
Selenium&Pytesseract模擬登入+驗證碼識別
驗證碼是爬蟲需要解決的問題,因為很多網站的資料是需要登入成功後才可以獲取的.
驗證碼識別,即圖片識別,很多人都有誤區,覺得這是爬蟲方面的知識,其實是不對的.
驗證碼識別涉及到的知識:人工智慧,模式識別,機器視覺,影象處理.
主要流程:
1 影象採集:就直接通過HTTP抓HTML,然後分析出圖片的url,然後下載儲存就可以了
2 預處理: 檢測是正確的影象格式,轉換到合適的格式,壓縮,剪切出ROI,去除噪音,灰度化,轉換色彩空間這些
3 檢測: 驗證碼識別呢,主要是找出文字所在的主要區域
4 前處理: 驗證碼識別,“一般”要做文字的切割
5 訓練: 通過各種模式識別,機器學習演算法,來挑選和訓練合適數量的訓練集
6 識別: 輸入待識別的處理後的圖片,轉換成分類器需要的輸入格式,然後通過輸出的類和置信度,來判斷大概可能是 哪個字母
Pytesseract--驗證碼識別
1 簡介
Python-tesseract是一款用於光學字元識別(OCR)的python工具,即從圖片中識別出其中嵌入的文字。Python-tesseract是對Google Tesseract-OCR的一層封裝。它也同時可以單獨作為對tesseract引擎的呼叫指令碼,支援使用PIL庫(Python Imaging Library)讀取的各種圖片檔案型別,包括jpeg、png、gif、bmp、tiff和其他格式,。作為指令碼使用它將打印出識別出的文字而非寫入到檔案。所以安裝pytesseract前要先安裝PIL和tesseract-orc這倆依賴庫
2 安裝
PIL安裝 Python平臺的影象處理標準庫
pip3 install pillow
pytesseract安裝,文字識別庫
pip3 install pytesseract
tesseract-ocr安裝,識別引擎
windows:
下載
tesseract-ocr-setup-3.05.02 或者 tesseract-ocr-setup-4.0.0-alpha
linux:
github上面下載對應版本
遇到問題及解決:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path
解決方法:(我是win環境)
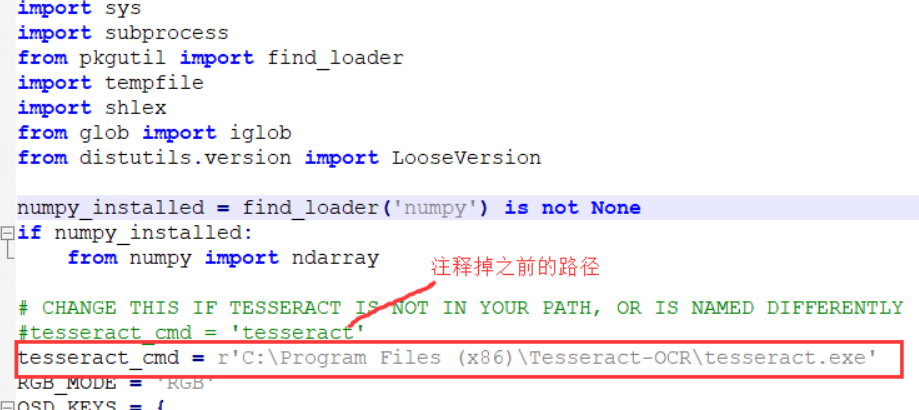
找到tesseract-ocr安裝目錄,複製路徑如: C:\Program Files (x86)\Tesseract-OCR\tesseract.exe
找到pytesseract.py檔案,修改tesseract_cmd的路徑,如下:
環境安裝完後,分析目標網站:
華中科技大學 http://www.hust-snde.com/cms/
需求,每天登陸一次保持活躍度
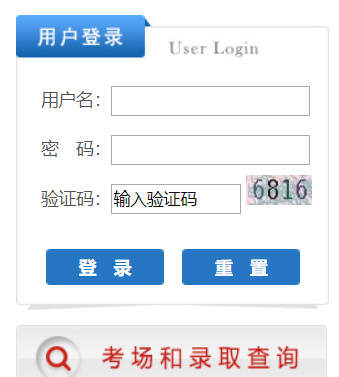
可以看到這個登陸是需要輸入驗證碼的
下面將利用Selenium&Pytesseract模擬登陸+驗證碼識別
完整程式碼如下:
#!/usr/bin/env python
# coding: utf-8
import time
from selenium import webdriver
from PIL import Image
import pytesseract
class LoginSchool(object):
def __init__(self, username, password, url):
self.username = username
self.password = password
self.url = url
self.browser = self.getbrowser()
self.login_school(self.browser)
def getbrowser(self):
chrome_options = webdriver.ChromeOptions()
# 去除警告
chrome_options.add_argument('disable-infobars')
# 無頭模式
# chrome_options.set_headless()
browser = webdriver.Chrome(options=chrome_options,
executable_path=r'D:\chromedriver_2.41\chromedriver.exe')
return browser
def login_school(self, browser):
browser.get(self.url)
time.sleep(3)
# 開啟目標網站,並擷取完整的圖片
browser.get_screenshot_as_file('login.png')
# 找到輸入賬號的input,並輸入賬號
browser.find_element_by_id("loginId").send_keys(self.username)
# 找到輸入密碼的input,並輸入密碼
browser.find_element_by_id("passwd").send_keys(self.password)
# 找到驗證碼img標籤,切圖
img_code = browser.find_element_by_xpath("//div[@class='logif']//img[@id='imgCode']")
time.sleep(3)
# 算出驗證碼的四個點,即驗證碼四個角的座標地址
left = img_code.location['x']
top = img_code.location['y']
right = img_code.location['x'] + img_code.size['width']
bottom = img_code.location['y'] + img_code.size['height']
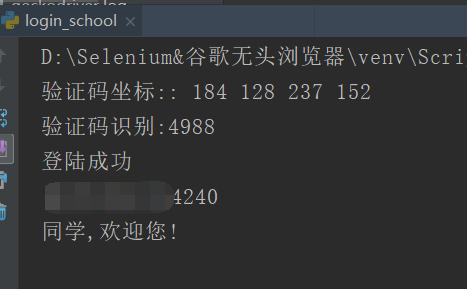
print("驗證碼座標::", left, top, right, bottom)
# 利用python的PIL圖片處理庫,利用座標,切出驗證碼的圖
im = Image.open('login.png')
im = im.crop((left, top, right, bottom))
im.save('code.png')
# 呼叫圖片識別的函式,得到驗證碼
code = self.img_to_str()
# 找到驗證碼的input,並輸入驗證碼
browser.find_element_by_id("authCode").send_keys(code)
# 點選登入按鈕
browser.find_element_by_xpath("//div[@class='loga']/a[text()=' 登 錄']").click()
time.sleep(2)
try:
msg = browser.find_element_by_xpath("//div[@class='user_name']").text
if msg:
print('登陸成功')
print(msg)
except Exception as e:
print('登陸失敗:{}'.format(e))
finally:
time.sleep(1)
browser.quit()
def img_to_str(self):
# 開啟切出的驗證碼code.png
img = Image.open('code.png')
# 利用pytesseract識別出驗證碼
# -psm 8 為識別模式
# -c tessedit_char_whitelist=1234567890 的意思是 識別純數字(0-9)
code = pytesseract.image_to_string(img, config='-psm 8 -c tessedit_char_whitelist=1234567890')
print('驗證碼識別:{}'.format(code))
return code
if __name__ == '__main__':
username = '賬號'
password = '密碼'
url = 'http://www.hust-snde.com/center\
/left_hydl.jsp?url=www.hust-snde.com:80/sso/login_centerLogin.action'
st = LoginSchool(username=username, password=password, url=url)
執行程式:
當前目錄下會生成兩個圖片檔案
login.png 為登陸時的截圖
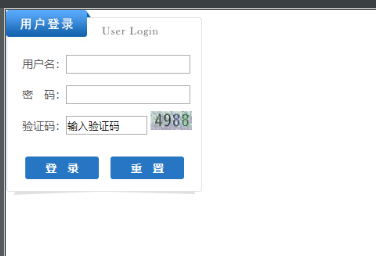
code.png是從上面login.png中切出來的驗證碼圖片

pytesseract識別簡單的驗證碼成功率還行,如果驗證碼有干擾線,噪點之類的就需要對驗證碼圖片進行去除噪音,灰度化,轉換色彩空間這些處理.
如果驗證碼有字型樣式,或者比較複雜,就需要訓練,來提高識別的成功率.
相關推薦
Selenium&Pytesseract模擬登入+驗證碼識別
驗證碼是爬蟲需要解決的問題,因為很多網站的資料是需要登入成功後才可以獲取的. 驗證碼識別,即圖片識別,很多人都有誤區,覺得這是爬蟲方面的知識,其實是不對的. 驗證碼識別涉及到的知識:人工智慧,模式識別,機器視覺,影象處理. 主要流程: 1 影象採集:就直接通過HTTP
Selenium&Pytesseract模擬登入+驗證碼識別
驗證碼是爬蟲需要解決的問題,因為很多網站的資料是需要登入成功後才可以獲取的. 驗證碼識別,即圖片識別,很多人都有誤區,覺得這是爬蟲方面的知識,其實是不對的. 驗證碼識別涉及到的知識:人工智慧,模式識別,機器視覺,影象處理. 主要流程: 1 影象採集:就直接通過HTTP抓HTML,然後分析出圖片的url
python+pillow+pytesseract+Tesseract-OCR驗證碼識別[轉]
安裝 pillow,pytesseract ,安裝該模組之後,還需要安裝 tesseract-ocr 。 (PS:如果安裝了pip,可以python的scripts檔案下,輸入cmd,然後輸入pip install pillow安裝最新版的pillow,如果需要安裝其它版本的則要自己下載
selenium-跳過登入驗證碼
selenium最常見的就是登入,但是登入有個坑,就是驗證碼的問題,關於驗證碼一共四個辦法: 1.讓開發註釋掉驗證碼。 2.讓開發設定一個萬能驗證碼,只要輸入這個驗證碼,就通過。 3.跳過驗證碼直接登入成功。 4.驗證碼識別技術。 第三條寫的很模糊,不過下面就介紹一
Selenium新增Cookie模擬無驗證碼登入
最近爬蟲碰見需要用selenium模擬登入,有驗證碼滑塊+圖片點選驗證,在解決過程中發現一篇很好的示例,雖然是無驗證碼的那種,但是還不錯,先記下來! 程式碼及註釋如下: #!coding=utf-8 import time from selenium import webdriver
linux環境下pytesseract的安裝和央行征信中心的登錄驗證碼識別實戰
int tab 權限 linux a-z 都是 提示 解釋 text 首先是安裝,我參考的是這個 http://blog.csdn.net/xinghun_4/article/details/47860645 我是centos,使用yum yum install pyt
Selenium+Python自動化之如何繞過登入驗證碼
一、使用Fiddler抓包 1.一般登陸網站成功後,會生成一個已登入狀態的cookie,那麼只需要直接把這個值拿到,用selenium進行addCookie操作即可。 2.可以先手動登入一次,然後抓取這個cookie,這裡我們就需要用抓包工具fiddler了 3.先開啟部落格園登入介面,手動輸入賬號和密
Tesseract:識別知乎網站登入驗證碼
機器視覺 從 Google 的無人駕駛汽車到可以識別假鈔的自動售賣機,機器視覺一直都是一個應用廣 泛且具有深遠的影響和雄偉的願景的領域。 我們將重點介紹機器視覺的一個分支:文字識別,介紹如何用一些 Python庫來識別和使用線上圖片中的文字。
【2018.05.11】python3.6+selenium 知乎自動登入+驗證碼 問題
時隔這麼多年,驗證碼問題我解決了,這裡也能寫下,我就是懶得寫。哈哈 #coding = utf-8 ''' 自動登入知乎 出現了驗證碼的問題,待解決...... ''' import time from selenium import webdriver driver = w
postman模擬帶驗證碼登入問題
今天研究一個問題,就是用postman模擬網站的帶驗證碼登入。本文把這一過程做個流水賬式記錄。 我最初的設想是這樣: http是一種無連線無狀態協議,請求相應完畢連線即斷開,由於其無狀態,重複請求的身份認證一般通過session、cookie、url重寫這幾種方式來實現,我
基於Python的Selenium自動化(3)— 實現驗證碼擷取並識別
這些天實在忙的冒煙,一大堆的專案堆在一起,沒日沒夜的加班。加上有些懶惰,學習進度一直沒有太多進展。這篇文章主要介紹前段時間抽空實現的一個功能,希望有需要用到可以得到一點啟發。 基於UI層的自動化,有一些坑在裡面,幾乎幾個每個人都會遇到的,其中之一就是註冊或登入
Python識別平臺登入驗證碼
工作於運維時間長了,安全問題一直是重點。今天來研究一下簡單的驗證碼可能帶來的安全問題。mac python2.7安裝PIL.Image模組mac python Image PIL 要想在python中操作圖片,比如引入PIL(Python Imaging Library)庫。
Python爬蟲之自動登入與驗證碼識別
轉自:http://blog.csdn.net/tobacco5648/article/details/50640691 在用爬蟲爬取網站資料時,有些站點的一些關鍵資料的獲取需要使用賬號登入,這裡可以使用requests傳送登入請求,並用Session物件來自動處理相關
關於Python驗證碼識別安裝PIL、tesseract-ocr與pytesseract模組的錯誤解決
0x00:用Python進行驗證碼識別 近日接觸到了簡單web驗證碼識別的問題,安裝了 1、PIL 2、tesseract-ocr 3、pytesseract模組 0x01:然後是各種錯誤 (1): PIL for x64的不能正常安裝,原因是:
PYTHONpython自動化/selenium/adb/appium/skuli/Airtest(網易剛出的自動化ui框架)/按鍵精靈/自動化測試接單/刷瀏覽量/引流指令碼/註冊機/驗證碼識別介面等等
qq:412905523 selenium 網頁自動化框架,用於開發網頁的自動指令碼/網頁自動化測試/甚至網頁智慧機器人的模組 adb安卓自動化模組,用於開發android的自動指令碼/自動化測試/甚至android智慧機器人的模組(可以說成模組吧) appium
Python3.4 12306 2015年3月驗證碼識別
like target bottom edr ocr extra spl apple creat import ssl import json from PIL import Image import requests import re import urllib.r
python selenium-webdriver 登錄驗證碼的處理(十二)
title strip() main ext ima 大小 ring pass 搭建 很多系統為了防止壞人,會增加各樣形式的驗證碼,做測試最頭痛的莫過於驗證碼的處理,驗證碼的處理一般分為三種方法 1.開發給我們設置一個萬能的驗證碼; 2.開發將驗證碼給屏蔽掉; 3.自己識別
驗證碼識別
code threshold 識別 div out style end gray .cn # -*- coding: utf-8 -*- import urllib.request, urllib.parse from PIL import Image from pyt
前端mockjs模擬圖片驗證碼
attr rand dom 點擊 .cn 創建 log json .get ps:mockjs在進行相同的雙數次請求的時候,會出現請求404的狀況,希望有大佬幫解決下 首先創建dom <img id=‘bbn‘ src="" alt="圖圖"> <b
python之驗證碼識別 特征向量提取和余弦相似性比較
wow gif .get extra time ade upd orm log 0.目錄 1.參考2.沒事畫個流程圖3.完整代碼4.改進方向 1.參考 https://en.wikipedia.org/wiki/Cosine_similarity https://zh.wi