
【機器學習】神經網路及BP推導
阿新 • • 發佈:2019-01-12
1 前向傳播
這裡的推導都用矩陣和向量的形式,計算單個變數寫起來太麻煩。矩陣、向量求導可參見上面參考的部落格,個人覺得解釋得很直接很好。
前向傳播每一層的計算如下:
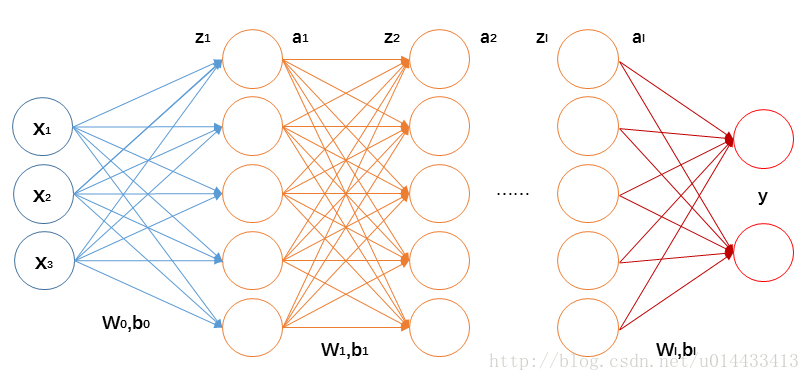
2 反向傳播
為了得到好的模型,我們要更新引數
我們將神經網路的損失函式記為
之後,就要計算
反向傳播之所以和正向傳播這麼對比著說,是因為反向傳播也是一層一層地計算。首先看最後一層(假設最後一層沒有啟用):
我們記:
通過(1.1)和(1.2)我們可以得出:
將(2.3)-(2.5)代入(2.1)、(2.2)得:
下面我們看倒數第二層: