
從頭實現一個深度學習對話系統--Seq-to-Seq模型詳解
上一篇文章已經介紹了幾篇關於Seq-to-Seq模型的論文和應用,這裡就主要從具體的模型細節、公式推導、結構圖以及變形等幾個方向詳細介紹一下Seq-to-Seq模型。這裡我們主要從下面幾個層次來進行介紹:
- Seq-to-Seq框架1
- Seq-to-Seq框架2
- Seq-to-Seq with Attention(NMT)
- Seq-to-Seq with Attention各種變形
- Seq-to-Seq with Beam-Search
Seq-to-Seq框架1

特點是Encoder階段將整個source序列編碼成一個固定維度的向量C(也就是RNN最終的隱藏狀態hT),C = f(x1, x2,…,xT),f就是各種RNN模型。並認為C中儲存了source序列的資訊,將其傳入Decoder階段即可,在每次進行decode時,仍然使用RNN神經元進行處理(下面公式中的f函式),不過輸入包括前一時刻輸出yt-1、前一時刻隱層狀態ht-1、輸入編碼向量C三個向量,也就是解碼時同時會考慮前一時刻的輸出和source序列兩方面的資訊,如下圖所示。
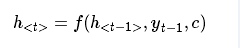
有了ht之後在計算該時刻的輸出值yt,這裡計算一個條件概率分佈,計算出當前情況下target vocab中每個詞所對應的概率,這裡往往需要一個額外的Projection層,因為RNN的輸出維度與vocab維度不同,所以需要經過一個矩陣進行對映(後面介紹程式碼的時候會講到)。yt的計算會使用ht、yt-1、C三個向量。g函式往往是一個softmax函式,用於計算歸一化的概率值。
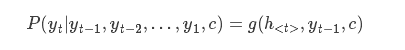
Seq-to-Seq框架2

與上面模型最大的區別在於其source編碼後的向量C直接作為Decoder階段RNN的初始化state,而不是在每次decode時都作為RNN cell的輸入。此外,decode時RNN的輸入是目標值,而不是前一時刻的輸出。首先看一下編碼階段:

就是簡單的RNN模型,每個詞經過RNN之後都會編碼為hidden state(e0,e1,e2),並且source序列的編碼向量e就是最終的hidden state e2。接下來再看一下解碼階段:

e向量僅作為RNN的初始化狀態傳入decode模型。接下來就是標準的迴圈神經網路,每一時刻輸入都是前一時刻的正確label。直到最終輸入符號截止滾動。
Seq-to-Seq with Attention(NMT)

前面兩個模型都是將source序列編碼成一個固定維度的向量,但是這樣做對於長序列將會丟失很多資訊導致效果不好,所以作者提出將encoder階段所有的隱層狀態儲存在一個列表當中,然後接下來decode的時候,根據前一時刻狀態st-1去計算T個隱層狀態與其相關程度,在進行加權求和得到編碼資訊ci,也就是說每個解碼時刻的c向量都是不一樣的,會根據target與source之間的相關程度進行權重調整和計算。編碼過程就不再贅述了,主要看一下解碼過程的流程:
1,計算h1~hT各個隱層向量與st-1之間的相關程度,並進行softmax歸一化操作得到每個隱層向量的權重aij:


eij就表示第i個target與第j個隱層向量hj之間的相關性,可以通過一個MLP神經網路進行計算,在上面示意圖中沒有顯示出來。得到eij之後,將其傳入softmax函式我們就可以獲得歸一化的權重值aij。
2,對h1~hT進行加權求和得到此次解碼所對應的source編碼的向量ci:

到這裡我們可以參考下圖進行理解(其實這裡有一點不同,因為下面這個圖並未引入st-1這個向量,而是僅考慮了h1~hT),從圖中可以看出T個隱層向量經過左上角的MLP+softmax神經網路之後就變成了T個權重值,然後對T個向量按照該權重值進行加權求和即可得到Ci:

針對這個模型我們也可以參考下圖進行理解,每個aij都是用zi和hj之間計算得到的,這個圖是分開來講每個向量之間的計算,而上面那個圖是將其整體作為一個矩陣進行考慮,直接傳入MLP神經網路即可。

3,有了ci之後,就和前面兩個Seq-to-Seq模型一樣了,我們根據ci進行解碼即可,同樣是先計算st,在計算yt,兩個公式如下所示:

這裡的Attention機制採用的是Soft Attentin(也就是對所有的h向量都有分配權重),可以將其理解為對齊模型,作用是匹配target與source之間的對應關係。從這個角度上來講aij可以理解為yi是由xj翻譯過來的概率。所以這個權重值可以很好的對模型進行視覺化,以瞭解模型工作的機理和效果。
Seq-to-Seq with Attention各種變形
這是我們要介紹的第四個Seq-to-Seq模型,來自於論文“Effective Approaches to Attention-based Neural Machine Translation”,目前引用量530+。這篇論文提出了兩種Seq-to-Seq模型分別是global Attention和local Attention,下面分別進行介紹:
1,global Attention,這種模型跟上面的思路差不多,也是採用soft Attention的機制,對上面模型進行了稍微的修改,模型結構圖如下所示:

從上圖可以看出,原理上與NMT區別不大,只是aij計算方法稍有區別,這裡的score函式從上面的神經網路變成了下面三種選擇,包括內積、general、concat。結果表明general效果比較好。如下圖所示:

為了顯示出aij的計算細節,我們可以參考下圖進行理解,其中的f函式就是上面提到的score評分函式:

因為與NMT模型差別很小,所以不在擴充套件介紹。下面看看local Attention。
2,local Attention,目前存在兩種Attention方式soft Attention和hard Attention。上面提到的global模型屬於soft Attention,這種方法的缺點是每次decode時都要計算所有的向量,導致計算複雜度較高,而且很容易可以想到,其實有些source跟本次decode根本沒有任何關係,所以計算他們之間的相似度有些多餘;除此之外,當source序列較長時,這種方法的效果也會有所下降。而hard Attention,每次僅選擇一個相關的source進行計算,這種方法的缺點是不可微,沒有辦法進行反向傳播,只能藉助強化學習等手段進行訓練。這部分內容可以參考論文“Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”。所以為了融合兩種方法,作者提出了一種local Attention的機制,每次只選擇一部分source進行計算。這樣既可以減少計算量,又可微,效果也更好。接下來看一下其原理:

思路就是先根據st找到source中所對應的視窗中心位置,然後取出該視窗內的source所對應的h隱層向量,在進行求aij並加權求和得到ci向量。這個過程中最重要的就是如何確定st所對應的source的中心位置,論文中提出了兩種方法:
- monotonic alignment:直接選擇source序列中的第t個作為中心pt,然後向兩側取視窗大小個詞;
- predictive alignment:使用下面的公式決定pt值的大小,將ht經過一個啟用函式tanh和sigmod兩個函式之後變成0~1,再乘以S(source序列長度)就變成0~S,也就是我們想要的原序列所對應的中心位置pt,取出視窗大小個隱層,在進行加權求和。這裡權重乘以了一個高斯分佈,目的是讓靠近中心pt的詞的權重更大一點,讓aij形成一種鍾型分佈,如下圖所示,原本的aij再乘以高斯分佈之後,相應的aij值發生變化,導致靠近中心的aij增加,兩側的減小。



3,為了讓模型能夠學習到更多的資訊,作者又提出Input-feeding的方法,也就是將計算出的ht傳遞到下一時刻的輸入中,如下圖所示:

Seq-to-Seq with Beam-Search
上面講的幾種Seq-to-Seq模型都是從模型結構上進行的改進,也就說為了從訓練的層面上改善模型的效果,但這裡要介紹的beam-search是在測試的時候才用到的技術。我們先來說一下一般的方法,也就是greedy search,在進行解碼的時候,每一步都選擇概率最大的那個詞作為輸出,然後再將這個詞作為下一解碼時刻的輸入傳遞進去。以此類推,直到輸出符號為止,我們最終會獲得一個概率最大的序列當做是解碼的輸出。但是這麼做的缺點就是,某一步的錯誤輸出可能會導致後面整個輸出序列都發生錯誤,那麼改進的方案就是beam-search,思路也很簡單,就是每次都選擇概率最大的k個詞(beam size)作為輸出,並在下一時刻傳入RNN進行解碼,以此類推。
舉個例子來說明一下,假設我們翻譯時的vocab就是A,B,C三個單詞,beam size取2,。然後第一次解碼時對應概率分別是[0.2,0.5,0.3],於是我們就選擇概率最大的兩個B,C作為候選分別傳入下一個解碼時刻,B的輸出概率分別是[0.7, 0.2, 0.1],C的輸出概率分別是[0.3, 0.5, 0.2],仍然分別去概率最大的兩個輸出,於是我們得到下面四個序列:BA:0.5*0.7=0.35, BB:0.5*0.2=0.1, CB:0.3*0.5=0.15, CA:0.3*0.3=0.09,取概率最大的兩個序列就是BA和CB。再繼續做下一步。。。接下來每次都會生成K^2個序列,取概率最大的K個最為候選進行下一輪解碼輸入即可。
這樣做的好處是可以通過增加搜尋範圍來保證一定的正確率。比如說我們最終得到兩個序列ABCCBA和BACBC,雖然第一個步驟中A的概率大於B,但最終BACBC的概率比ABCCBA要大,於是BACBC就作為最終輸出序列而且也恰恰是正確答案。參考文獻2中提到,beam size等於2時效果就已經不錯了,到10以上就不會再有很大提升。
參考文獻和部落格:
相關推薦
從頭實現一個深度學習對話系統--Seq-to-Seq模型詳解
上一篇文章已經介紹了幾篇關於Seq-to-Seq模型的論文和應用,這裡就主要從具體的模型細節、公式推導、結構圖以及變形等幾個方向詳細介紹一下Seq-to-Seq模型。這裡我們主要從下面幾個層次來進行介紹: Seq-to-Seq框架1 Seq-to-Seq框架
從頭實現一個深度學習的對話系統--tf.contrib.seq2seq API介紹
這篇文章就簡單從原始碼的角度上分析一下tf.contrib.seq2seq下提供的API,首先來講這個資料夾下面的幾個檔案和函式上篇文章中都已經提到而且介紹了他們之間的關係和如何使用,如果對原始碼不感興趣就不用看下去了~~ BasicDecoder和dyn
深度學習對話系統理論--資料集和評價指標介紹
對話系統常用評價指標 當前對話系統之所以還沒有取得突破性的進展,很大程度上是因為沒有一個可以準確表示回答效果好壞的評價標準。對話系統中大都使用機器翻譯、摘要生成領域提出來的評價指標,但是很明顯對話系統的場景和需求與他們是存在差別的,這也是當前模型效果不是很好的原因之一。從對
深度學習對話系統理論篇--資料集和評價指標介紹
對話系統常用評價指標 當前對話系統之所以還沒有取得突破性的進展,很大程度上是因為沒有一個可以準確表示回答效果好壞的評價標準。對話系統中大都使用機器翻譯、摘要生成領域提出來的評價指標,但是很明顯對話系統的場景和需求與他們是存在差別的,這也是當前模型效果不是很好的
深度學習啟用函式sigmoid,tanh,ReLU,softma詳解
啟用函式sigmoid,tanh,ReLU,softma詳解 [轉載地址:](https://blog.csdn.net/u011684265/article/details/78039280) # **啟用函式sigmoid,tanh,ReLU,softmax**
【深度學習】GAN生成對抗網路原理詳解(1)
一個 GAN 框架,最少(但不限於)擁有兩個組成部分,一個是生成模型 G,一個是判別模型 D。在訓練過程中,會把生成模型生成的樣本和真實樣本隨機地傳送一張(或者一個 batch)給判別模型 D。判別模型 D 的目標是儘可能正確地識別出真實樣本(輸出為“真”,或者1),和儘可能
深度學習之卷積神經網路原理詳解(一)
初探CNN卷積神經網路 1、概述 典型的深度學習模型就是很深層的神經網路,包含多個隱含層,多隱層的神經網路很難直接使用BP演算法進行直接訓練,因為反向傳播誤差時往往會發散,很難收斂 CNN節省訓練開銷的方式是權共享weight sharing,讓一組神經元
【深度學習】Torch卷積層原始碼詳解
本文以前向傳播為例,詳細分析Torch的nn包中,SpatialConvolution函式的實現方式。 在分析原始檔時,同時給出了github上的連結以及安裝後的檔案位置。 初始化 定義一個卷積層需要如下輸入引數 nInputPlane\nOutpu
SIGAI 4P計劃【2.0】免費來襲,給你一個深度學習python的機會
SIGAI 4P計劃一期啟動以來,收到了小夥伴們的熱烈反響。共1017人加入計劃學習,其中70%學生使用者,28%企業使用者。不少小夥伴希望加入,但由於人員和管理的限制,一期不再開放。 但是,SIGAI怎麼能辜負同學們一顆想天天向上的好學之心呢?在大家的殷殷期待下,SIGAI總結一期4P計劃經驗
Vue實現一個學生資訊錄入系統,實現錄入和刪除
效果如下: 程式碼如下: 1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title&l
推薦一個深度學習應用於圖形學的網站
2018年12月4日-7日,全亞洲最大的計算機圖形與互動技術會議與展會——SIGGRAPH Asia 2018大會在日本東京隆重舉行。作為計算機圖形學頂級會議,SIGGRAPH大會邀請了國際上在影像技術方面有建樹的學者、技術名流大咖及高新技術企業共同研討交流,展示最先進的圖形學技術。來自英國倫敦大學
從頭實現一個編譯器(基於COOL語言)
前言 以下很多網站可能需要翻牆。 最近學校開了編譯原理的課程,為了更好的理解,我在網上找到了一門由Alex Aiken大師開設的一門Compilers的課程,有視訊,PPT,關鍵是還有程式碼實踐,也希望自己可以堅持做下去。 大概講一下,COOL這門語言的全名叫c
使用Python科學計算實現一個簡單的推薦系統
許多人把推薦系統視為一個神祕的存在,他們覺得推薦系統似乎知道我們的想法是什麼。Netflix向我們推薦電影,還有亞馬遜向我們推薦該買什麼樣的商品。推薦系統從早期發展到現在,已經得到了很大的改進和完善,以不斷提高使用者體驗。儘管推薦系統中許多都是非常複雜的系統,但其背後的基本思想依然十分簡單。
YouTube 深度學習推薦系統的十大工程問題
這篇文章主要介紹了 YouTube 深度學習系統論文中的十個工程問題,為了方便進行問題定位,我們還是簡單介紹一下背景知識,簡單回顧一下 Deep Neural Networks for YouTube Recommendations中介紹的 YouTube 深度學習推薦系統的框架。(更詳細的資訊,請參見重讀
TensorFlow實現經典深度學習網路(5):TensorFlow實現自然語言處理基礎網路Word2Vec
TensorFlow實現經典深度學習網路(5):TensorFlow實現自然語言處理 基礎網路Word2Vec 迴圈神經網路RNN是在自然語言處理NLP領域最常使用的神經網路結構,和卷積神經網路在影象識別領域的地位相似,影響深遠。而Word2Vec則是將語
推薦系統遇上深度學習(五)--Deep&Cross Network模型理論和實踐
1、原理Deep&Cross Network模型我們下面將簡稱DCN模型:一個DCN模型從嵌入和堆積層開始,接著是一個交叉網路和一個與之平行的深度網路,之後是最後的組合層,它結合了兩個網路的輸出。完整的網路模型如圖:嵌入和堆疊層我們考慮具有離散和連續特徵的輸入資料。在網路規模推薦系統中,如CTR預測,
PyQt實現一個簡單的License系統(二)
本文接著上一篇繼續講解“PyQt實現一個簡單的License系統”,主要包括: 3)如何用python建立一個GUI。 4)python如何調C DLL庫。 5)ctypes中型別處理。 上一篇文章只是簡單的將ui檔案轉換為py檔案,並執行,生成了一
keras快速上手-基於python的深度學習實踐-基於索引的深度學習對話模型-源代碼
spro pic ram 分析 pyplot 格式 批量 repr odi 該章的源代碼已經調通,如下, 先記錄下來,再慢慢理解 #!/usr/bin/env python # coding: utf-8 # In[1]: import pandas as pd im
構建無處不在的深度學習部署系統
《SDCC 2017 人工智慧技術實戰線上峰會》學習筆記 劉文志 深度學習部署平臺特點: 深度學習的兩個方面: 部署、訓練 面臨的挑戰:現代深度學習部署平臺要求: 支援多種不同的架構不同廠家 不同硬體 不同程式語言 不同終端:伺服器、桌