
elasticsearch核心知識---53.圖解剖析document寫入原理以及Segement的合併
圖解ES 寫入流程,分成三個部分,最終版本圖解才是最終版的ES的寫入流程。
##################################第一部分#########################################
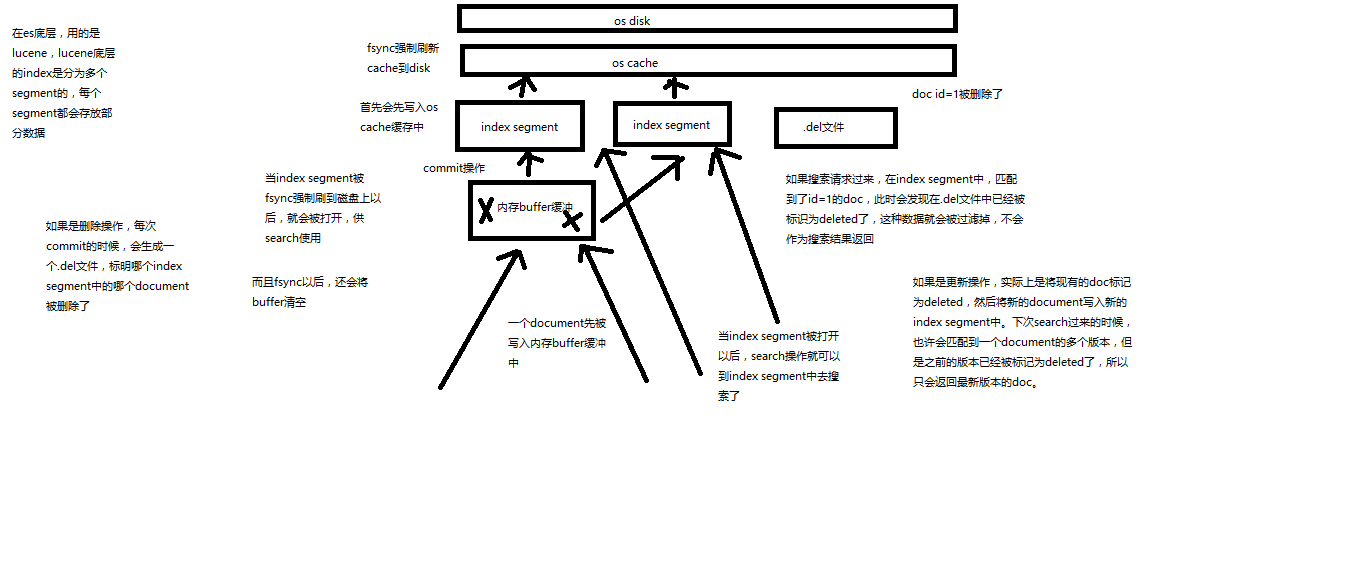
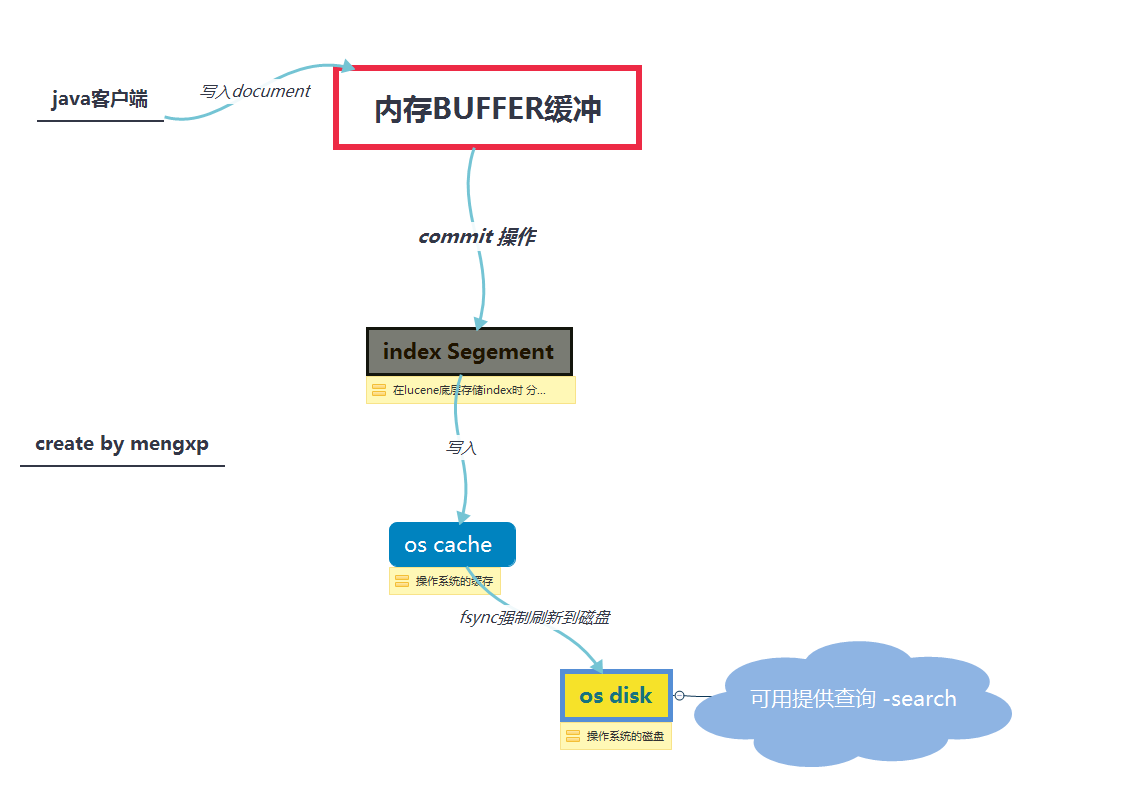
Segment:lucene底層進行儲存時,將一個index分為多個Segement。當Segement被打開了,才可以提供search
buffer:資料會先寫入記憶體buffer中。
commit:達到buffer的閥值時,會將記憶體buffer的資料寫入 os cache --->fsync os disk...
(1)資料寫入buffer (2)commit point (3)buffer中的資料寫入新的index segment (4)等待在os cache中的index segment被fsync強制刷到磁碟上 (5)新的index sgement被開啟,供search使用 (6)buffer被清空 每次commit point時,會有一個.del檔案,標記了哪些segment中的哪些document被標記為deleted了 搜尋的時候,會依次查詢所有的segment,從舊的到新的,比如被修改過的document,在舊的segment中,會標記為deleted,在新的segment中會有其新的資料
##################################第二部分###########################################
現有流程的問題,每次都必須等待fsync將segment刷入磁碟,才能將segment開啟供search使用,這樣的話,從一個document寫入,到它可以被搜尋,可能會超過1分鐘!!!這就不是近實時的搜尋了!!!主要瓶頸在於fsync實際發生磁碟IO寫資料進磁碟,是很耗時的。
寫入流程別改進如下:
(1)資料寫入buffer
(2)每隔一定時間,buffer中的資料被寫入segment檔案,但是先寫入os cache
(3)只要segment寫入os cache,那就直接開啟供search使用,不立即執行commit
資料寫入os cache,並被開啟供搜尋的過程,叫做refresh,預設是每隔1秒refresh一次。也就是說,每隔一秒就會將buffer中的資料寫入一個新的index segment file,先寫入os cache中。所以,es是近實時的,資料寫入到可以被搜尋,預設是1秒。
POST /my_index/_refresh,可以手動refresh,一般不需要手動執行。
比如說,我們現在的時效性要求,比較低,只要求一條資料寫入es,一分鐘以後才讓我們搜尋到就可以了,那麼就可以調整refresh interval
PUT /my_index{
"settings": {
"refresh_interval": "30s" 這個引數時設定 refresh的過程。
}
}

#############################第三部分 ES的真實的寫入流程#################################
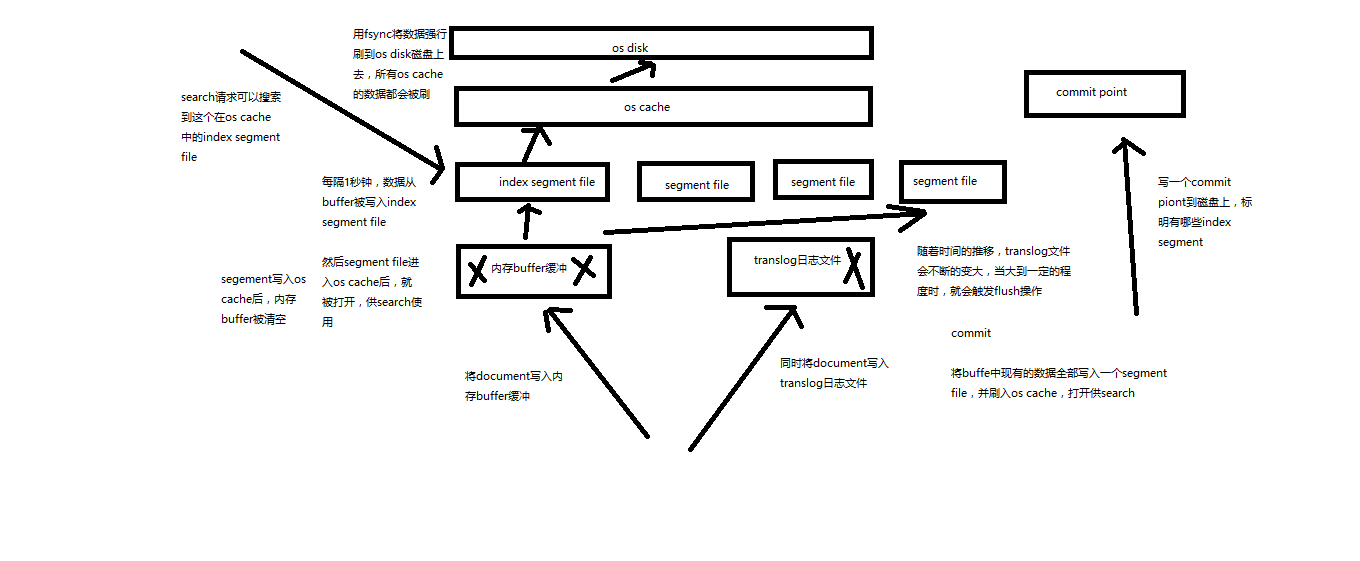
(1)資料寫入buffer緩衝和translog日誌檔案
(2)每隔一秒鐘,buffer中的資料被寫入新的segment file,並進入os cache,此時segment被開啟並供search使用
(3)buffer被清空
(4)重複1~3,新的segment不斷新增,buffer不斷被清空,而translog中的資料不斷累加
(5)當translog長度達到一定程度的時候,commit操作發生
(5-1)buffer中的所有資料寫入一個新的segment,並寫入os cache,開啟供使用
(5-2)buffer被清空
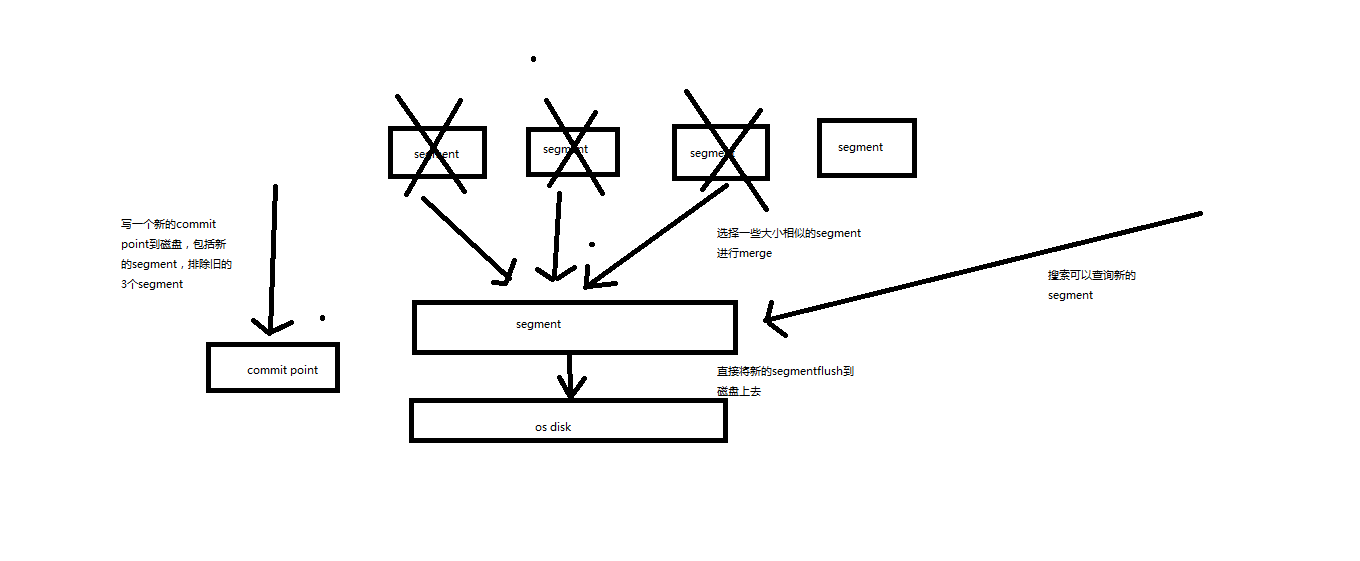
(5-3)一個commit ponit被寫入磁碟,標明瞭所有的index segment
(5-4)filesystem cache中的所有index segment file快取資料,被fsync強行刷到磁碟上
(5-5)現有的translog被清空,建立一個新的translog
基於translog和commit point,如何進行資料恢復
fsync+清空translog,就是flush,預設每隔30分鐘flush一次,或者當translog過大的時候,也會flush
POST /my_index/_flush,一般來說別手動flush,讓它自動執行就可以了
translog,每隔5秒被fsync一次到磁碟上。在一次增刪改操作之後,當fsync在primary shard和replica shard都成功之後,那次增刪改操作才會成功
但是這種在一次增刪改時強行fsync translog可能會導致部分操作比較耗時,也可以允許部分資料丟失,設定非同步fsync translog
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}

相關推薦
elasticsearch核心知識---53.圖解剖析document寫入原理以及Segement的合併
圖解ES 寫入流程,分成三個部分,最終版本圖解才是最終版的ES的寫入流程。##################################第一部分#########################################Segment:lucene底層進行儲存時,
ElasticSearch教程——深入剖析Document寫入原理以及優化操作
ElasticSearch彙總請檢視:ElasticSearch教程——彙總篇 初始寫入流程 (1)資料寫入buffer (2)commit point (3)buffer中的資料寫入新的index segment (4)等待在os cache中的index segment
elasticsearch核心知識--13.圖解Elasticsearch容錯機制:master選舉,replica容錯,資料恢復
1、圖解Elasticsearch容錯機制:master選舉,replica容錯,資料恢復(0)9 shard,3 node#########主要分為如下三步##########################################(1)master node宕機,
elasticsearch核心知識---52.倒排索引組成結構以及實現TF-IDF演算法
首先實現了採用java 簡易的實現TF-IDF演算法package matrixOnto.Ja_9_10_va; import com.google.common.base.Preconditions; import org.nutz.lang.Strings; impo
ElasticSearch最佳入門實踐(六十七)document寫入原理(buffer,segment,commit)
(1)資料寫入buffer (2)commit point (3)buffer中的資料寫入新的index segment (4)等待在os cache中的index segment被fsync強制刷到磁碟上 (5)新的index sgement被開啟,供search使用 (6)b
elasticsearch核心知識--2. Elasticsearch的功能、適用場景以及特點介紹
1、Elasticsearch的功能,幹什麼的2、Elasticsearch的適用場景,能在什麼地方發揮作用3、Elasticsearch的特點,跟其他類似的東西不同的地方在哪裡-------------------------------------------------
elasticsearch核心知識--38.Query DSL搜尋語法和bool多條件查詢
1、一個例子讓你明白什麼是Query DSLGET /_search{ "query": { "match_all": {} }}2、Query DSL的基本語法{ QUERY_NAME: { ARGUMENT: VALUE,
elasticsearch核心知識---49.ES中mapping root object _source _all _store _index關鍵字理解
關於_source _all _store _index 這四個關鍵字 在這篇文章中非常詳細點選開啟連結1.root object就是某個type對應的mapping json,包括了properties,metadata(_id,_source,_type),se
elasticsearch核心知識--30.分頁搜尋以及deep paging效能問題深度理解和es中聚合aggregation的分組可能結果不準確的原因
如何使用es進行分頁搜尋的語法 [size,from]GET /_search?size=10GET /_search?size=10&from=0GET /_search?size=10&from=20GET /test_index/test_type/_
elasticsearch核心知識--46.scroll技術滾動搜尋大量資料以及和FromSize分頁的本質區別和效能
scroll和formsize的區別以及效能比較 可以參考這篇文章 點選開啟連結分頁查詢時基於使用者檢視,scroll時基於批量查詢資料。效能方面 由於scroll時儲存著上一次查詢的快照,類似於查詢的索引位置,所以效能時比fromsize好第一部分:關於scroll搜
elasticsearch核心知識--42.多搜尋條件組合查詢,sort以及explain的用法
分為三部分:第一部分 組合條件查詢GET /website/article/_search { "query": { "bool": { "must": [ { "match": { "ti
elasticsearch核心知識--22.mget批量查詢api以及效能優化
批量查詢的好處就是一條一條的查詢,比如說要查詢100條資料,那麼就要傳送100次網路請求,這個開銷還是很大的如果進行批量查詢的話,查詢100條資料,就只要傳送1次網路請求,網路請求的效能開銷縮減100倍mget的語法(1)一條一條的查詢GET /test_index/test
深入剖析ThreadLocal實現原理以及記憶體洩漏問題
一、概述 在2017京東校園招聘筆試題中遇到了描述ThreadLocal的實現原理和記憶體洩漏的問題,之前看過ThreadLocal的實現原理,但是網上有很多文章將的很亂,其中有很多文章將ThreadLocal與執行緒同步機制混為一談,特別注意的是Thread
ElasticSearch最佳入門實踐(二十八)剖析document資料路由原理
1、document路由到shard上是什麼意思? 我們這段,一個index的資料會被分為多片,每個片都在一個shard中,所以說,一個document存在於一個shard中 當客戶端建立的時候,es此時就需要決定說,這個document存在於那個shard上。 這個過程就稱
elasticsearch(10) es核心:寫入原理
1.document先寫入導記憶體buffer中,同時寫translog日誌,每隔一秒鐘把buffer中的資料刷入index segment file中,index segment file中的資料會立馬進入os cache中,記憶體buffer被清空,此時,segment
Elasticsearch Lucene 資料寫入原理 | ES 核心篇
前言 最近 TL 分享了下 《Elasticsearch基礎整理》https://www.jianshu.com/p/e8226138485d ,蹭著這個機會。寫個小文鞏固下,本文主要講 ES -> Lucene 的底層結構,然後詳細描述新資料寫入 ES 和 Lucene 的流程和原理。這是基礎理論知識
Elasticsearch核心技術(2)--- 基本概念(Index、Type、Document、叢集、節點、分片及副本、倒排索引)
Elasticsearch核心技術(2)--- 基本概念 這篇部落格講到基本概念包括: Index、Type、Document。叢集,節點,分片及副本,倒排索引。 一、Index、Type、Document 1、Index index:索引是文件(Document)的容器,是一類文件的集合。 索引這個詞在
java知識思維圖解
ava java知識 blog -1 logs 技術分享 nbsp http src java知識思維圖解
【匯總】Python 編程核心知識體系
目前 博客 列表 修改 pic http 匯總 -- elf 【匯總】Python 編程核心知識體系 大神著作,源自:https://woaielf.github.io/2017/06/13/python3-all/ 本文主要涵蓋了 Python 編程的核心知識(暫不包括標
struts2學習(2)struts2核心知識
print back exec soft .cn dtd del display .org 一、Struts2 get/set 自動獲取/設置數據 根據上一章。中的源碼繼續。 HelloWorldAction.java中private String name,自動獲取/設置