
[CVPR2018] An Analysis of Scale Invariance in Object Detection – SNIP
An Analysis of Scale Invariance in Object Detection – SNIP
簡介
這篇文章分析了小尺度與預訓練模型尺度之間的關係, 並且提出了一個和 有異曲同工之妙的中心思想: 要讓輸入分佈接近模型預訓練的分佈(本文主要探討尺度的分佈不一致帶來的問題).
之後利用分析的結論, 提出了一個多尺度訓練(MST)的升級版:Scale Normalization for Image Pyramids (SNIP).
分類和檢測的難度差異
上了深度網路後, 分類任務已經做到了誤差率2%(ImageNet). 為什麼在COCO上才62%? 這麼懸殊的距離主要因為檢測資料集中包含了大量小物體, 他們成了絆腳石.

* 結論: 檢測器必須同時應對如此之大的尺度變化的樣本, 這就導致了我們使用ImageNet(或其他分類)預訓練模型時, 有嚴重的domain-shift問題.
各種對付尺度變化的方法
- 深淺特徵融合
- 改變卷積核(Dilated/Deformable)來識別大物體
- 每層獨立predict
- 多尺度訓練/測試
作者丟擲的兩個問題
- 檢測中把圖片放大了再使用對效能提升至關重要嗎 (通常480x640的尺寸要放大到800x1200)?
為了檢測小物體, 可以不可以在ImageNet上用低畫素圖片預訓練一個縮放倍數較小的CNN? - 用ImageNet做預訓練模型的時候訓練檢測器的時候, 是否所有尺寸的object都可以參與進來?
還是隻是一小部分在範圍內的模型(如 64x64 到 256x256)
分析現存的解決方法
淺層小物體, 深層大尺度
- 例子: SDP, SSH, MS-CNN.
- 缺點: 在淺層預測小物體時, 是以犧牲語意抽象性來實現的.
特徵融合/特徵金字塔
儘管Feature Pyramids 有效的綜合了多卷積層特徵圖資訊,但是對於very small/large objects 檢測效果不是很好
- 例子: FPN, Mask-RCNN, RetinaNet
- 缺點: 若一個25x25的物體, 即使融合上取樣x2後也仍然只有50x50. 距離預訓練模型224x224還是有很大差距.
多尺度分類問題
藉由分類模型的實驗, 探索檢測中domain-shift帶來的影響. 檢測中的Domain-shift主要來自於訓練/測試尺度不匹配:
* 訓練800x1200. 因為視訊記憶體有所限制, 不能更大了
* 測試1400x2000. 為了提升小物體檢測效能

CNN-B: 原圖訓練 / 偽高清測試
CNN-B是一個在224x224尺度上訓練的模型, 其. 我們將測試圖片降取樣到 [48x48, 64x64, 80x80, 96x96,128x128], 然後再放大回224x224用於測試. 結果如圖:
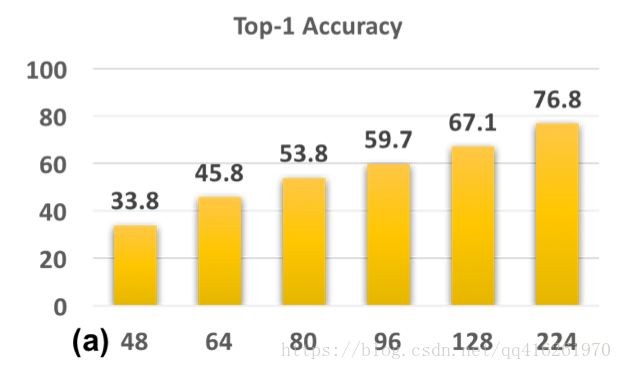
* 結論: 訓/測尺度(實際上是清晰度)差距越大, 效能跌的越厲害. 因為不用與訓練尺度相互匹配的尺度進行測試, 會使得模型一直在sub-optimal發揮.
CNN-S: 低清訓練 / 低清測試
CNN-S是根據上述原則, 我們做一個訓/測尺度匹配的實驗. 選取48x48作為訓/測尺度. 並且, 因為如果不修改的話很容易就卷沒了. 模型架構變了, 於是針對與上文CNN-S的可比較性問題, 作者說:
After-all, network architectures which obtain best performance on CIFAR10 [17] (which contains small objects) are different from ImageNet
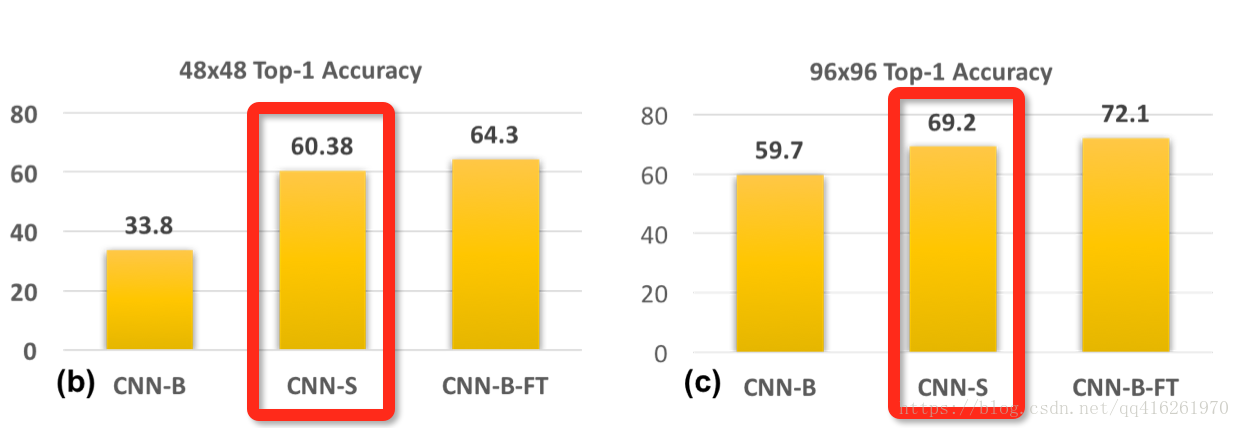
根據結果看到, 訓/測尺度匹配後, 效能大幅提升. 同樣將48換成96也得到一致的結果.
CNN-B-FT: 原圖訓練, 偽高清微調 / 偽高清測試
我們很容易想到的另一種方法就是, 為了在偽高清尺度測試, 我們就把由原圖訓練的CNN-B用偽高清去做微調. 最終CNN-B-FT的結果甚至好於CNN-S.
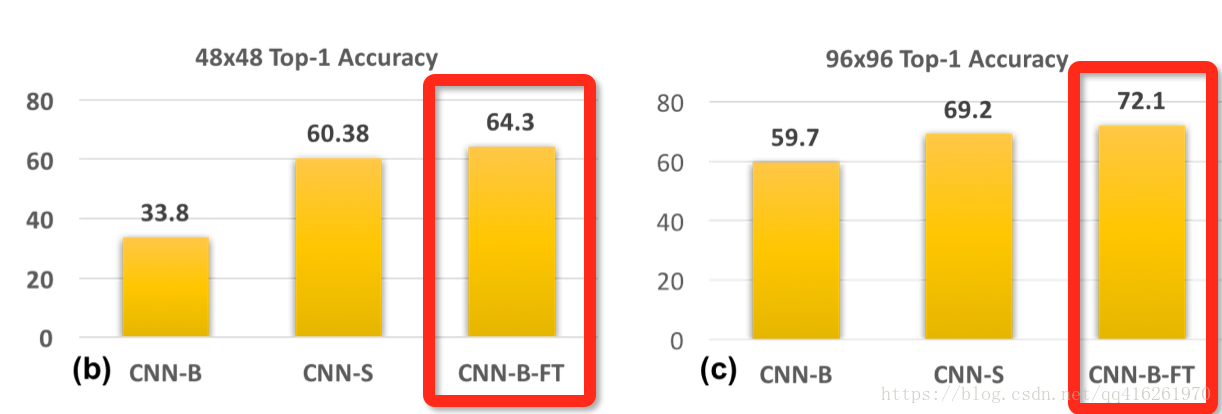
結論
- 從CNN-B-FT的實驗可以得出: 在高清訓練集學出來的模型依然有辦法在低清晰度的圖片上做預測. 直接用低清晰度圖片微調好過將降低重新訓練一個.
- 推廣到目標檢測上, 當尺度不同時, 我們可以選擇更換在ImageNet上pre-trained網路架構. 或者我們根據上述結論, 直接使用同一個網路架構, 因為在分類任務上學到的大目標權重可以幫助我們在小目標上的分類.
分析尺度變化
資料庫中原圖尺寸為640x48, 小物體是小於32x32的物體
實驗 vs
- 實驗設定: 我們選用800x1200和1400x2000兩種訓練尺度, 分別記作和. 測試時, 我們都使用1400x2000的尺度.
- 結果比較:
| 19.6 | 19.9 |
* 分析: 正如之前分析的一樣, 當訓/測尺度一致時, 得到的結果最好. 所以勝出.
* 問題: 但是為什麼只超過了一點點呢? 因為在考慮小物體的分類效能而放大圖片的同時, 也將中/大尺度的樣本放大得太大, 導致無法正確識別.
實驗
- 實驗設定: 用了大圖, 卻被中/大尺寸的樣本破壞了效能, 那麼我們就只用小於某閾值的樣本進行訓練, 即在原圖尺寸中的樣本直接拋棄, 只保留的樣本參與訓練.
- 結果比較:
| 16.4 | 19.6 | 19.9 |
* 分析問題: 跟預想的不一樣, 為什麼效能下降這麼多? 其根本原因是因為這種做法拋去了太多的樣本(~30%), 導致訓練集豐富性下降, 尤其是拋棄的那個尺度的樣本.
實驗多尺度訓練(MST)
- 實驗設定: 多尺度訓練保證了各個尺度的樣本, 都有機會被縮放到合理的尺度區間參與訓練.
- 結果比較:
| 16.4 | 19.6 | 19.9 | 19.5 |
* 分析問題: 其最終效能跟 沒太大差別, 主要原因和”實驗 vs 類似, 因為這一次引入了極大/極小的訓練樣本.
Scale Normalization for Image Pyramids (SNIP)
- 思想: SNIP是MST的升級版. 只有當這個物體的尺度與預訓練資料集的尺度(通常224x224)接近時, 我們才把它用來做檢測器的訓練樣本.
- 還基於一個假設, 即不同尺度的物體, 因為多尺度訓練, 總有機會落在一個合理的尺度範圍內. 只有這部分合理尺度的物體參與了訓練, 剩餘部分在BP的時候被忽略了
SNIP操作
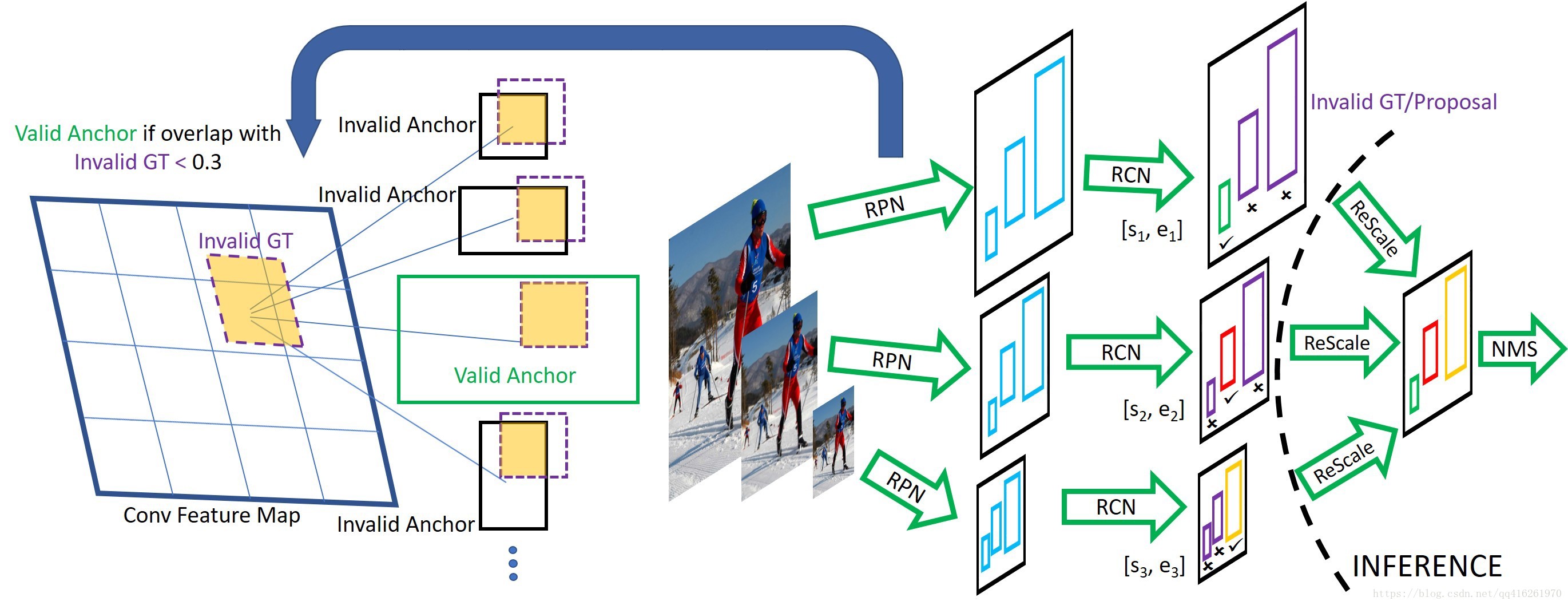
RPN階段
- 用所有的GroundTruth給Anchors分配好+/-標籤
- 根據第個尺度下的valid range: , 將GroundTruth根據是否落在範圍內分為Valid/Invalid GT
- 去除那些的Anchors
FC階段
- 用所有的GroundTruth給ProposalRoIs分配好類別標籤
- 棄用不在範圍內的GT和Proposals
- 全被剔除了的處理:
If there are no ground truth boxes within the valid range at a particular resolution in an image, that image- resolution pair is ignored during training
測試階段
- 用多尺度正常進行測試
- 在合併多尺度Detection之前, 只在各個尺度留下滿足其條件的Detection
- Soft-NMS合併 (對比的其他模型有沒有soft-nms?)
Sub-Image取樣
考慮到GPU視訊記憶體, 需要crop圖片來滿足視訊記憶體侷限.
* 用最少數量的1000x1000的chips來囊括所有的小物體. 如果沒有小物體的話, 這個區域就不需要進行任何計算, 加速訓練.
* 操作:
只對1400x2000的圖片進行取樣. 800x1200/480x640/圖片無小物體時, 不進行取樣
sampled_chips = []
while num_sampled_unique_object < num_object:
chips = get_random_chips(size=(1000,1000), number=50)
sampled_chips.append( chips.where(chips.num_objects is max ) )
sampled_chips = sampled_chips.truncate_boundary() 相關推薦
[CVPR2018] An Analysis of Scale Invariance in Object Detection – SNIP
An Analysis of Scale Invariance in Object Detection – SNIP 簡介 這篇文章分析了小尺度與預訓練模型尺度之間的關係, 並且提出了一個和 有異曲同工之妙的中心思想: 要讓輸入分佈接近模型預
An Analysis of Scale Invariance in Object Detection – SNIP 論文解讀
記錄 測試的 one zhang 不可 策略 correct 抽象 alt 前言 本來想按照慣例來一個overview的,結果看到一篇十分不錯而且詳細的介紹,因此copy過來,自己在前面大體總結一下論文,細節不做贅述,引用文章講得很詳細。 論文概述 引用文章 以下內容來自:
跟蹤演算法基準--Tracking the Trackers: An Analysis of the State of the Art in Multiple Object Tracking
Tracking the Trackers: An Analysis of the State of the Art in Multiple Object Tracking https://arxiv.org/abs/1704.02781 本文針對多目標
論文翻譯 DOTA:A Large-scale Dataset for Object Detection in Aerial Images
網絡 操作 邊框 允許 官方 靈活 數量級 image 轉化 簡介:武大遙感國重實驗室-夏桂松和華科電信學院-白翔等合作做的一個航拍圖像數據集 摘要: 目標檢測是計算機視覺領域一個重要且有挑戰性的問題。雖然過去的十幾年中目標檢測在自然場景已經有了較重要的成就
An Overview of JavaScript Testing in 2018
IntroLook at the logo of Jest, a testing framework by Facebook:As you can see, their slogan promises a “painless” JavaScript Testing, but as “some guy from
An Empirical Analysis of Anonymity in Zcash
摘要 在現在眾多來源於(derived from)比特幣的替代(alternative)加密貨幣中,Zcash經常被吹捧(touted)為具有最強匿名保證(guarantees)的加密貨幣,因為它是備受好評(well-regarded)的加密研究的基礎。 在本文中,我們將檢
[譯]深度神經網絡的多任務學習概覽(An Overview of Multi-task Learning in Deep Neural Networks)
noi 使用方式 stats 基於 共享 process machines 嬰兒 sdro 譯自:http://sebastianruder.com/multi-task/ 1. 前言 在機器學習中,我們通常關心優化某一特定指標,不管這個指標是一個標準值,還是企業KPI。為
ionic3打包出錯ionic cordova build android(系列一):could not find an installed version of gradle either in android studio
lan 問題 打包 fail .html ascii failed contains ref 1.運行ionic cordova build android 時報錯:could not find an installed version of gradle either i
for in,Object.keys()與for of的區別
-o https map對象 tps 屬性 get for his ron for in for in一般用於遍歷對象的屬性; 作用於數組的for in除了會遍歷數組元素外,還會遍歷自定義可枚舉的屬性,以及原型鏈上可枚舉的屬性; 作用於數組的for in的遍歷結果是數組的
[LeetCode] 323. Number of Connected Components in an Undirected Graph 無向圖中的連通區域的個數
arr from sla cnblogs AI dup each rect href Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of n
421. Maximum XOR of Two Numbers in an Array
可變 這樣的 TE 固定 需要 AI class turn copy 這題要求On時間復雜度完成, 第一次做事沒什麽思路的, 答案網上有不貼了, 總結下這類題的思路. 不局限於這個題, 凡是對於這種給一個 數組, 求出 xxx 最大值的辦法, 可能上來默認就是dp, 但
for in,Object.keys()與for of的用法與區別
輸出結果 例子 iter iterator style 內容 通過 結果 array Array.prototype.sayLength=function(){ console.log(this.length); } let arr = [‘a‘
Given an array of integers that is already sorted in ascending order, find two numbers such that the
這道題自己思路也對了,就是陣列使用出了點問題,然後就是看了別人的程式碼才改過來,用到匿名陣列。 不多說,看程式碼, class Solution { public int[] twoSum(int[] numbers, int target) {
深度神經網路的多工學習概覽(An Overview of Multi-task Learning in Deep Neural Networks)
譯自:http://sebastianruder.com/multi-task/ 1. 前言 在機器學習中,我們通常關心優化某一特定指標,不管這個指標是一個標準值,還是企業KPI。為了達到這個目標,我們訓練單一模型或多個模型集合來完成指定得任務。然後,我們通過精細調參,來改進模型直至效能不再
"The conversion of a datetime2 data type to a datetime data type resulted in an out-of-range value
這句話的意思是將datetime2資料型別轉換為datetime資料型別會導致超出範圍的值。宣告已經終止。 在使用EF插入資料是發生列轉換的錯誤,搞了好久,不知道問題出在哪裡! 根據提示的錯誤資訊來看是Datetime資料型別出現錯誤 後來發現 public Nullable<S
python leetcode 421. Maximum XOR of Two Numbers in an Array
通過mask來判斷最終結果在哪些bit上能取到1 核心公式a^b=c <---->a^c=b 以下是自己的理解 nums=[3, 10, 5, 25, 2, 8,26] 這裡因為最大數才25所以bit直接從4開始 3 ‘00011’ 10 ‘01010’ 5 ‘00101’ 25
An Overview of Multi-Task Learning in Deep Neural Networks
在人類學習中,不同學科之間的往往能起到相互促進的作用。那麼,對於機器學習是否也是這樣的,我們不僅僅讓它專注於學習一個任務,而是讓它學習多個相關的任務,是否可以讓機器在各個任務之間融會貫通,從而提高在主任務上面的結果呢? 1.multi-task的兩種形式 前面的層是權
[LeetCode] Maximum XOR of Two Numbers in an Array 陣列中異或值最大的兩個數字
Given a non-empty array of numbers, a0, a1, a2, … , an-1, where 0 ≤ ai < 231. Find the maximum result of ai XOR aj, where 0 ≤ i, j < n. Could you
[LeetCode] Number of Connected Components in an Undirected Graph 無向圖中的連通區域的個數
Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of nodes), write a function to find the number of connected com
Analysis of Subway and Foot Traffic in NYC
Analysis of Subway and Foot Traffic in NYCWe hit the ground running in our first week at the Metis Data Science Bootcamp! We had a pretty tight timeframe f