
Ganglia叢集監控
介紹
Ganglia是UC Berkeley發起的一個開源叢集監視專案,設計用於監控數以千計的節點。Ganglia主要是用來監控系統性能,如:cpu、mem、硬碟利用率,I/O負載、網路流量情況等,通過曲線很容易見到每個節點的工作狀態,對合理調整、分配系統資源,提高系統整體效能起到重要作用。
Ganglia的核心包含gmond、gmetad以及一個Web前端。
gmond(Ganglia Monitoring Daemon)是一種輕量級服務,安裝在每臺需要收集指標資料的節點主機上。gmond在每臺主機上完成實際意義上的指標資料收集工作,並通過偵聽/通告協議和叢集內其他節點共享資料。使用gmond,你可以很容易收集很多系統指標資料,如CPU、記憶體、磁碟、網路和活躍程序的資料等。
gmetad(Ganglia Meta Daemon)是一種從其他gmetad或gmond源收集指標資料,並將其以RRD格式儲存至磁碟的服務。gmetad為從主機組收集的特定指標資訊提供了簡單的查詢機制,並支援分級授權,使得建立聯合監測域成為可能。
gweb(Ganglia Web)是一種利用瀏覽器顯示gmetad所儲存資料的PHP前端。在Web介面中以圖表方式展現叢集的多種不同指標資料。
ganglia系統架構
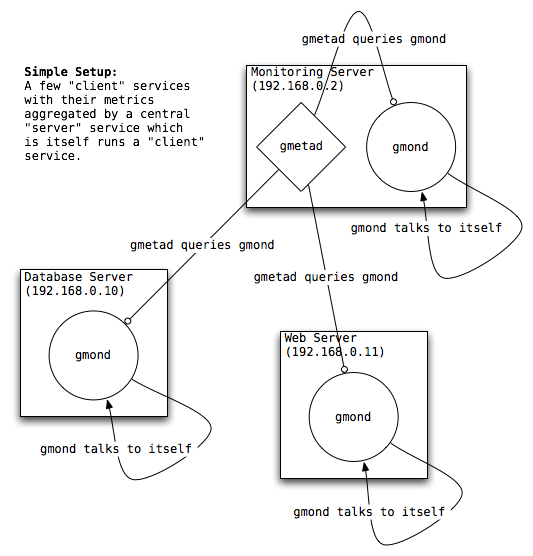
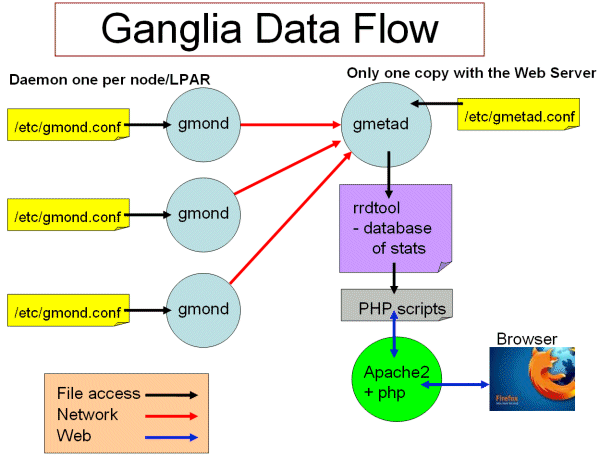
1.管理節點通過gmetad.conf配置檔案中的代理節點主機列表地址和代理節點相互通訊,大概三分鐘輪詢一次。
2.管理節點收集每個代理節點的機器執行資訊,這些資訊是通過XML協議進行傳輸。
3.管理節點收集到代理節點的XML協議後,解析成管理節點需要的資料格式。
4.再通過管理節點的PHP程式呼叫rrdtool工具,將資料轉換成圖形。
5.當用戶在瀏覽器上輸入管理節點的url地址就可以看見圖形化的資料了。
Hadoop原生的支援ganglia監控,並且可以自己配置metric。
上面的說明中管理節點向代理節點發送多播訊息,ganglia當然也支援單播通訊。
EPEL
企業版Linux附加軟體包(Extra Packages for Enterprise Linux,EPEL)是一個由特別興趣小組建立、維護並管理的,針對紅帽企業版Linux(RHEL)及其衍生髮行版(比如CentOS、Scientific Linux、Oracle Enterprise Linux)的一個高質量附加軟體包專案。
EPEL的軟體包通常不會與企業版Linux官方源中的軟體包發生衝突,或者互相替換檔案。
CentOS使用者可以直接通過yum install epel-release安裝並啟用EPEL源。
更多EPEL的資訊參見EPEL。
在CentOS上用yum安裝gmod和gmetad需要提前安裝EPEL。
配置gmond
/etc/ganglia/gmond.conf
globals欄位裡send_metadata_interval設定為10,表示每10秒傳送一次資料。如果不使用多播,這個值應設為一個正整數,60秒是一個合理值。
cluster欄位裡的name標識叢集的名字。
udp_send_channel欄位裡,mcast_join為多播模式,如果是單播模式需要註釋掉mcast_join,並新增
host = 127.0.0.1(伺服器的IP地址)
port = 8649(傳送資料的埠)
udp_recv_channel {
port = 8649 // 接收資料的埠號,如果是用單播模式則要刪除mcast_join
}配置gmetad
/etc/ganglia/gmetad.conf
data_source標識一個要監控的叢集(一些gmond或另一個gmetad)。格式為:
data_source "my cluster" [polling interval] address1:port addreses2:port ...
polling interval預設15秒。
埠預設8649。
setuid_username ganglia
設定執行使用者
rrd_rootdir “/var/lib/ganglia/rrds”
gmetad儲存round-robin資料庫的位置,要保證這個目錄可以被上面設定的使用者讀寫安裝過程
yum install ganglia-gmond
yum install ganglia-gmetad
然後要安裝gweb就,這個需要的依賴比較多,我也不知道哪個裝哪個不裝,索性都裝上吧:
yum install php rrdtool rrdtool-devel ganglia-web apr-devel zlib-devel libconfuse-devel expat-devel pcre-devel
啟動
需要先關閉SELinux
service gmond start
service gmetad start
service httpd restart
讓外部機器也可以訪問本機ganglia
修改/etc/httpd/conf/httpd.conf,在檔案末尾新增下列資訊,並重啟httpd服務即可。
<location /ganglia>
order deny,allow
deny from all
allow from all
</location>
Hadoop
./etc/hadoop/目錄下有兩個配置檔案:hadoop-metrics.properties和hadoop-metrics2.properties。
組播
區域性連結地址:224.0.0.0~224.0.0.255,用於區域網,路由器不轉發屬於此範圍的IP包;
預留組播地址:224.0.1.0~238.255.255.255,用於全球範圍或網路協議;
管理許可權地址:239.0.0.0~239.255.255.255,組織內部使用,用於限制組播範圍;
我理解,第一種是區域網用的,第二種是全球統一分配,第三種可以內部使用,但需要限制ttl跳數。
參考
相關推薦
Ganglia叢集監控
介紹 Ganglia是UC Berkeley發起的一個開源叢集監視專案,設計用於監控數以千計的節點。Ganglia主要是用來監控系統性能,如:cpu、mem、硬碟利用率,I/O負載、網路流量情況等,通過曲線很容易見到每個節點的工作狀態,對合理調整、分配系統資源
以容器部署Ganglia並監控Hadoop叢集
網上有很多Ganglia部署的教程,每一個我都覺得繁瑣,我的目的只是用來監控Hadoop測試叢集,能即刻使用才是王道,於是我想到通過Rancher部署Ganglia應用服務(類似於我在上一篇文章中部署Jmeter容器叢集的方式),以容器的方式一鍵部署,省去了中間繁瑣的安裝過程。 第一步:安裝
叢集監控之Ganglia的部署
轉載地址:https://www.slothparadise.com/how-to-install-ganglia-on-centos-7/ 找了一堆文章,全都誤導了,這篇正解。 總結步驟如下: 1、server端 : yum install -y ga
Ubuntu安裝Ganglia並監控Hadoop叢集
關於 Ganglia 軟體,Ganglia是一個跨平臺可擴充套件的,高效能運算系統下的分散式監控系統,如叢集和網格。它是基於分層設計,它使用廣泛的技術,如XML資料代表,便攜資料傳輸,RRDtool用於資料儲存和視覺化。它利用精心設計的資料結構和演算法實現每節點間併發非常低
flume之叢集監控 Ganglia 部署配置
flume支援http,ganglia,custom監控模式 http很簡單,就是開放一個埠可以通過http請求拿取當前agent的各項資料 ganglia是一個開源的叢集監控解決方案,自帶統計,web展現 custom就是自定義方案了。 當然為了圖省事,少弄些web畫圖
spring cloud: Hystrix(八):turbine叢集監控(dashboard)
turbine是聚合伺服器傳送事件流資料的一個工具,hystrix的監控中,只能監控單個節點,實際生產中都為叢集, 因此可以通過turbine來監控叢集下hystrix的metrics情況,通過eureka來發現hystrix服務。 dashboard可以監控單個數據流,通過turbine可以顯示叢集的資
Redis叢集監控方法
1. 技術領域 提供一種Redis叢集中各Redis節點的監控處理方法,能夠採集Redis節點的資源資訊、效能指標資料,叢集內多個Redis節點服務執行狀態監控。實現告警監控資訊、資源和效能指標的採集與分析的監控方法
Centos6.10下Open-falcon學習記錄(零)——主機監控、Nodata元件、叢集監控
記錄了學習過程,官方文件地址http://book.open-falcon.org/zh_0_2/usage/getting-started.html 另外還看了Open-falcon作者的寫的設計理念的文,見open-falcon編寫的整個腦洞歷程 1 主機監控 1.1 主機配置
HBase叢集監控的那些事兒
為什麼需要監控? 為了保證系統的穩定性,可靠性,可運維性。 掌控叢集的核心效能指標,瞭解叢集的效能表現; 叢集出現問題時及時報警,便於運維同學及時修復問題; 叢集重要指標值異常時進行預警,將問題扼殺在搖籃中,不用等叢集真正不可用時才採取行動; 當叢集出現問題時,監控
scrapydweb:實現 Scrapyd 伺服器叢集監控和互動,Scrapy 日誌分析和視覺化
Scrapyd 伺服器叢集監控和互動 支援通過分組和過濾選中特定伺服器節點 一次點選,批量執行 Scrapy 日誌分析 統計資訊展示 爬蟲進度視覺化 關鍵日誌分類 支援所有 Scrapyd API Deploy project, Run Spider, Stop job List pr
k8s叢集監控
目前,監控K8S叢集較為流行的方案如下: 方案一:Heapster + influxDB + Grafana Heapster 是 Kubernetes 原生的叢集監控方案。Heapster 以 Pod 的形式執行,在其配置檔案內傳入kubernetes master的地
Elastic search (3) 叢集監控與管理
elastic search 叢集監控管理 對於前兩篇的單獨指令碼整合成為定期任務 基礎命令 使用非同步框架,具有更好的效能 專案地址 目標對elastic叢集健康進行管理,對目標日誌內容進行監控
Redis叢集監控工具之RedisLive
這裡將介紹下redis叢集監控UI工具之RedisLive的安裝部署。 說白了,RedisLive就是一款免費開源的基於Python、tornado的的reids的監控工具,以WEB的形式展現出redis中的記憶體、key,例項資料等資訊!Redis
ganglia學習1之ganglia叢集版搭建(支援hadoop和spark)
spark原始碼解讀系列環境:spark-1.5.2、hadoop-2.6.0、scala-2.10.4,ganglia-3.6.1 系統:ubuntu 14.04 1.理解 1.1 ganglia的概述 Ganglia是UC B
redis3 叢集監控介紹
一 redis請求處理介紹 1. redis Server是單執行緒 優點:因為CPU不是Redis的瓶頸。Redis的瓶頸最有可能是機器記憶體或者網路頻寬,採用佇列模式將併發訪問變為序列執行。 redis快速原因是絕大部分請求是純粹的記憶體操作(非常
Redis叢集監控及Redis桌面客戶端
之前在生產環境部署了Redis叢集,一直苦於沒有工具監控,最近找了下網上推薦redmon和Redislive的比較多,查看了兩個專案的github,都幾年沒有更新,這兩個專案應該沒有人在維護了,如果哪位有更好的替代方案麻煩告知! 僅將自己的部署方案貼出來,以供自己翻查! 具
Redis-叢集監控之Redis monitor
連續兩天配置Redis 叢集監控,嘗試過三種開源軟體,Redis-live,Redis-state,Redis-monitor ,由於內網生產環境,每一個軟體的部署都費了老勁。 簡單說一下,避免再有人趟坑。 1、Redis-live:此專案5年沒有維護過了,
Prometheus監控實踐:Kubernetes叢集監控_Kubernetes中文社群
本文將總結一下我們目前使用Prometheus對Kubernetes叢集監控的實踐。 我們選擇Prometheus作為監控系統主要在以下各層面實現監控: 基礎設施層:監控各個主機伺服器資源(包括Kubernetes的Node和非Kubernetes的Node),如CPU,記憶體,網路吞吐和頻
springcloud實戰之9 斷路器-叢集監控(turbine)
上一篇介紹了單例的服務監控,本章介紹對叢集的監控。通過引入turbine,通過它來彙集監控資訊,並將聚合後的資訊提供給Hystrix Dashboard來集中展示和監控。 其工作架構圖如下: 構建springcloud-hystrix-turbine
Spring Cloud學習--容錯機制(Hystrix之Turbine叢集監控)
使用Turbine聚合監控資料 除了使用/hystrix.stream端點監控單個微服務例項,可以使用Turbine將所有相關的/hystrix.stream聚合到一個組合的/turbine.stream中。 本文依據Hystrix,可見http://