
2 手寫Java LinkedList核心原始碼
上一章我們手寫了ArrayList的核心原始碼,ArrayList底層是用了一個數組來儲存資料,陣列儲存資料的優點就是查詢效率高,但是刪除效率特別低,最壞的情況下需要移動所有的元素。在查詢需求比較重要的情況下可以用ArrayList,如果是刪除操作比較多的情況下,用ArrayList就不太合適了。Java為我們提供了LinkedList,是用連結來實現的,我們今天就來手寫一個QLinkedList,來提示底層是怎麼做的。
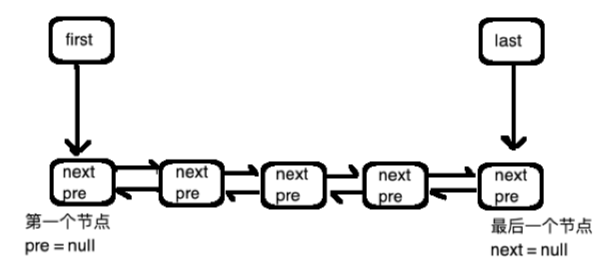
如上圖,底層用一個雙鏈表,另外有兩個指示器,一個指向頭,一個指向尾。
連結串列中的每個節點的next指向下一個節點,同理pre指向上一個節點,第一個節點的pre為null,最後一個節點的next為null
雙鏈表的細節實現較多,尤其是邊界的問題,要十分仔細,LinkedList中設計了許多的小函式,本例中就不設計那麼多的小方法了,直接把最核心的程式碼都寫到一個方法中。以方便揭示核心原理。
下面是完整的QLinkedList的原始碼,註釋很清楚。
public class QLinkedList<T> { private QNode<T> first; //指向頭節點 private QNode<T> last; //指向尾節點 private int size; //節點的個數 //節點類 public static class QNode<T> { T value; //資料 QNode<T> pre; //指向上一個節點 QNode<T> next; //指向下一個節點 public QNode(QNode<T> pre, QNode<T> next, T value) { this.pre = pre; //節點的上一個指向 this.next = next; //節點的下一個指向 this.value = value; //存放的資料 } } public QLinkedList() { //預設是一個空狼連結串列,first,last都為null, 節點個數為0 first = null; last = null; size = 0; } //預設新增到尾 public void add(T e) { addLast(e); } //新增到頭部 public void addFirst(T e) { if (first == null && last == null) { QNode<T> node = new QNode<>(null, null, e); first = node; last = node; } else { QNode<T> node = new QNode<>(null, first, e); first.pre = node; } size++; } //新增到尾部,我們預設新增的都是不為null的資料 public void addLast(T e) { if (e == null) { throw new RuntimeException("e == null"); } //1 連結串列還是空的時候 if (size == 0) { //1.1 新建一個節點,pre,next都為null QNode<T> node = new QNode(null, null, e); //1.2 只有一個節點,first,last都指向null first = node; last = node; //2 連結串列不為空 } else { //2.1 新建一個節點,pre指向last最後一個節點,next為null(因為是最後一個節點) QNode<T> node = new QNode<>(last, null, e); //2.2 同時之前的最後一節點的next 指向新建的node節點 last.next = node; //2.3 然後移動last,讓last指向最後一個節點 last = node; } //新增一個節點後,別忘了節點的總數加 1 size++; } // position 從 0 開始 // 這裡面有個小技巧,可以先判斷一下 position 是大於 size/2 還是小於 size/2 // 如果 position > size / 2 , 說明position是在連結串列的後半段,我們可以從last開始往前遍歷 // 如果 position < size / 2, 說明position是在連結串列的前半段,我們可以從first開始往後遍歷 // 這樣效率會高許多,這也是雙鏈表的意義所在,我們這裡就不這樣做了。直接從前往後遍歷 // 讀者可以自己實現,以加深對連結串列的理解 public T get(int position) { // 不合法的position直接拋異常,讓開發者直接定位問題 if (position < 0 || position > size - 1) { throw new RuntimeException("invalid position"); } // 如果連結串列為空,直接返回null if (size == 0) { return null; } // 如果連結串列只有一個節點,直接返回 // 因為position合法性在前面已經驗證過 // 所以在這裡面不用驗證,一定是0 if(size == 1){ return first.value; } // 注意這個新建的 p 節點,p.next 指向的是 first // 這是為了下面的迴圈,保證 i == 0 的時候,p 指向第一個節點 QNode<T> p = new QNode<>(null, first, null); for (int i = 0; i <= position; i++) { p = p.next; } //如果找到了,就返回value if (p != null) { return p.value; } //否則返回 null return null; } // 返回連結串列的節點總個數 // 注意first和last節點只是幫助我們方便操作的 // size可不包括first,last public int size() { return size; } // 刪除一個元素,這裡傳的引數是 T e ,我們也可以傳position進行刪除,這裡就不作演示了 // 可以先呼叫上面的get()方法,返回對應的值,再呼叫此方法 // 讀者可以自己實現 public T remove(T e) { //1 不合法,拋異常 if (e == null) { throw new RuntimeException("e == null"); } //2 連結串列為空,返回 null if (size == 0) { return null; } //2 如果連結串列只有一個節點 if (size == 1) { QNode<T> node = first; //3 如果相等,刪除節點 size-- ,並把first,last賦值為null if(e == node.value || e.equals(node.value)){ first = last = null; size--; return node.value; }else { //4 不相等,返回null return null; } } // 如果連結串列大於1個節點,我們從前往後找value等於e的節點 // 1 查詢, 和get()方法一樣,注意p的next指向first QNode<T> p = new QNode<>(null, first, null); boolean find = false; for (int i = 0; i < size; i++) { p = p.next; if (p != null && (e == p.value || e.equals(p.value))) { find = true; break; } } // 2 如果找到了 if (find) { // 2.1 如果找到的節點是最後一個節點 // 刪除的是最後一個 if (p.next == null) { //2.2 改變last的值,指向p的前一個節點 last = p.pre; //2.3 p的前一個節點,變成了最後一個節點,所以,前一個節點的next值賦值為null p.pre.next = null; //2.4 把p.pre賦值為null,已經沒有用了 p.pre = null; //2.5 別忘了節點個數減1 size--; //2.6 返回刪除的節點的value return p.value; //3.1 如果刪除的是第一個節點(p.pre == null就表明是第一個節點) } else if (p.pre == null) { //3.2 改變first的指向,指向p的下一個節點 first = p.next; //3.3 p的下一個節點變成了第一個節點,需要把p的下一個節點的pre指向為null p.next.pre = null; //3.4 p.next沒有用了 p.next = null; //3.5 別忘了節點個數減1 size--; //3.6 返回刪除的節點的value return p.value; // 4 如果刪除的不是第一個也不是最後一個,是中間的某一個,這種情況最簡單 } else { //4.1 p的上一個節點的next需要指向p的下一個節點 p.pre.next = p.next; //4.2 p 的下一個節點的pre需要指向p的上一個節點 p.next.pre = p.pre; //4.3 此時p無用了,把p的pre,next賦值為null //這時候不需要調整first,last的位置 p.pre = null; p.next = null; //4.4 別忘了節點個數減1 size--; //4.5 返回刪除的節點的value return p.value; } } //沒有找到與e相等的節點,直接返回null return null; } }
我們來測試一下QLinkedList,測試程式碼如下:
public static void main(String[] args) { QLinkedList<String> list = new QLinkedList<>(); list.add("one"); list.add("two"); list.add("three"); list.add("four"); System.out.println(list.size); for (int i = 0; i < list.size; i++) { System.out.println(list.get(i)); } System.out.println("==================="); System.out.println(list.remove("two")); System.out.println(list.size); for (int i = 0; i < list.size; i++) { System.out.println(list.get(i)); } }
輸出如下:
4
one
two
three
four
===================
two
3
one
three
four由此可見我們的QLinkedList可以正常的add,get,size,remove了。
建議可以參考一下JDK中的LinkedList。以加深對LinkedList的理解
明天手寫HashMap的核心原始碼實現
相關推薦
2 手寫Java LinkedList核心原始碼
上一章我們手寫了ArrayList的核心原始碼,ArrayList底層是用了一個數組來儲存資料,陣列儲存資料的優點就是查詢效率高,但是刪除效率特別低,最壞的情況下需要移動所有的元素。在查詢需求比較重要的情況下可以用ArrayList,如果是刪除操作比較多的情況下,用ArrayList就不太合適了。Java為我
4.2 手寫Java PriorityQueue 核心原始碼
上一節介紹了PriorityQueue的原理,先來簡單的回顧一下 PriorityQueue 的原理 以最大堆為例來介紹 PriorityQueue是用一棵完全二叉樹實現的。 不但是棵完全二叉樹,而且樹中的每個根節點都比它的左右兩個孩子節點元素大 PriorityQueue底層是用陣列來儲存
5 手寫Java Stack 核心原始碼
Stack是Java中常用的資料結構之一,Stack具有"後進先出(LIFO)"的性質。 只能在一端進行插入或者刪除,即壓棧與出棧 棧的實現比較簡單,性質也簡單。可以用一個數組來實現棧結構。 入棧的時候,只在陣列尾部插入 出棧的時候,只在陣列尾部刪除** 我們來看一下Stack的用法 :如
6 手寫Java LinkedHashMap 核心原始碼
概述 LinkedHashMap是Java中常用的資料結構之一,安卓中的LruCache快取,底層使用的就是LinkedHashMap,LRU(Least Recently Used)演算法,即最近最少使用演算法,核心思想就是當快取滿時,會優先淘汰那些近期最少使用的快取物件 LruCache的快取演算法
3 手寫Java HashMap核心原始碼
手寫Java HashMap核心原始碼 上一章手寫LinkedList核心原始碼,本章我們來手寫Java HashMap的核心原始碼。 我們來先了解一下HashMap的原理。HashMap 字面意思 hash + map,map是對映的意思,HashMap就是用hash進行對映的意思。不明白?沒關係。我們來具
4.1 手寫Java PriorityQueue 核原始碼
本章先講解優先順序佇列和二叉堆的結構。下一篇程式碼實現 從一個需求開始 假設有這樣一個需求:在一個子執行緒中,不停的從一個佇列中取出一個任務,執行這個任務,直到這個任務處理完畢,再取出下一個任務,再執行。 其實和 Android 的 Handler 機制中的 Looper 不停的從 MessageQue
原始碼分析 | 手寫mybait-spring核心功能(乾貨好文一次學會工廠bean、類代理、bean註冊的使用)
 作者:小傅哥 部落格:[https://bugstack.cn](https://bugstack.cn) - `彙總系
(手寫)mybatis 核心配置文件和接口不在同一包下的解決方案
內置 中間 configure idea pan 數據源配置 uil 基礎 主目錄 smart-sh-mybatis項目app.xml文件中此處配置為: 1 <!-- 從整合包裏找,org.mybatis:mybatis-spring:1.2.4 -->
spring事物(2)-----手寫spring註解事務&&事務傳播行為
一,spring事務的註解 1.1,spring自帶的@Transactional例子 package com.qingruihappy1.dao; import org.springframework.beans.factory.annotation.Autowired; imp
REDIS (15)手寫Java Redis客戶端(1)RESP協議分析(未完)
一直對Jedis有點興趣, 現在靜下心來抽空看看redis客戶端和消費端是怎麼連線的 1. 對Jedis的get命令抓包 傳送 接收 可見是明文協議,0d 0a 是 \r\n我們找下文件 redis 序列化協議 2. 模仿協議內容傳送並接收內容 2.1 傳統BIO
【python與機器學習入門1】KNN(k近鄰)演算法2 手寫識別系統
參考部落格:超詳細的機器學習python入門knn乾貨 (po主Jack-Cui 參考書籍:《機器學習實戰》——第二章 KNN入門第二彈——手寫識別系統demo ——《機器學習實戰》第二章2.3 手寫識別系統 &
java集合核心原始碼01——ArrayList
首先呢,對於ArrayList,相當於一個動態陣列,裡面可以儲存重複資料,並且支援隨機訪問,不是執行緒安全的。對於更多的底層東西,且聽分解。 開啟原始碼,先看繼承了哪些類,實現了哪些介面,然後繼承的這些類或介面是否還有父類,一直深挖到頂部 public class ArrayList
2 手寫實現SpringMVC,第二節:自定義註解及反射賦值
還是回到最終要實現的效果。 可以發現,這裡面使用了大量的自定義註解,並且還有autuwire的屬性也需要被賦值(Spring的IOC功能)。 先來建立自定義註解 注意,根據不同的註解使用的範圍來定義@Target,譬如Controller,Service能註解到類,R
1.事件委託的原理以及優缺點 2. 手寫原生js實現事件代理,並要求相容瀏覽器
Q:事件的委託(代理 Delegated Events)的原理以及優缺點 A:委託(代理)事件是那些被繫結到父級元素的事件,但是隻有當滿足一定匹配條件時才會被挪。這是靠事件的冒泡機制來實現的, 優點是: (1)可以大量節省記憶體佔用,減少事件註冊,比如在table上
Spring學習之——手寫Mini版Spring原始碼
前言 Sping的生態圈已經非常大了,很多時候對Spring的理解都是在會用的階段,想要理解其設計思想卻無從下手。前些天看了某某學院的關於Spring學習的相關視訊,有幾篇講到手寫Spring原始碼,感覺有些地方還是說的挺好的,讓博主對Spring的理解又多了一些,於是在業餘時間也按照視訊講解實現一遍Spri
原始碼分析之基於LinkedList手寫HahMap(二)
package com.mayikt.extLinkedListHashMap; import java.util.LinkedList; import java.util.concurrent.ConcurrentHashMap; /** * 基於linkedList實現hashMap *
Java手寫LinkedList 應用資料結構之雙向連結串列
作為Java程式設計師,紮實的資料結構演算法能力是必須的 LinkedList理解的最好方式是,自己手動實現它 ArrayList和LinkedList是順序儲存結構和鏈式儲存結構的表在java語言中的實現. ArrayList提供了一種可增長陣
攜程系統架構師帶你手寫spring mvc,解讀spring核心原始碼!
講師簡介: James老師 系統架構師、專案經理 十餘年Java經驗,曾就職於攜程、人人網等一線網際網路公司,專注於java領域,精通軟體架構設計,對於高併發、高效能服務有深刻的見解, 在服務化基礎架構和微服務技術有大量的建設和設計經驗。 課程內容: 1.為什麼讀Spr
1 手寫ArrayList核心原始碼
手寫ArrayList核心原始碼 ArrayList是Java中常用的資料結構,不光有ArrayList,還有LinkedList,HashMap,LinkedHashMap,HashSet,Queue,PriorityQueue等等,我們將手寫這些常用的資料結構的核心原始碼,用盡量少的程式碼來揭示核心原理。
爬蟲入門 手寫一個Java爬蟲
fun sts 重試 功能 bool 內核 ftw private 查找 本文內容 淶源於 羅剛 老師的 書籍 << 自己動手寫網絡爬蟲一書 >> ; 本文將介紹 1: 網絡爬蟲的是做什麽的? 2: 手動寫一個簡單的網絡爬蟲; 1: 網絡爬蟲是做