。一箇舊的和一個新的:
#1 - 快取的資料庫查詢
這仍然是最常用的快取模式。每當您對資料庫執行查詢時,都會將結果資料集儲存在快取中。key是我們查詢的hash值。下次執行查詢時,首先檢查它是否已經在快取中。
這種模式有幾個問題。主要問題是資料到期。快取複雜查詢時,很難刪除快取的結果。當一條資料發生變化時(例如一個表格單元格),您需要刪除可能包含該表格單元格的所有快取查詢。這樣將會非常混亂。
#2 - 快取的物件
這是我強烈的建議,我總是喜歡這種模式。一般來說,將資料視為一個物件,就像你已經在你的程式碼(類,例項等)中做的那樣。讓您的類從您的資料庫中組合一個數據集,然後將該類的完整例項或組合資料集儲存在快取中。
聽起來很理論,我知道,但看看你通常的程式碼。例如,您有一個名為“Product”的類,它有一個名為“data”的屬性。這是包含產品的價格,文字,圖片和客戶評論的陣列。屬性“data”由類中的幾個方法填充,執行多個難以快取的資料庫請求,因為許多事情相互關聯。
現在,請執行以下操作:當您的類完成資料陣列的“組裝”時,直接將資料陣列或更好的類的完整例項儲存在快取中!這樣,只要有事情發生變化,就可以輕鬆地擺脫物件,並使程式碼的整體操作更加快速和合理。
最好的部分是:它使非同步處理成為可能!應用程式只訪問最新的快取物件,幾乎從不接觸資料庫!
快取物件的一些想法:
- 使用者會話(user sessions)從不使用資料庫
- 完全呈現的部落格文章
- 活動流
- 使用者< - >朋友關係
一般來說,我更喜歡Redis的Memcached,因為我喜歡Redis的額外資料庫特性,如永續性和內建的資料結構,如列表和集合。有了Redis和一個聰明的鑰匙,你甚至有可能完全擺脫一個數據庫。但是如果你只是需要快取,就可以使用Memcached。
非同步(Asynchronism)
請想象一下,你想在你最喜歡的麵包店買麵包。所以你走進麵包店,點了一個麵包,但那裡沒有面包!相反,在你點了的兩個小時之後,你的麵包才能被做好。這很煩人,不是嗎?
為了避免這樣的“請稍等” - 情況,需要完成非同步。麵包店有什麼好處,也許對你的網路服務或網路應用也有好處。
一般來說,有兩種方法/範例可以完成不同步。
非同步#1
讓我們想想前面的麵包店例子。非同步處理的第一種方式是“晚上烘烤麵包,早上賣”的方式。沒有等待時間。提到一個網路應用程式,這意味著提前完成耗時的工作,並以較低的請求時間完成完成的工作。
很多時候,這個範例被用來將動態內容轉化為靜態內容。一個網站的頁面(可能是用一個巨大的框架或CMS構建的)在每次更改時都被預先渲染並作為靜態HTML檔案儲存在本地。通常這些計算任務是定期完成的,也可能是由cronjob每小時呼叫一次的指令碼。整體通用資料的預先計算可以極大地改善網站和網路應用程式,並使其具有很高的可擴充套件性和效能。試想一下,如果指令碼會將這些預渲染的HTML頁面上傳到AWS S3或Cloudfront或其他付款雲網絡,就可以想象網站的可擴充套件性!您的網站將可以達到超級響應,可以處理數以每小時百萬計的遊客!
非同步#2
回到麵包店。不幸的是,有時顧客有特殊的要求,比如生日蛋糕-“生日快樂,小明”!麵包店無法預見到這種客戶的意願,所以當客戶在麵包店時要開始工作,並告訴他在第二天回來。引用一個Web服務,意味著非同步處理任務。
這是一個典型的工作流程:
使用者來到您的網站,並開始一個非常計算密集的任務,這將需要幾分鐘時間完成。因此,您的網站前端將作業傳送到任務佇列,並立即發回給使用者:您的任務正在被執行(或者等待執行),請繼續瀏覽頁面。任務隊伍被一群worker檢查,如果有新的任務出現,那麼worker就幹這個任務,幾分鐘後發出一個訊號表明任務已經完成。前端不斷地檢查新的“任務已經完成” - 訊號,看到任務完成並通知使用者。(這只是一個簡單的例子,檢查的機制也有很多,可以參見資料庫併發執行裡面如何執行查詢任務的。)
如果你現在想深入細節和實際的技術設計,我建議你看看RabbitMQ網站上的前3個教程。 RabbitMQ是幫助實現非同步處理的許多系統之一。你也可以使用ActiveMQ或簡單的Redis列表。基本的想法是有一個worker可以處理的任務或任務佇列。
非同步似乎很複雜,但絕對值得您花時間來了解它並自己實現。後端變得幾乎可以無限擴充套件,前端變得活潑,這對整體使用者體驗是有利的。
如果你做了一些耗時的事情,試著總是非同步地做。
例子
課程提供了一些公司的擴充套件性例子,參見原網址
綜合
一切都是一個權衡
這是系統設計中最基本的概念之一。
希望在這一點上,這對你來說不是一個驚喜。如果你看過真實的架構,就會發現很少有一種完美的方式來做事。每家公司都有不同的架構。設計一個可擴充套件的系統是一個優化任務:有大量的約束(時間,預算,知識,複雜性,當前可用的技術等等),並且你需要建立適合這些約束的最好的東西。每一種技術,每種模式對某些事物都是有益的,而對其他事物則不是那麼好。瞭解這些優點和缺點,優點和缺點是關鍵。
記住:沒有一個最佳的系統設計。
當然,有最好的做法,你可以使用。但是最後,這一切都歸結為在市場時間,系統複雜性,開發成本,維護成本,可用性等諸多方面之間的平衡。
能夠理解和討論這些權衡是系統設計(以及系統設計問題)的全部內容。
在你的準備中,不要試圖找到完美的東西。相反,關注每個可伸縮性模式的優點,缺點是什麼,以及為什麼人們比其他模式更喜歡它。
把它放在一起,保持最新狀態
在這一點上,你可以做的最有用的事情是拿出一個或兩個系統,其中包含你學到的可擴充套件性課程。
最後,你將在整個職業生涯中得到良好的服務,以便及時瞭解可伸縮性如何演變。例如,10年前,沒有亞馬遜網路服務,公司被迫管理自己的基礎設施。如今,使用EC2,RDS,S3,Elastic MapReduce等服務,您可以建立一個巨大的公司。所以,雖然AWS沒有改變基本的可擴充套件性原則,但它確實改變了人們在擴充套件時需要熟悉的技術格局。因此,保持最新是非常重要的(否則你會重新發明輪子)。
面試
那麼面試時你應該做什麼?
首先,請遵循系統設計流程。你已經知道如何應用它,所以我們將會簡短。不要跳過步驟,不要做假設,當問及時開始廣泛深入。
其次,請記住,系統設計問題是一個觀念交流平臺。準備討論權衡利弊。準備提供替代方案,提出問題,找出並解決瓶頸問題,根據面試者的偏好進行廣泛深入的討論。
不要保守:每當面試者挑戰你的架構選擇,承認很少一個想法是完美的,並概述了你的選擇的優點和缺點。開放討論期間面試官提出的新約束,並即時調整架構。
最重要的是,玩得開心。夢想建築是一個非常刺激的心理過程 - 享受和保持積極。你已經具備了正確的知識,只要在面試中應用,你就會做得很好。
Tiny URL
在上一章中,我們說到了我們的系統面臨著幾個挑戰:
- 每秒400個請求
- 有3TB的資料去儲存並且快速查詢
那麼我們就要在抽象設計的基礎上進行修改,使其成為可擴充套件的設計,並能夠解決上面的限制:
- 應用服務層:
- 從單獨一臺伺服器可以處理多少資料開始
- 用負載測試去測試速率
- 增加一個負載均衡器,以及逐漸增加叢集:解決通訊量,增加可用性
- 資料儲存
- 資料特性
- 上億個物件
- 每個物件都特別小(<1k)
- 物件與物件之間沒有關係
- 讀 是 寫 的9倍(每秒360次讀,40次寫)
- 5TBs urls,36GBs hashes
- 對映表
- hash: varchar(6)
- origin: varchar(512)
- 在hash屬性上建立聚集索引(36GB+),我們希望將這個索引存在記憶體中。
- 垂直擴充套件MySQL伺服器
- 資料分片:5片資料,600GBs資料,8GB索引
- 讀寫分離,主從複製(從多臺從機讀取,寫入主機,由主機更新資料到從機)
- 資料特性
相關推薦
技術面試的系統設計題(二)
可擴充套件性 基礎 現在您已經設計了一個可靠的抽象體系結構,下一步就是將其擴充套件。如果你從來沒有建立過大規模的系統,這個任務看起來有點令人生畏。 可擴充套件的Web開發 視訊地址 課件地址 比較建議看一看視訊,視訊裡面講的非常雜亂,感覺沒有
java面試每日十題(二)
11、switch 是否能作用在byte 上,是否能作用在long 上,是否能作用在String上? 答:switch可以作用於icsb(i see sb)上,即int、char、short、byte和他們的包裝類;不可作用於fdlb(伏地撈逼)上,即float、 dou
Linux系統運維常見面試簡答題系列(二)(14題)
local 企業 nginx服務 簡答題 ip協議 php out gin 報錯 1. /var/log/messages日誌出現kernel:nf_conntrack:tablefull,dropping packet,請問是什麽原因導致的,如何解決? 此報錯為iptab
信息系統監理師(二)-- 項目成本計算(計算題)
stand dal 3.5 更多 .cn 之間 還需 如果 blog 成本計算題: 重點: 加強難度: 題目一: 答案: 1、EV=3 、PV=4、AC=3.5 2、CPI=3/3.5=0.8, 因為CPI<1
Spring系列框架系統復習(二)spring原理-面試常遇到的問題
適配器 solver ring 兩種 頁面 筆記 分享圖片 tar 表現 1、什麽是DI機制? 依賴註入(Dependecy Injection)和控制反轉(Inversion of Control)是同一個概念,具體的講:當某個角色需要另外一個角色協助的時候,在傳統的程
推薦系統技術之文字相似性計算(二)
上一篇中我們的小明已經中學畢業了,今天這一篇繼續文字相似性的計算。首先前一篇不能解決的問題是因為我們只是機械的計算了詞的向量,並沒有任何上下文的關係,所以思想還停留在機器層面,還沒有到更高的層次上來,正因為這樣才有了自然語言處理這門課程了。今天我們稍微說說這個吧,後臺留言很多
設計模式(二): 工廠模式
dem blank hibernate 執行 oid code 做出 void actor 工廠模式 工廠模式(Factory Pattern)是 Java 中最常用的設計模式之一。這種類型的設計模式屬於創建型模式,它提供了一種創建對象的最佳方式。 在工廠模式中,我們在創建
(數字IC)低功耗設計入門(二)——功耗的分析
layout 變化 監視 merge obj source divide 傳播 總結 前面學習了進行低功耗的目的個功耗的構成,今天就來分享一下功耗的分析。由於是面向數字IC前端設計的學習,所以這裏的功耗分析是基於DC中的power compiler工具;更精確的功耗分析
ssh環境下客戶信息管理系統學習問題(二)
2.3 根據 包括 style 有用 信息 org 翻譯 use 問題1: 這是包沖突的問題,jar包中存在兩個沖突的包,可以看到上面的Referenced Libraries中存在asm.jar和asm-2.2.3.jar兩個包,這兩個包沖突了
Linux 系統目錄結構(二)
執行文件 icm sel 系統管理員 修改 tmp win 開始 通用 Linux 系統目錄結構 登錄系統後,在當前命令窗口下輸入命令: ls / 你會看到如下圖所示: 樹狀目錄結構: 以下是對這些目錄的解釋: /bin:bin是Binary的縮寫, 這個目錄存
java設計模式(二)工廠模式
額外 mod 通過反射 pat 擴展 簡單實現 需要 factory actor 工廠模式是最常見的實例化對象的模式,用來替代new操作。采用這種模式創建對象會有一些額外的操作,但他會帶給系統更大的擴展性和更少的修改量。典型的應用spring bean容器。下面簡單實現
Unity3D之Mecanim動畫系統學習筆記(二):模型導入
leg character ... sdk ocs 物體 mat 版本 sset 我們要在Unity3D中使用上模型和動畫,需要經過下面幾個階段的制作,下面以一個人形的模型開發為準來介紹。 模型制作 模型建模(Modelling) 我們的美術在建模時一般會制作一個稱為
設計模式(二)---工廠方法模式
ack cto sys alt 修改 spa 抽象類 .com desc 1、簡介:工廠方法模式是類的創建模式,又叫虛擬構造子模式或是多態性工廠模式,它的實現方式是創建一個工廠接口,將實際創建對象的的工作轉移到工廠子類中,在系統的擴展中,可以在不修改工廠角色的情況下引進新的
3.2《深入理解計算機系統》筆記(二)內存和高速緩存的原理【插圖】
img sram 本質 text ddr rate too 是我 很大的 《深入計算機系統》筆記(一)主要是講解程序的構成、執行和控制。接下來就是運行了。我跳過了“處理器體系結構”和“優化程序性能”,這兩章的筆記繼續往後延遲! 《深入計算機系統》的一個很大的用處
設計模式之設計原則(二)
font 通過 size 模式 span 通信 轉發 設計模式 其他 五: 接口分離原則:不應該強迫程序依賴它們不需要使用的方法。即,一個接口不需要提供太多的行為,一個接口應該只提供一種對外的功能,不應該把所有的操作都封裝到一個接口中。 六: 迪米特原則:一個對象應
用 Spring Boot 實現電商系統 Web API (二)創建多模塊項目
ble jin play 正常 ota autowired ips 功能 bind 大型項目,需要將代碼按不同功能,分成不同模塊,這樣比較好管理和閱讀代碼,也有助於多人協作。 一、項目結構 1.1 模塊說明 項目分成5個模塊,分別如下: 模塊名稱 說明 webapi
linux系統程序安裝(二)yum工具2-yum源管理
內容 centos 備份 hang clean 原生 yum 聯網 系統 繼續我們的yum工具應用之旅,yum工具之所以方便就是因為有方便的在線雲庫,實際工作中我們可能沒辦法鏈接互聯網,或者我們想安裝的程序原生源那麽我們能不能用其他方式應用方便的yum源呢? 一、使用光盤
Linux系統 shell基礎(二)
很多 sts ctrl+ 技術 liunx 名稱 而是 進程 全局變量 一、管道符 管道符:管道符號用於把前一個命令的結果傳遞給另一條命令示例:1、統計一個文件的行數命令:cat /etc/passwd | wc -l2、統計當前文件夾下文件個數命令: ls | wc -l
Linux系統管理初步(二)io、free、ps、netstat命令 編輯中
sha 系統 工具 可能 工作 ued uri per str 10.6 監控io性能10.7 free命令10.8 ps命令10.9 查看網絡狀態10.10 linux下抓包 一、iostat與iotop命令 iostat命令與iotop,命令能夠看出系統磁盤的工作情況,