
Elasticsearch核心技術(2)--- 基本概念(Index、Type、Document、叢集、節點、分片及副本、倒排索引)
Elasticsearch核心技術(2)--- 基本概念
這篇部落格講到基本概念包括: Index、Type、Document。叢集,節點,分片及副本,倒排索引。
一、Index、Type、Document
1、Index
index:索引是文件(Document)的容器,是一類文件的集合。
索引這個詞在 ElasticSearch 會有三種意思:
1)、索引(名詞)
類比傳統的關係型資料庫領域來說,索引相當於SQL中的一個數據庫(Database)。索引由其名稱(必須為全小寫字元)進行標識。
2)、索引(動詞)
儲存一個文件到索引(名詞)的過程。這非常類似於SQL語句中的 INSERT關鍵詞。如果該文件已存在時那就相當於資料庫的UPDATE。
3)、倒排索引
關係型資料庫通過增加一個B+樹索引到指定的列上,以便提升資料檢索速度。索引ElasticSearch 使用了一個叫做 倒排索引 的結構來達到相同的目的。
2、Type
Type 可以理解成關係資料庫中Table。
之前的版本中,索引和文件中間還有個型別的概念,每個索引下可以建立多個型別,文件儲存時需要指定index和type。從6.0.0開始單個索引中只能有一個型別,
7.0.0以後將將不建議使用,8.0.0 以後完全不支援。
棄用該概念的原因:
我們雖然可以通俗的去理解Index比作 SQL 的 Database,Type比作SQL的Table。但這並不準確,因為如果在SQL中,Table 之前相互獨立,同名的欄位在兩個表中毫無關係。
但是在ES中,同一個Index 下不同的 Type 如果有同名的欄位,他們會被 Luecence 當作同一個欄位 ,並且他們的定義必須相同。所以我覺得Index現在更像一個表,
而Type欄位並沒有多少意義。目前Type已經被Deprecated,在7.0開始,一個索引只能建一個Type為_doc
3、Document
Document Index 裡面單條的記錄稱為Document(文件)。等同於關係型資料庫表中的行。
我們來看下一個文件的源資料
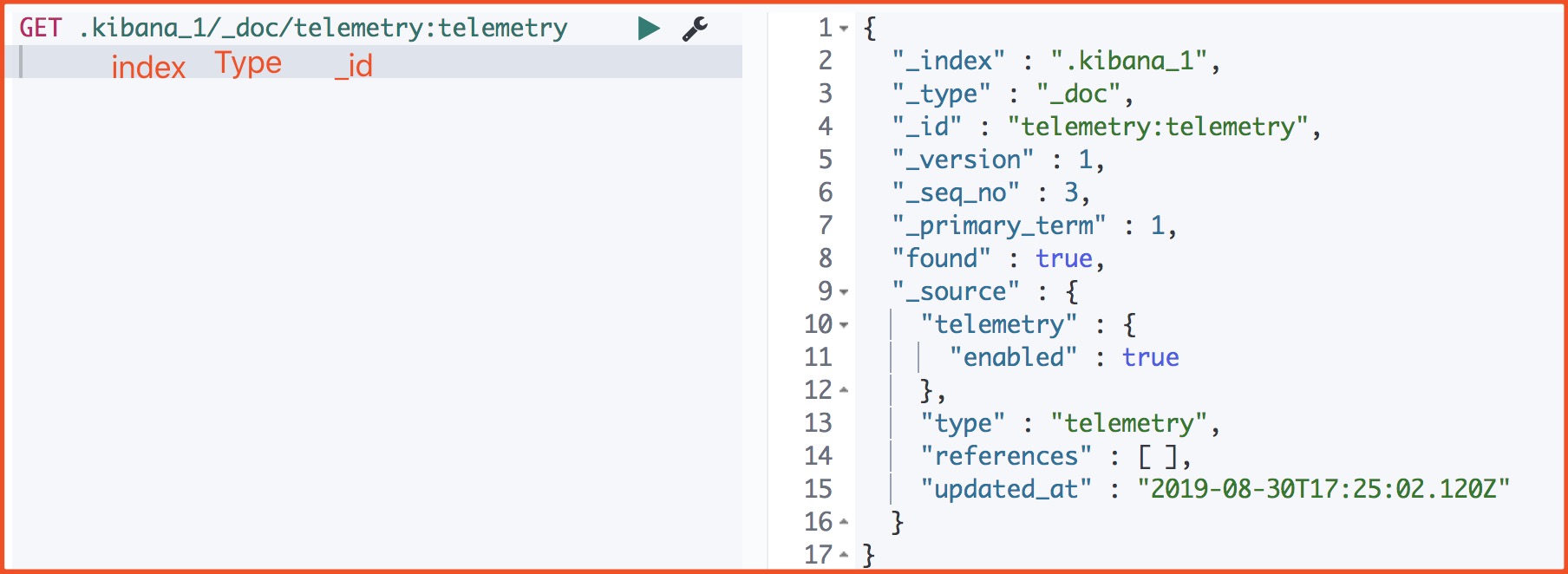
_index 文件所屬索引名稱。
_type 文件所屬型別名。
_id Doc的主鍵。在寫入的時候,可以指定該Doc的ID值,如果不指定,則系統自動生成一個唯一的UUID值。
_version 文件的版本資訊。Elasticsearch通過使用version來保證對文件的變更能以正確的順序執行,避免亂序造成的資料丟失。
_seq_no 嚴格遞增的順序號,每個文件一個,Shard級別嚴格遞增,保證後寫入的Doc的_seq_no大於先寫入的Doc的_seq_no。
primary_term primary_term也和_seq_no一樣是一個整數,每當Primary Shard發生重新分配時,比如重啟,Primary選舉等,_primary_term會遞增1
found 查詢的ID正確那麼ture, 如果 Id 不正確,就查不到資料,found欄位就是false。
_source 文件的原始JSON資料。
二、叢集,節點,分片及副本
1、叢集
ElasticSearch叢集實際上是一個分散式系統,它需要具備兩個特性:
1)高可用性
a)服務可用性:允許有節點停止服務;
b)資料可用性:部分節點丟失,不會丟失資料;
2)可擴充套件性
隨著請求量的不斷提升,資料量的不斷增長,系統可以將資料分佈到其他節點,實現水平擴充套件;
一個叢集中可以有一個或者多個節點;
叢集健康值
green:所有主要分片和複製分片都可用yellow:所有主要分片可用,但不是所有複製分片都可用red:不是所有的主要分片都可用
當叢集狀態為 red,它仍然正常提供服務,它會在現有存活分片中執行請求,我們需要儘快修復故障分片,防止查詢資料的丟失;2、節點(Node)
1)節點是什麼?
a)節點是一個ElasticSearch的例項,其本質就是一個Java程序;
b)一臺機器上可以執行多個ElasticSearch例項,但是建議在生產環境中一臺機器上只執行一個ElasticSearch例項;
Node 是組成叢集的一個單獨的伺服器,用於儲存資料並提供叢集的搜尋和索引功能。與叢集一樣,節點也有一個唯一名字,預設在節點啟動時會生成一個uuid作為節點名,
該名字也可以手動指定。單個叢集可以由任意數量的節點組成。如果只啟動了一個節點,則會形成一個單節點的叢集。
3、分片
Primary Shard(主分片)
ES中的shard用來解決節點的容量上限問題,,通過主分片,可以將資料分佈到叢集內的所有節點之上。
它們之間關係
一個節點對應一個ES例項;
一個節點可以有多個index(索引);
一個index可以有多個shard(分片);
一個分片是一個lucene index(此處的index是lucene自己的概念,與ES的index不是一回事);主分片數是在索引建立時指定,後續不允許修改,除非Reindex
一個索引中的資料儲存在多個分片中(預設為一個),相當於水平分表。一個分片便是一個Lucene 的例項,它本身就是一個完整的搜尋引擎。我們的文件被儲存和索引到分片內,
但是應用程式是直接與索引而不是與分片進行互動。
Replica Shard(副本)
副本有兩個重要作用:
1、服務高可用:由於資料只有一份,如果一個node掛了,那存在上面的資料就都丟了,有了replicas,只要不是儲存這條資料的node全掛了,資料就不會丟。因此分片副本不會與
主分片分配到同一個節點;
2、擴充套件效能:通過在所有replicas上並行搜尋提高搜尋效能.由於replicas上的資料是近實時的(near realtime),因此所有replicas都能提供搜尋功能,通過設定合理的replicas
數量可以極高的提高搜尋吞吐量
分片的設定
對於生產環境中分片的設定,需要提前做好容量規劃,因為主分片數是在索引建立時預先設定的,後續無法修改。
分片數設定過小
導致後續無法增加節點進行水平擴充套件。
導致分片的資料量太大,資料在重新分配時耗時;
分片數設定過大
影響搜尋結果的相關性打分,影響統計結果的準確性;
單個節點上過多的分片,會導致資源浪費,同時也會影響效能;
三、倒排索引
ES的搜尋功能是基於lucene,而lucene搜尋的基本原理就是倒敘索引,倒序排序的結果跟分詞的型別有關。
舉例
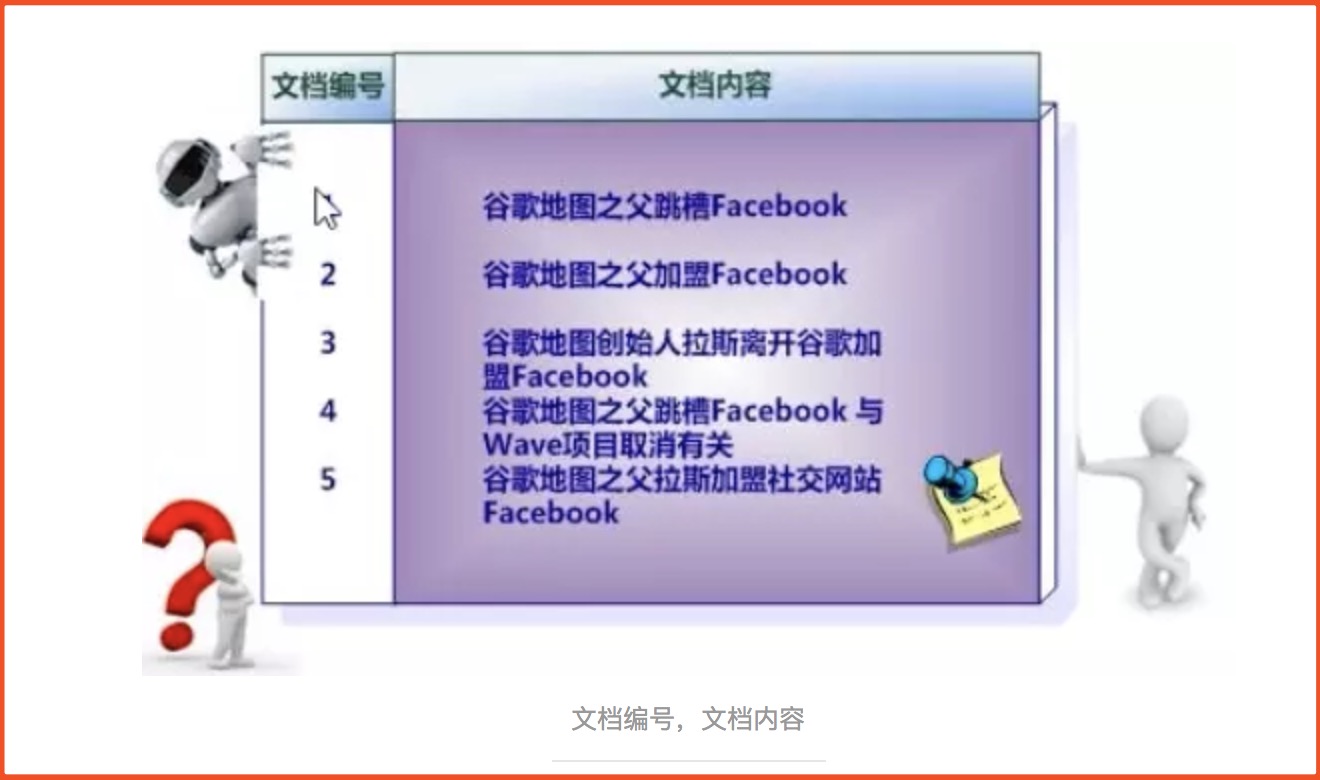
1、假設文件集合包含五個文件,毎個文件內容如圖所示,在圖中最左端一欄是每個文件對應的文擋編號。
如圖(盜圖)
2、首先要用分詞系統將文擋自動切分成單詞序列,記錄下哪些文擋包含這個單詞,在如此處理結束後,我們可以得到最簡單的倒排索引。
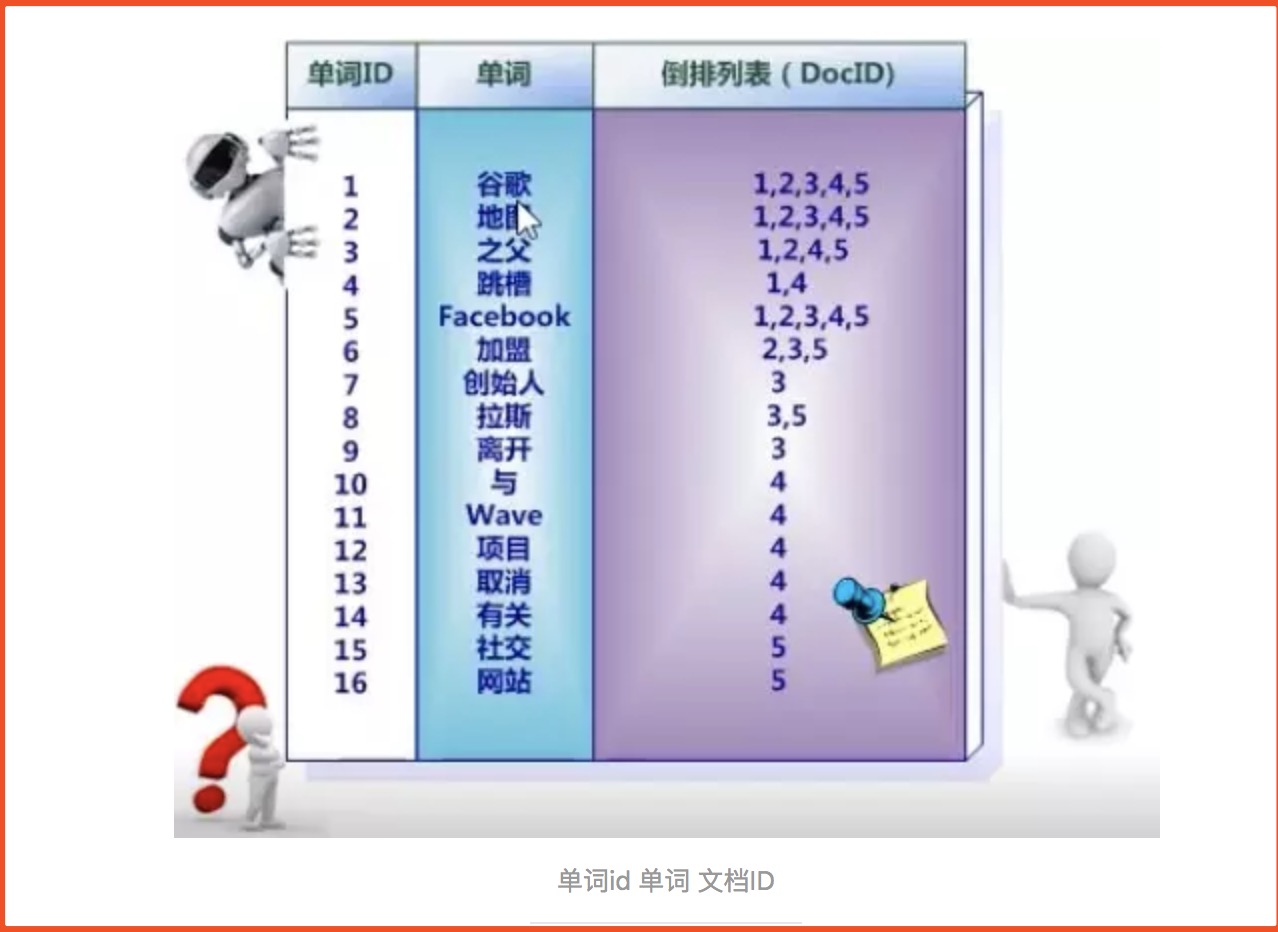
3、索引系統還可以記錄除此之外的更多資訊,下圖還記載了單詞頻率資訊。文件中的句子被劃分為一個個term(term 用來表示一個單詞或詞語,取決於使用的分詞方式),
倒敘索引中儲存著term,term的出現頻率(tf,term frequency)和出現位置(倒敘索引中的單詞是按順序排列的,這張圖沒有體現出來),請注意這裡的文件內容是document
中的一個欄位,也就是說每個被索引了的欄位都有自己的倒敘索引

一次簡單的搜尋流程
假設我們搜尋谷歌地圖之父,搜尋流程會是這樣
- 分詞,分詞外掛將句子分為3個term
谷歌,地圖,之父 - 將這3個term拿到倒敘索引中去查詢(會很高效,比如二分查詢),如果匹配到了就拿對應的文件id,獲得文件內容
但是,如何確定結果順序?
這裡要引入_score的概念,對於term的匹配,lucene會對其打分,得分越高,排名越靠前.這裡要介紹幾個相關的概念
- TF(term frequency),詞頻,term在當前document中出現的頻率,一個term在當前document中出現5次要比出現1次更相關,打分也會更高
- IDF(inverse doucment frequency),逆向文件頻率,term在所有document中出現的頻率,這個頻率越高,該term對應的分值越低
- 欄位長度歸一值,簡單來說就是欄位越短,欄位的權重越高, 比如 term `我`在匹配 `我123`和`我123456`時,`我123`的得分會更高.參考
1、Elasticsearch核心技術與實戰---阮一鳴(eBay Pronto平臺技術負責人
2、ElasticSearch 基本概念
3、Elasticsearch之基礎概念
4、ElasticSearch第5節 倒排索引、分詞器
我相信,無論今後的道路多麼坎坷,只要抓住今天,遲早會在奮鬥中嚐到人生的甘甜。抓住人生中的一分一秒,勝過虛度中的一月一年!(8)<