
FaceBoxes: A CPU Real-time Face Detector with High Accuracy(論文解析)
CPU上的高精度實時人臉檢測器
綜述
人臉識別是計算機視覺和模式識別的基礎問題,過去幾十年取得了長足進步,但是由於計算量較大,在CPU上的實時檢測一直沒有很好的被解決。面臨的主要問題,一是人臉和背景的可變性都太大(種類太多),二是由於人臉的不同尺寸,使得搜尋空間快速上升。
過去的主流方法,一種是基於手動構建的特徵(hand-craft features),這種方法在CPU上速度尚可,但是面對種類繁多的影象變體精確度不足。另一種是基於CNN的方法,精確度足夠,但是在CPU上過於耗時,很難達到實時效果。
本文受Faster-RCNN中RPN、SSD中多尺度技術的影響,提出了一種名為FaceBoxes的人臉檢測器並且可以在CPU上達到實時檢測的效果。網路結構是一個完整的CNN架構,可以實現端到端的訓練,雖然網路結構輕量,但效果突出。
網路結構

faceboxes的三個spotlight:
- 設計RDCL層:加速faceboxes在cpu上至實時處理速度,有三個策略:

- 快速減少feature map尺度:在這個模組中,卷積的滑動步長是很大,屬於比較稀疏的滑動卷積。其中conv1滑動步長為4,使得feature map縮小1/4,conv2使得滑動步長為2,使得feature map縮小1/2,pool1,pool2分別縮小1/2,最終feature map縮小1/32。這樣就使得feature map減小的比較快,速度也就會提升。
- 選擇合適的卷積核尺度:conv1、conv2、所有的pooling操作中,卷積核尺度為7 x 7、5 x 5、3 x 3,作者認為使用大尺度可以獲取更大的感受野,進而獲取更多的上下文資訊;這個需要和1配合著理解,1快速減少了feature map尺度,丟失了很多資訊,2通過更大的卷積核匹配上1中快速下降尺度造成的感受野與feature map尺度不匹配的問題,這樣就達到了一個折中的效果;
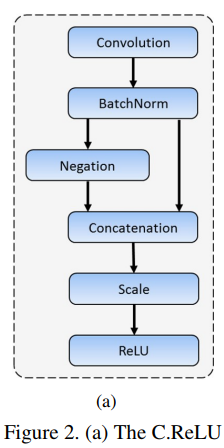
- 使用C.Relu替代Relu,可以減少卷積核數目,但經過C.Relu後卷積核數目(對應的就是feature map changel數目)又可以翻倍;論文中作者在 AlexNet 的模型上做了一個有趣的實驗,發現:低層卷積層中的一些濾波器核存在著負相關程度很高的濾波器核,而層次越高的卷積層,這一現象越不明顯。作者把這一現象稱為pairing phenomenon;這樣在CNN中較低的層,C.ReLU減少一半輸出通道(output channels)的數量,通過簡單的連線相同的輸出和negation使其變成雙倍數量,即達到原來輸出的數量,這使得2倍的速度提升而沒有損失精度;個人理解,減少一半channel數目是根據conv filters數目降低一半得到的,先減少一半channels的feature map,再通過C.ReLU可以擴充一倍的channels數目,這樣就達到了對比原先channel擴充2倍的conv filters的目的;conv filters減少了一倍,自然速度就提升了兩倍;
設[⋅]+=max(⋅,0),則 C.ReLU 定義:CReLU(x)=([x]+,[−x]+), 比如 −3→[0,3] 3→[3,0];
CReLU有二維輸出,而一般的啟用函式只有一維輸出,因此可以將 CReLU 視作一維輸入二維輸出的啟用函式;
RDCL中使用C.ReLU可以顯著提升計算速度,卻不影響精度;具體操作方式如下圖所示:
- 設計MSCL層:豐富感受野和離散化anchor至不同的feature map上,在實現原理上很簡單:
- 豐富感受野,使用了googlenet的inception結構,由於Inception包含多個不同的卷積分支,因此可以進一步使得感受野多樣化

2. 離散化anchor至不同的feature map:複用了SSD的做法,以處理人臉的大尺度變化

- anchor密集取樣策略
- 對淺層feature map(如faceboxes中的inception3)檢測的小尺度目標,其對應anchor(小目標對應的anchor一般預定義比較小,如32 x 32、64 x 64等),做更加密集的anchor取樣,使得小目標anchor的取樣密集與大目標取樣密度一致,這樣可以提升對小目標的召回率;-----CVPR2018 ZCC針對anchor密集取樣給出了更合理的解釋,提出了emo score,從理論上認證了採用anchor密集取樣的優點:https://zhuanlan.zhihu.com/p/35856534
-
SSD和Faster R-CNN此類方法對小目標效果不好,一定程度上是因為小目標所能對應的anchor比較少,導致訓練不足。
下圖是本文網路三個分支預設anchor的大小,以及每個分支對應的spatial stride。
我們可以據此定義anchor密度為(anchor大小 / stride)。 顯然,第一個分支的一些anchor密度不足。這也是為什麼小目標檢測效果不佳的重要原因。

對上圖進行一些說明:inception3分支中有三個anchor尺度,3.3小節提到了anchor取樣密度不一致的情形,如果32 x 32、64 x 64、128 x 128的anchor都使用stride為32的取樣,那麼取樣密度為1、2、4;為了生成相同的取樣密度,將32 x 32、64 x 64改為stride為8、16的取樣密度,那麼原先feature map上一個位置對應到原圖一個anchor,現在feature map上一個位置就對應到原圖4 x 4、2 x 2個anchor(橫、縱座標方向均做密集取樣)。

相關推薦
FaceBoxes: A CPU Real-time Face Detector with High Accuracy(論文解析)
CPU上的高精度實時人臉檢測器 綜述 人臉識別是計算機視覺和模式識別的基礎問題,過去幾十年取得了長足進步,但是由於計算量較大,在CPU上的實時檢測一直沒有很好的被解決。面臨的主要問題,一是人臉和背景的可變性都太大(種類太多),二是由於人臉的不同尺寸,
faced: CPU Real Time face detection using Deep Learning
What is the problem?There are many scenarios where a single class object detection is needed. This means that we want to detect the location of all objects
CPU Real-time Face Detection and Alignment-68 using MTCNN
mtcnn的landmark採用了5點迴歸,博主嘗試了68點迴歸,發現效果不錯! 主要特點:同時完成人臉檢測和特徵點回歸,演算法速度實時! 開源地址:https://github.com/samylee/mtcnn_landmark68(歡迎star和fork) 1
[譯] Perceptual Losses for Real-Time Style Transfer and Super-Resolution(Stanford University)
轉載地址:http://www.jianshu.com/p/b728752a70e9 Abstract 摘要:我們考慮的影象轉換的問題,即將一個輸入影象變換成一個輸出影象。最近熱門的影象轉換的方法通常是訓練前饋卷積神經網路,將輸出影象與原本影象的逐畫素差距作為損失
論文閱讀筆記(六)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
采樣 分享 最終 產生 pre 運算 減少 att 我們 作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian SunSPPnet、Fast R-CNN等目標檢測算法已經大幅降低了目標檢測網絡的運行時間。可是盡管如此,仍然
【Faster RCNN】《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
NIPS-2015 NIPS,全稱神經資訊處理系統大會(Conference and Workshop on Neural Information Processing Systems),是一個關於機器學習和計算神經科學的國際會議。該會議固定在每年的12月舉行
Building real-time dashboard applications with Apache Flink, Elasticsearch, and Kibana
https://www.elastic.co/cn/blog/building-real-time-dashboard-applications-with-apache-flink-elasticsearch-and-kibana Fabian Hue
論文閱讀筆記二十六:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
論文源址:https://arxiv.org/abs/1506.01497 tensorflow程式碼:https://github.com/endernewton/tf-faster-rcnn 摘要 目標檢測依賴於區域proposals演算法對目標的位置進
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Abstract SPPnet和Fast R-CNN雖然減少了演算法執行時間,但region proposal仍然是限制演算法速度的瓶頸。而Faster R-CNN提出了Region Proposal Network (RPN),該網路基於卷積特徵預測每個位置是否為物體以及
Edge Computing Application: Real-Time Face Recognition Based on Cloudlet
A mobile-cloud architecture provides a practical platform for performing face recognition on a mobile device. Firstly, even though
【論文筆記】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
寫在前面: 我看的paper大多為Computer Vision、Deep Learning相關的paper,現在基本也處於入門階段,一些理解可能不太正確。說到底,小女子才疏學淺,如果有錯
【筆記】Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
論文程式碼:重要:訓練檔案.prototxt說明:http://blog.csdn.net/Seven_year_Promise/article/details/60954553從RCNN到fast R
經典計算機視覺論文筆記——《Robust Real-Time Face Detection》
第一次讀這篇傳奇之作大概是九年前了,也就是2007年,而那時距論文正式發表(2004年)也已經有四年之久了。現在讀來,一些想法,在深度學習大行其道的今天仍然具有借鑑意義,讓人敬佩不已。 VJ人臉檢測器應該是歷史上第一個成功商業應用的實時人臉檢
[論文學習]《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 》
faster R-CNN的主要貢獻 提出了 region proposal network(RPN),通過該網路我們可以將提取region proposal的過程也納入到深度學習的過程之中。這樣做既增加了Accuracy,由降低了耗時。之所以說增加Accura
【翻譯】Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
摘要 目前最先進的目標檢測網路需要先用區域建議演算法推測目標位置,像SPPnet[7]和Fast R-CNN[5]這些網路已經減少了檢測網路的執行時間,這時計算區域建議就成了瓶頸問題。本文中,我們介紹一種區域建議網路(Region Proposal Network, R
行人檢測論文筆記:Robust Real-Time Face Detection
知識點 傅立葉變換的一個推論: 一個時域下的複雜訊號函式可以分解成多個簡單訊號函式的和,然後對各個子訊號函式做傅立葉變換並再次求和,就求出了原訊號的傅立葉變換。 卷積定理(Convolution Theorem):訊號f和訊號g的卷積的傅立葉變換
魯棒的實時人臉檢測:Robust Real-Time Face Detection
2.2 特徵討論 矩形特徵較其替代品是有些原始的,如可控濾波器(Freeman和 Adelson,1991年,Greenspan 等人,1994年)。可控波濾器,及其相關濾波器,對於邊界的詳細分析,影象壓縮,紋理分析是很好的。然而矩形特徵對邊緣,條狀和其他簡單的影象結構的表示也是敏感的,不過相當
10年後再看Robust Real-Time Face Detection(一)
這篇論文是人臉檢測上的經典之作。 作者是PAUL VIOLA。相較於其他的人臉檢測演算法, 該篇論文中提到的演算法的主要有點就是在保證較高的人臉檢測率的前提下, 實現了超高的檢測速度。 真正做到了實時性(Real Time), 當之無愧。 可以說之前的各種人臉檢測演算法均無
A 3D Real Time Fluid Solver Demo (三維實時流體解算器)
最近對流體模擬(Fluid Simulation)很感興趣,參考Jos Stam的paper:Real-Time Fluid Dynamics for Games,擴充套件其2D solver,做了個簡單的3D fluid solver,模擬簡單的流體。Demo以及原始碼在這裡. 大話 實時流體模擬本是計算
10年後再看Robust Real-Time Face Detection(二) 之學習分類函式
給定我們一個特徵集合, 一個訓練樣本集(也就是一幅幅樣本影象。 影象可能是有人臉的影象(稱為positive images), 影象也可能不含人臉的影象(negative images))。 那麼我們的任務就是採用機器學習的演算法學習一個分類函式。一旦學習到了這個函式, 我