
Python學習筆記26:正則表示式
使用 ? 和 * 萬用字元來查詢硬碟上的檔案。? 萬用字元匹配檔名中的 0 個或 1 個字元,而 * 萬用字元匹配零個或多個字元。像 data(\w)?\.dat 這樣的模式將查詢下列檔案:
data.dat
data1.dat
data2.dat datax.dat dataN.dat
使用 * 字元代替 ? 字元擴大了找到的檔案的數量。data.*\.dat 匹配下列所有檔案:
data.dat
data1.dat
data2.dat data12.dat datax.dat dataXYZ.dat
儘管這種搜尋方法很有用,但它還是有限的。通過理解 * 萬用字元的工作原理,引入了正則表示式所依賴的概念,但正則表示式功能更強大,而且更加靈活。
正則表示式的使用,可以通過簡單的辦法來實現強大的功能。下面先給出一個簡單的示例:
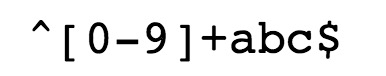
-
^ 為匹配輸入字串的開始位置。
-
[0-9]+匹配多個數字, [0-9] 匹配單個數字,+ 匹配一個或者多個。
-
abc$匹配字母 abc 並以 abc 結尾,$ 為匹配輸入字串的結束位置。
我們在寫使用者登錄檔單時,只允許使用者名稱包含字元、數字、下劃線和連線字元(-),並設定使用者名稱的長度,我們就可以使用以下正則表示式來設定。
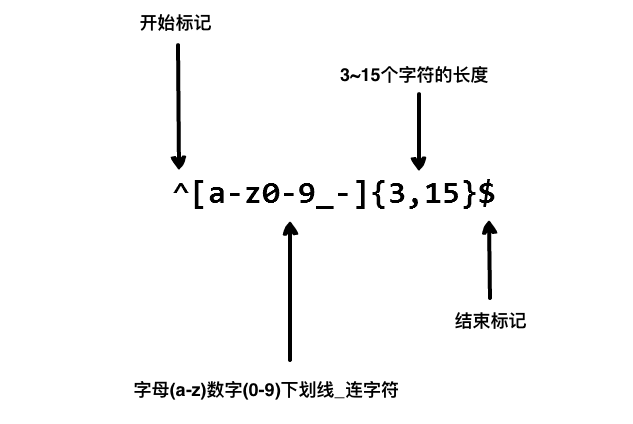
以上的正則表示式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因為它包含了小寫的字母而且太短了,也不匹配 runoob$, 因為它包含特殊字元。
為什麼使用正則表示式?
典型的搜尋和替換操作要求您提供與預期的搜尋結果匹配的確切文字。雖然這種技術對於對靜態文字執行簡單搜尋和替換任務可能已經足夠了,但它缺乏靈活性,若採用這種方法搜尋動態文字,即使不是不可能,至少也會變得很困難。
通過使用正則表示式,可以:
- 測試字串內的模式。
例如,可以測試輸入字串,以檢視字串內是否出現電話號碼模式或信用卡號碼模式。這稱為資料驗證。 - 替換文字。
可以使用正則表示式來識別文件中的特定文字,完全刪除該文字或者用其他文字替換它。 - 基於模式匹配從字串中提取子字串。
可以查詢文件內或輸入域內特定的文字。
例如,您可能需要搜尋整個網站,刪除過時的材料,以及替換某些 HTML 格式標記。在這種情況下,可以使用正則表示式來確定在每個檔案中是否出現該材料或該 HTML 格式標記。此過程將受影響的檔案列表縮小到包含需要刪除或更改的材料的那些檔案。然後可以使用正則表示式來刪除過時的材料。最後,可以使用正則表示式來搜尋和替換標記。
發展歷史
正則表示式的"祖先"可以一直上溯至對人類神經系統如何工作的早期研究。Warren McCulloch 和 Walter Pitts 這兩位神經生理學家研究出一種數學方式來描述這些神經網路。
1956 年, 一位叫 Stephen Kleene 的數學家在 McCulloch 和 Pitts 早期工作的基礎上,發表了一篇標題為"神經網事件的表示法"的論文,引入了正則表示式的概念。正則表示式就是用來描述他稱為"正則集的代數"的表示式,因此採用"正則表示式"這個術語。
隨後,發現可以將這一工作應用於使用 Ken Thompson 的計算搜尋演算法的一些早期研究,Ken Thompson 是 Unix 的主要發明人。正則表示式的第一個實用應用程式就是 Unix 中的 qed 編輯器。
如他們所說,剩下的就是眾所周知的歷史了。從那時起直至現在正則表示式都是基於文字的編輯器和搜尋工具中的一個重要部分。
正則表示式(regular expression)描述了一種字串匹配的模式(pattern),可以用來檢查一個串是否含有某種子串、將匹配的子串替換或者從某個串中取出符合某個條件的子串等。
例如:
-
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 號代表前面的字元必須至少出現一次(1次或多次)。
-
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 號代表字元可以不出現,也可以出現一次或者多次(0次、或1次、或多次)。
-
colou?r 可以匹配 color 或者 colour,? 問號代表前面的字元最多隻可以出現一次(0次、或1次)。
構造正則表示式的方法和建立數學表示式的方法一樣。也就是用多種元字元與運算子可以將小的表示式結合在一起來建立更大的表示式。正則表示式的元件可以是單個的字元、字元集合、字元範圍、字元間的選擇或者所有這些元件的任意組合。
正則表示式是由普通字元(例如字元 a 到 z)以及特殊字元(稱為"元字元")組成的文字模式。模式描述在搜尋文字時要匹配的一個或多個字串。正則表示式作為一個模板,將某個字元模式與所搜尋的字串進行匹配。
普通字元
普通字元包括沒有顯式指定為元字元的所有可列印和不可列印字元。這包括所有大寫和小寫字母、所有數字、所有標點符號和一些其他符號。
非列印字元
非列印字元也可以是正則表示式的組成部分。下表列出了表示非列印字元的轉義序列:
| 字元 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字元。例如, \cM 匹配一個 Control-M 或回車符。x 的值必須為 A-Z 或 a-z 之一。否則,將 c 視為一個原義的 'c' 字元。 |
| \f | 匹配一個換頁符。等價於 \x0c 和 \cL。 |
| \n | 匹配一個換行符。等價於 \x0a 和 \cJ。 |
| \r | 匹配一個回車符。等價於 \x0d 和 \cM。 |
| \s | 匹配任何空白字元,包括空格、製表符、換頁符等等。等價於 [ \f\n\r\t\v]。注意 Unicode 正則表示式會匹配全形空格符。 |
| \S | 匹配任何非空白字元。等價於 [^ \f\n\r\t\v]。 |
| \t | 匹配一個製表符。等價於 \x09 和 \cI。 |
| \v | 匹配一個垂直製表符。等價於 \x0b 和 \cK。 |
特殊字元
所謂特殊字元,就是一些有特殊含義的字元,如上面說的 runoo*b 中的 *,簡單的說就是表示任何字串的意思。如果要查詢字串中的 * 符號,則需要對 * 進行轉義,即在其前加一個 \: runo\*ob 匹配 runo*ob。
許多元字元要求在試圖匹配它們時特別對待。若要匹配這些特殊字元,必須首先使字元"轉義",即,將反斜槓字元\ 放在它們前面。下表列出了正則表示式中的特殊字元:
| 特別字元 | 描述 |
|---|---|
| $ | 匹配輸入字串的結尾位置。如果設定了 RegExp 物件的 Multiline 屬性,則 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字元本身,請使用 \$。 |
| ( ) | 標記一個子表示式的開始和結束位置。子表示式可以獲取供以後使用。要匹配這些字元,請使用 \( 和 \)。 |
| * | 匹配前面的子表示式零次或多次。要匹配 * 字元,請使用 \*。 |
| + | 匹配前面的子表示式一次或多次。要匹配 + 字元,請使用 \+。 |
| . | 匹配除換行符 \n 之外的任何單字元。要匹配 . ,請使用 \. 。 |
| [ | 標記一箇中括號表示式的開始。要匹配 [,請使用 \[。 |
| ? | 匹配前面的子表示式零次或一次,或指明一個非貪婪限定符。要匹配 ? 字元,請使用 \?。 |
| \ | 將下一個字元標記為或特殊字元、或原義字元、或向後引用、或八進位制轉義符。例如, 'n' 匹配字元 'n'。'\n' 匹配換行符。序列 '\\' 匹配 "\",而 '\(' 則匹配 "("。 |
| ^ | 匹配輸入字串的開始位置,除非在方括號表示式中使用,此時它表示不接受該字元集合。要匹配 ^ 字元本身,請使用 \^。 |
| { | 標記限定符表示式的開始。要匹配 {,請使用 \{。 |
| | | 指明兩項之間的一個選擇。要匹配 |,請使用 \|。 |
限定符
限定符用來指定正則表示式的一個給定元件必須要出現多少次才能滿足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6種。
正則表示式的限定符有:
| 字元 | 描述 |
|---|---|
| * | 匹配前面的子表示式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等價於{0,}。 |
| + | 匹配前面的子表示式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等價於 {1,}。 |
| ? | 匹配前面的子表示式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等價於 {0,1}。 |
| {n} | n 是一個非負整數。匹配確定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的兩個 o。 |
| {n,} | n 是一個非負整數。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等價於 'o+'。'o{0,}' 則等價於 'o*'。 |
| {n,m} | m 和 n 均為非負整數,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 將匹配 "fooooood" 中的前三個 o。'o{0,1}' 等價於 'o?'。請注意在逗號和兩個數之間不能有空格。 |
由於章節編號在大的輸入文件中會很可能超過九,所以您需要一種方式來處理兩位或三位章節編號。限定符給您這種能力。下面的正則表示式匹配編號為任何位數的章節標題:
/Chapter [1-9][0-9]*/
請注意,限定符出現在範圍表示式之後。因此,它應用於整個範圍表示式,在本例中,只指定從 0 到 9 的數字(包括 0 和 9)。
這裡不使用 + 限定符,因為在第二個位置或後面的位置不一定需要有一個數字。也不使用 ? 字元,因為使用 ? 會將章節編號限制到只有兩位數。您需要至少匹配 Chapter 和空格字元後面的一個數字。
如果您知道章節編號被限制為只有 99 章,可以使用下面的表示式來至少指定一位但至多兩位數字。
/Chapter [0-9]{1,2}/
上面的表示式的缺點是,大於 99 的章節編號仍只匹配開頭兩位數字。另一個缺點是 Chapter 0 也將匹配。只匹配兩位數字的更好的表示式如下:
/Chapter [1-9][0-9]?/
或
/Chapter [1-9][0-9]{0,1}/
*、+限定符都是貪婪的,因為它們會盡可能多的匹配文字,只有在它們的後面加上一個?就可以實現非貪婪或最小匹配。
例如,您可能搜尋 HTML 文件,以查詢括在 H1 標記內的章節標題。該文字在您的文件中如下:
<H1>Chapter 1 - 介紹正則表示式</H1>
貪婪:下面的表示式匹配從開始小於符號 (<) 到關閉 H1 標記的大於符號 (>) 之間的所有內容。
/<.*>/
非貪婪:如果您只需要匹配開始和結束 H1 標籤,下面的非貪婪表示式只匹配 <H1>。
/<.*?>/
如果只想匹配開始的 H1 標籤,表示式則是:
/<\w+?>/
通過在 *、+ 或 ? 限定符之後放置 ?,該表示式從"貪心"表示式轉換為"非貪心"表示式或者最小匹配。
定位符
定位符使您能夠將正則表示式固定到行首或行尾。它們還使您能夠建立這樣的正則表示式,這些正則表示式出現在一個單詞內、在一個單詞的開頭或者一個單詞的結尾。
定位符用來描述字串或單詞的邊界,^ 和 $ 分別指字串的開始與結束,\b 描述單詞的前或後邊界,\B 表示非單詞邊界。
正則表示式的定位符有:
| 字元 | 描述 |
|---|---|
| ^ | 匹配輸入字串開始的位置。如果設定了 RegExp 物件的 Multiline 屬性,^ 還會與 \n 或 \r 之後的位置匹配。 |
| $ | 匹配輸入字串結尾的位置。如果設定了 RegExp 物件的 Multiline 屬性,$ 還會與 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一個單詞邊界,即字與空格間的位置。 |
| \B | 非單詞邊界匹配。 |
注意:不能將限定符與定位符一起使用。由於在緊靠換行或者單詞邊界的前面或後面不能有一個以上位置,因此不允許諸如 ^* 之類的表示式。
若要匹配一行文字開始處的文字,請在正則表示式的開始使用 ^ 字元。不要將 ^ 的這種用法與中括號表示式內的用法混淆。
若要匹配一行文字的結束處的文字,請在正則表示式的結束處使用 $ 字元。
若要在搜尋章節標題時使用定位點,下面的正則表示式匹配一個章節標題,該標題只包含兩個尾隨數字,並且出現在行首:
/^Chapter [1-9][0-9]{0,1}/
真正的章節標題不僅出現行的開始處,而且它還是該行中僅有的文字。它即出現在行首又出現在同一行的結尾。下面的表示式能確保指定的匹配只匹配章節而不匹配交叉引用。通過建立只匹配一行文字的開始和結尾的正則表示式,就可做到這一點。
/^Chapter [1-9][0-9]{0,1}$/
匹配單詞邊界稍有不同,但向正則表示式添加了很重要的能力。單詞邊界是單詞和空格之間的位置。非單詞邊界是任何其他位置。下面的表示式匹配單詞 Chapter 的開頭三個字元,因為這三個字元出現在單詞邊界後面:
/\bCha/
\b 字元的位置是非常重要的。如果它位於要匹配的字串的開始,它在單詞的開始處查詢匹配項。如果它位於字串的結尾,它在單詞的結尾處查詢匹配項。例如,下面的表示式匹配單詞 Chapter 中的字串 ter,因為它出現在單詞邊界的前面:
/ter\b/
下面的表示式匹配 Chapter 中的字串 apt,但不匹配 aptitude 中的字串 apt:
/\Bapt/
字串 apt 出現在單詞 Chapter 中的非單詞邊界處,但出現在單詞 aptitude 中的單詞邊界處。對於 \B 非單詞邊界運算子,位置並不重要,因為匹配不關心究竟是單詞的開頭還是結尾。
選擇
用圓括號將所有選擇項括起來,相鄰的選擇項之間用|分隔。但用圓括號會有一個副作用,使相關的匹配會被快取,此時可用?:放在第一個選項前來消除這種副作用。
其中 ?: 是非捕獲元之一,還有兩個非捕獲元是 ?= 和 ?!,這兩個還有更多的含義,前者為正向預查,在任何開始匹配圓括號內的正則表示式模式的位置來匹配搜尋字串,後者為負向預查,在任何開始不匹配該正則表示式模式的位置來匹配搜尋字串。
反向引用
對一個正則表示式模式或部分模式兩邊新增圓括號將導致相關匹配儲存到一個臨時緩衝區中,所捕獲的每個子匹配都按照在正則表示式模式中從左到右出現的順序儲存。緩衝區編號從 1 開始,最多可儲存 99 個捕獲的子表示式。每個緩衝區都可以使用 \n 訪問,其中 n 為一個標識特定緩衝區的一位或兩位十進位制數。
可以使用非捕獲元字元 ?:、?= 或 ?! 來重寫捕獲,忽略對相關匹配的儲存。
反向引用的最簡單的、最有用的應用之一,是提供查詢文字中兩個相同的相鄰單詞的匹配項的能力。以下面的句子為例:
Is is the cost of of gasoline going up up?
下表包含了元字元的完整列表以及它們在正則表示式上下文中的行為:
| 字元 | 描述 |
|---|---|
| \ | 將下一個字元標記為一個特殊字元、或一個原義字元、或一個 向後引用、或一個八進位制轉義符。例如,'n' 匹配字元 "n"。'\n' 匹配一個換行符。序列 '\\' 匹配 "\" 而 "\(" 則匹配 "("。 |
| ^ | 匹配輸入字串的開始位置。如果設定了 RegExp 物件的 Multiline 屬性,^ 也匹配 '\n' 或 '\r' 之後的位置。 |
| $ | 匹配輸入字串的結束位置。如果設定了RegExp 物件的 Multiline 屬性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| * | 匹配前面的子表示式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等價於{0,}。 |
| + | 匹配前面的子表示式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等價於 {1,}。 |
| ? | 匹配前面的子表示式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等價於 {0,1}。 |
| {n} | n 是一個非負整數。匹配確定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的兩個 o。 |
| {n,} | n 是一個非負整數。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等價於 'o+'。'o{0,}' 則等價於 'o*'。 |
| {n,m} | m 和 n 均為非負整數,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 將匹配 "fooooood" 中的前三個 o。'o{0,1}' 等價於 'o?'。請注意在逗號和兩個數之間不能有空格。 |
| ? | 當該字元緊跟在任何一個其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配所搜尋的字串,而預設的貪婪模式則儘可能多的匹配所搜尋的字串。例如,對於字串 "oooo",'o+?' 將匹配單個 "o",而 'o+' 將匹配所有 'o'。 |
| . | 匹配除換行符(\n、\r)之外的任何單個字元。要匹配包括 '\n' 在內的任何字元,請使用像"(.|\n)"的模式。 |
| (pattern) | 匹配 pattern 並獲取這一匹配。所獲取的匹配可以從產生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中則使用 $0…$9 屬性。要匹配圓括號字元,請使用 '\(' 或 '\)'。 |
| (?:pattern) | 匹配 pattern 但不獲取匹配結果,也就是說這是一個非獲取匹配,不進行儲存供以後使用。這在使用 "或" 字元 (|) 來組合一個模式的各個部分是很有用。例如, 'industr(?:y|ies) 就是一個比 'industry|industries' 更簡略的表示式。 |
| (?=pattern) | 正向肯定預查(look ahead positive assert),在任何匹配pattern的字串開始處匹配查詢字串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始。 |
| (?!pattern) | 正向否定預查(negative assert),在任何不匹配pattern的字串開始處匹配查詢字串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如"Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始。 |
| (?<=pattern) | 反向(look behind)肯定預查,與正向肯定預查類似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。 |
| (?<!pattern) | 反向否定預查,與正向否定預查類似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 則匹配 "zood" 或 "food"。 |
| [xyz] | 字元集合。匹配所包含的任意一個字元。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^xyz] | 負值字元集合。匹配未包含的任意字元。例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。 |
| [a-z] | 字元範圍。匹配指定範圍內的任意字元。例如,'[a-z]' 可以匹配 'a' 到 'z' 範圍內的任意小寫字母字元。 |
| [^a-z] | 負值字元範圍。匹配任何不在指定範圍內的任意字元。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 範圍內的任意字元。 |
| \b | 匹配一個單詞邊界,也就是指單詞和空格間的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非單詞邊界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字元。例如, \cM 匹配一個 Control-M 或回車符。x 的值必須為 A-Z 或 a-z 之一。否則,將 c 視為一個原義的 'c' 字元。 |
| \d | 匹配一個數字字元。等價於 [0-9]。 |
| \D | 匹配一個非數字字元。等價於 [^0-9]。 |
| \f | 匹配一個換頁符。等價於 \x0c 和 \cL。 |
| \n | 匹配一個換行符。等價於 \x0a 和 \cJ。 |
| \r | 匹配一個回車符。等價於 \x0d 和 \cM。 |
| \s | 匹配任何空白字元,包括空格、製表符、換頁符等等。等價於 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字元。等價於 [^ \f\n\r\t\v]。 |
| \t | 匹配一個製表符。等價於 \x09 和 \cI。 |
| \v | 匹配一個垂直製表符。等價於 \x0b 和 \cK。 |
| \w | 匹配字母、數字、下劃線。等價於'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、數字、下劃線。等價於 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 為十六進位制轉義值。十六進位制轉義值必須為確定的兩個數字長。例如,'\x41' 匹配 "A"。'\x041' 則等價於 '\x04' & "1"。正則表示式中可以使用 ASCII 編碼。 |
| \num | 匹配 num,其中 num 是一個正整數。對所獲取的匹配的引用。例如,'(.)\1' 匹配兩個連續的相同字元。 |
| \n | 標識一個八進位制轉義值或一個向後引用。如果 \n 之前至少 n 個獲取的子表示式,則 n 為向後引用。否則,如果 n 為八進位制數字 (0-7),則 n 為一個八進位制轉義值。 |
| \nm | 標識一個八進位制轉義值或一個向後引用。如果 \nm 之前至少有 nm 個獲得子表示式,則 nm 為向後引用。如果 \nm 之前至少有 n 個獲取,則 n 為一個後跟文字 m 的向後引用。如果前面的條件都不滿足,若 n 和 m 均為八進位制數字 (0-7),則 \nm 將匹配八進位制轉義值 nm。 |
| \nml | 如果 n 為八進位制數字 (0-3),且 m 和 l 均為八進位制數字 (0-7),則匹配八進位制轉義值 nml。 |
| \un | 匹配 n,其中 n 是一個用四個十六進位制數字表示的 Unicode 字元。例如, \u00A9 匹配版權符號 (?)。 |
正則表示式從左到右進行計算,並遵循優先順序順序,這與算術表示式非常類似。
相同優先順序的從左到右進行運算,不同優先順序的運算先高後低。下表從最高到最低說明了各種正則表示式運算子的優先順序順序:
| 運算子 | 描述 |
|---|---|
| \ | 轉義符 |
| (), (?:), (?=), [] | 圓括號和方括號 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字元、任何字元 | 定位點和序列(即:位置和順序) |
| | | 替換,"或"操作 字元具有高於替換運算子的優先順序,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",請使用括號建立子表示式,從而產生"(m|f)ood"。 |
基本模式匹配
一切從最基本的開始。模式,是正則表示式最基本的元素,它們是一組描述字串特徵的字元。模式可以很簡單,由普通的字串組成,也可以非常複雜,往往用特殊的字元表示一個範圍內的字元、重複出現,或表示上下文。例如:
^once
這個模式包含一個特殊的字元^,表示該模式只匹配那些以once開頭的字串。例如該模式與字串"once upon a time"匹配,與"There once was a man from NewYork"不匹配。正如如^符號表示開頭一樣,$符號用來匹配那些以給定模式結尾的字串。
bucket$
這個模式與"Who kept all of this cash in a bucket"匹配,與"buckets"不匹配。字元^和$同時使用時,表示精確匹配(字串與模式一樣)。例如:
^bucket$
只匹配字串"bucket"。如果一個模式不包括^和$,那麼它與任何包含該模式的字串匹配。例如:模式
once
與字串
There once was a man from NewYork Who kept all of his cash in a bucket.
是匹配的。
在該模式中的字母(o-n-c-e)是字面的字元,也就是說,他們表示該字母本身,數字也是一樣的。其他一些稍微複雜的字元,如標點符號和白字元(空格、製表符等),要用到轉義序列。所有的轉義序列都用反斜槓(\)打頭。製表符的轉義序列是:\t。所以如果我們要檢測一個字串是否以製表符開頭,可以用這個模式:
^\t
類似的,用\n表示"新行",\r表示回車。其他的特殊符號,可以用在前面加上反斜槓,如反斜槓本身用\\表示,句號.用\.表示,以此類推。
字元簇
在INTERNET的程式中,正則表示式通常用來驗證使用者的輸入。當用戶提交一個FORM以後,要判斷輸入的電話號碼、地址、EMAIL地址、信用卡號碼等是否有效,用普通的基於字面的字元是不夠的。
所以要用一種更自由的描述我們要的模式的辦法,它就是字元簇。要建立一個表示所有母音字元的字元簇,就把所有的母音字元放在一個方括號裡:
[AaEeIiOoUu]
這個模式與任何母音字元匹配,但只能表示一個字元。用連字號可以表示一個字元的範圍,如:
[a-z] //匹配所有的小寫字母 [A-Z] //匹配所有的大寫字母 [a-zA-Z] //匹配所有的字母 [0-9] //匹配所有的數字 [0-9\.\-] //匹配所有的數字,句號和減號 [ \f\r\t\n] //匹配所有的白字元
同樣的,這些也只表示一個字元,這是一個非常重要的。如果要匹配一個由一個小寫字母和一位數字組成的字串,比如"z2"、"t6"或"g7",但不是"ab2"、"r2d3" 或"b52"的話,用這個模式:
^[a-z][0-9]$
儘管[a-z]代表26個字母的範圍,但在這裡它只能與第一個字元是小寫字母的字串匹配。
前面曾經提到^表示字串的開頭,但它還有另外一個含義。當在一組方括號裡使用^是,它表示"非"或"排除"的意思,常常用來剔除某個字元。還用前面的例子,我們要求第一個字元不能是數字:
^[^0-9][0-9]$
這個模式與"&5"、"g7"及"-2"是匹配的,但與"12"、"66"是不匹配的。下面是幾個排除特定字元的例子:
[^a-z] //除了小寫字母以外的所有字元 [^\\\/\^] //除了(\)(/)(^)之外的所有字元 [^\"\'] //除了雙引號(")和單引號(')之外的所有字元
特殊字元"." (點,句號)在正則表示式中用來表示除了"新行"之外的所有字元。所以模式"^.5$"與任何兩個字元的、以數字5結尾和以其他非"新行"字元開頭的字串匹配。模式"."可以匹配任何字串,除了空串和只包括一個"新行"的字串。
PHP的正則表示式有一些內建的通用字元簇,列表如下:
| 字元簇 | 描述 |
|---|---|
| [[:alpha:]] | 任何字母 |
| [[:digit:]] | 任何數字 |
| [[:alnum:]] | 任何字母和數字 |
| [[:space:]] | 任何空白字元 |
| [[:upper:]] | 任何大寫字母 |
| [[:lower:]] | 任何小寫字母 |
| [[:punct:]] | 任何標點符號 |
| [[:xdigit:]] | 任何16進位制的數字,相當於[0-9a-fA-F] |
確定重複出現
到現在為止,你已經知道如何去匹配一個字母或數字,但更多的情況下,可能要匹配一個單詞或一組數字。一個單詞有若干個字母組成,一組數字有若干個單陣列成。跟在字元或字元簇後面的花括號({})用來確定前面的內容的重複出現的次數。
| 字元簇 | 描述 |
|---|---|
| ^[a-zA-Z_]$ | 所有的字母和下劃線 |
| ^[[:alpha:]]{3}$ | 所有的3個字母的單詞 |
| ^a$ | 字母a |
| ^a{4}$ | aaaa |
| ^a{2,4}$ | aa,aaa或aaaa |
| ^a{1,3}$ | a,aa或aaa |
| ^a{2,}$ | 包含多於兩個a的字串 |
| ^a{2,} | 如:aardvark和aaab,但apple不行 |
| a{2,} | 如:baad和aaa,但Nantucket不行 |
| \t{2} | 兩個製表符 |
| .{2} | 所有的兩個字元 |
這些例子描述了花括號的三種不同的用法。一個數字 {x} 的意思是前面的字元或字元簇只出現x次 ;一個數字加逗號 {x,} 的意思是前面的內容出現x或更多的次數 ;兩個數字用逗號分隔的數字 {x,y} 表示 前面的內容至少出現x次,但不超過y次。我們可以把模式擴充套件到更多的單詞或數字:
^[a-zA-Z0-9_]{1,}$ // 所有包含一個以上的字母、數字或下劃線的字串 ^[1-9][0-9]{0,}$ // 所有的正整數 ^\-{0,1}[0-9]{1,}$ // 所有的整數 ^[-]?[0-9]+\.?[0-9]+$ // 所有的浮點數
最後一個例子不太好理解,是嗎?這麼看吧:以一個可選的負號 ([-]?) 開頭 (^)、跟著1個或更多的數字([0-9]+)、和一個小數點(\.)再跟上1個或多個數字([0-9]+),並且後面沒有其他任何東西($)。下面你將知道能夠使用的更為簡單的方法。
特殊字元 ? 與 {0,1} 是相等的,它們都代表著: 0個或1個前面的內容 或 前面的內容是可選的 。所以剛才的例子可以簡化為:
^\-?[0-9]{1,}\.?[0-9]{1,}$
特殊字元 * 與 {0,} 是相等的,它們都代表著 0 個或多個前面的內容 。最後,字元 + 與 {1,} 是相等的,表示 1 個或多個前面的內容 ,所以上面的4個例子可以寫成:
^[a-zA-Z0-9_]+$ // 所有包含一個以上的字母、數字或下劃線的字串 ^[1-9][0-9]*$ // 所有的正整數 ^\-?[0-9]+$ // 所有的整數 ^[-]?[0-9]+(\.[0-9]+)?$ // 所有的浮點數
當然這並不能從技術上降低正則表示式的複雜性,但可以使它們更容易閱讀。
簡單表示式
正則表示式的最簡單形式是在搜尋字串中匹配其本身的單個普通字元。例如,單字元模式,如 A,不論出現在搜尋字串中的何處,它總是匹配字母 A。下面是一些單字元正則表示式模式的示例:
/a/ /7/ /M/
可以將許多單字元組合起來以形成大的表示式。例如,以下正則表示式組合了單字元表示式:a、7 和 M。
/a7M/
請注意,沒有串聯運算子。只須在一個字元後面鍵入另一個字元。
字元匹配
句點 (.) 匹配字串中的各種列印或非列印字元,只有一個字元例外。這個例外就是換行符 (\n)。下面的正則表示式匹配 aac、abc、acc、adc 等等,以及 a1c、a2c、a-c 和 a#c:
/a.c/
若要匹配包含檔名的字串,而句點 (.) 是輸入字串的組成部分,請在正則表示式中的句點前面加反斜槓 (\) 字元。舉例來說明,下面的正則表示式匹配 filename.ext:
/filename\.ext/
這些表示式只讓您匹配"任何"單個字元。可能需要匹配列表中的特定字元組。例如,可能需要查詢用數字表示的章節標題(Chapter 1、Chapter 2 等等)。
中括號表示式
若要建立匹配字元組的一個列表,請在方括號([ 和 ])內放置一個或更多單個字元。當字元括在中括號內時,該列表稱為"中括號表示式"。與在任何別的位置一樣,普通字元在中括號內表示其本身,即,它在輸入文字中匹配一次其本身。大多數特殊字元在中括號表示式內出現時失去它們的意義。不過也有一些例外,如:
- 如果 ] 字元不是第一項,它結束一個列表。若要匹配列表中的 ] 字元,請將它放在第一位,緊跟在開始 [ 後面。
- \ 字元繼續作為轉義符。若要匹配 \ 字元,請使用 \\。
括在中括號表示式中的字元只匹配處於正則表示式中該位置的單個字元。以下正則表示式匹配 Chapter 1、Chapter 2、Chapter 3、Chapter 4 和 Chapter 5:
/Chapter [12345]/
請注意,單詞 Chapter 和後面的空格的位置相對於中括號內的字元是固定的。中括號表示式指定的只是匹配緊跟在單詞 Chapter 和空格後面的單個字元位置的字符集。這是第九個字元位置。
若要使用範圍代替字元本身來表示匹配字元組,請使用連字元 (-) 將範圍中的開始字元和結束字元分開。單個字元的字元值確定範圍內的相對順序。下面的正則表示式包含範圍表示式,該範圍表示式等效於上面顯示的中括號中的列表。
/Chapter [1-5]/
當以這種方式指定範圍時,開始值和結束值兩者都包括在範圍內。注意,還有一點很重要,按 Unicode 排序順序,開始值必須在結束值的前面。
若要在中括號表示式中包括連字元,請採用下列方法之一:
- 用反斜槓將它轉義:
[\-]
- 將連字元放在中括號列表的開始或結尾。下面的表示式匹配所有小寫字母和連字元:
[-a-z] [a-z-]
- 建立一個範圍,在該範圍中,開始字元值小於連字元,而結束字元值等於或大於連字元。下面的兩個正則表示式都滿足這一要求:
[!--] [!-~]
若要查詢不在列表或範圍內的所有字元,請將插入符號 (^) 放在列表的開頭。如果插入字元出現在列表中的其他任何位置,則它匹配其本身。下面的正則表示式匹配1、2、3、4 或 5 之外的任何數字和字元:
/Chapter [^12345]/
在上面的示例中,表示式在第九個位置匹配 1、2、3、4 或 5 之外的任何數字和字元。這樣,例如,Chapter 7 就是一個匹配項,Chapter 9 也是一個匹配項。
上面的表示式可以使用連字元 (-) 來表示:
/Chapter [^1-5]/
中括號表示式的典型用途是指定任何大寫或小寫字母或任何數字的匹配。下面的表示式指定這樣的匹配:
/[A-Za-z0-9]/
替換和分組
替換使用 | 字元來允許在兩個或多個替換選項之間進行選擇。例如,可以擴充套件章節標題正則表示式,以返回比章標題範圍更廣的匹配項。但是,這並不象您可能認為的那樣簡單。替換匹配 | 字元任一側最大的表示式。
您可能認為,下面的表示式匹配出現在行首和行尾、後面跟一個或兩個數字的 Chapter 或 Section:
/^Chapter|Section [1-9][0-9]{0,1}$/
很遺憾,上面的正則表示式要麼匹配行首的單詞 Chapter,要麼匹配行尾的單詞 Section 及跟在其後的任何數字。如果輸入字串是 Chapter 22,那麼上面的表示式只匹配單詞 Chapter。如果輸入字串是 Section 22,那麼該表示式匹配 Section 22。
若要使正則表示式更易於控制,可以使用括號來限制替換的範圍,即,確保它只應用於兩個單詞 Chapter 和 Section。但是,括號也用於建立子表示式,並可能捕獲它們以供以後使用,這一點在有關反向引用的那一節講述。通過在上面的正則表示式的適當位置新增括號,就可以使該正則表示式匹配 Chapter 1 或 Section 3。
下面的正則表示式使用括號來組合 Chapter 和 Section,以便表示式正確地起作用:
/^(Chapter|Section) [1-9][0-9]{0,1}$/
儘管這些表示式正常工作,但 Chapter|Section 周圍的括號還將捕獲兩個匹配字中的任一個供以後使用。由於在上面的表示式中只有一組括號,因此,只有一個被捕獲的"子匹配項"。
在上面的示例中,您只需要使用括號來組合單詞 Chapter 和 Section 之間的選擇。若要防止匹配被儲存以備將來使用,請在括號內正則表示式模式之前放置 ?:。下面的修改提供相同的能力而不儲存子匹配項:
/^(?:Chapter|Section) [1-9][0-9]{0,1}$/
除 ?: 元字元外,兩個其他非捕獲元字元建立被稱為"預測先行"匹配的某些內容。正向預測先行使用 ?= 指定,它匹配處於括號中匹配正則表示式模式的起始點的搜尋字串。反向預測先行使用 ?! 指定,它匹配處於與正則表示式模式不匹配的字串的起始點的搜尋字串。
例如,假設您有一個文件,該文件包含指向 Windows 3.1、Windows 95、Windows 98 和 Windows NT 的引用。再進一步假設,您需要更新該文件,將指向 Windows 95、Windows 98 和 Windows NT 的所有引用更改為 Windows 2000。下面的正則表示式(這是一個正向預測先行的示例)匹配 Windows 95、Windows 98 和 Windows NT:
/Windows(?=95 |98 |NT )/
找到一處匹配後,緊接著就在匹配的文字(不包括預測先行中的字元)之後搜尋下一處匹配。例如,如果上面的表示式匹配 Windows 98,將在 Windows 之後而不是在 98 之後繼續搜尋。
其他示例
下面列出一些正則表示式示例:
| 正則表示式 | 描述 |
|---|---|
| /\b([a-z]+) \1\b/gi | 一個單詞連續出現的位置。 |
| /(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/ | 將一個URL解析為協議、域、埠及相對路徑。 |
| /^(?:Chapter|Section) [1-9][0-9]{0,1}$/ | 定位章節的位置。 |
| /[-a-z]/ | a至z共26個字母再加一個-號。 |
| /ter\b/ | 可匹配chapter,而不能匹配terminal。 |
| /\Bapt/ | 可匹配chapter,而不能匹配aptitude。 |
| /Windows(?=95 |98 |NT )/ | 可匹配Windows95或Windows98或WindowsNT,當找到一個匹配後,從Windows後面開始進行下一次的檢索匹配。 |
| /^\s*$/ | 匹配空行。 |
| /\d{2}-\d{5}/ | 驗證由兩位數字、一個連字元再加 5 位數字組成的 ID 號。 |
| /<\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*>/ | 匹配 HTML 標記。 |