
統計學習方法c++實現之四 決策樹
決策樹
前言
決策樹是一種基本的分類和迴歸演算法,書中主要是討論了分類的決策樹。決策樹在每一個結點分支規則是一種if-then規則,即滿足某種條件就繼續搜尋左子樹,不符合就去右子樹,看起來是用二叉樹實現對吧,實際的CART決策樹就是二叉樹,等會再介紹。現在先來看看決策樹的理論部分。程式碼地址https://github.com/bBobxx/statistical-learning/blob/master/src/decisiontree.cpp
決策樹相關理論
決策樹的學習通常包括三個部分:特徵選擇, 決策樹生成和決策樹修剪。
特徵選擇
我們拋開煩人的公式和術語,用通俗的思想(沒辦法,本人只有通俗的思想)來理解一下,現在給你很多資料,有很多類,每個資料有n維的特徵,怎麼分?最簡單的,不如來個全連線神經網路,把資料丟進去,讓模型自己去學習去,恩.....這個辦法可能是準確率最高的,但是我們這裡學習的是決策樹,而且有些場景根本不需要神經網路也可以分類的很準確,現在讓我們用決策樹解決這個問題。
首先,面對n維特徵,和k個類別,彷彿無從下手。咋辦呢,笨一點的辦法,就從第一個特徵開始,如果第一個特徵有m個不同取值,那我就按這個特徵取值把資料分成m份,對這份特徵子集,我再選第二個特徵,第二個特徵比如有l個不同取值,那麼對於m個子集,每個又可以最多分出l個子集(最多而不是一定,因為m某個子集中的資料的第二維特徵可能取不全l個值),那麼現在我們最多有\(m\times l\) 個子集,然後是第三維特徵......直到第n維特徵或者某個子集中的資料類別幾乎一樣我們就停止。對於這種分法很明顯確實是個樹結構對吧,只不過你的樹可能是這樣子的:

不好意思,弄錯了,一般樹結構是這樣子的:

思路很簡單,但是過程很複雜對吧,沒錯,這就是決策樹,但是如果真寫成上面這樣也太沒效率了,比如說,現在給你很多人的資料,讓你分出是男是女,特徵有這麼幾個:身高,體重,頭髮長短,身份證上的性別。沒錯最後一個特徵一般不會給出的。現在開始按照上面的思路分類,就分10000個數據吧,身高的取值有十種,就當做150到190取十個數吧,體重先不談,如果從身高這個特徵開始分就能把你分吐血。聰明的同學(應該是不笨的)一眼就能看出來,我直接用最後一個特徵,一下子就分出來了,就算沒有最後這個特徵,我用頭髮長短這個也可以很好的分。
沒錯,看出特徵選擇
基尼指數:\(Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2)\)
其中,A代表某一維特徵,D代表的資料集合,根據A是否取a將D分為\(D_1\) 和\(D_2\)兩個子集,\(|D|,|D_1|,|D_2|\)分別代表各自的數量。
其中,\(Gini(D) = \sum_{k=1}^{K}\frac{|C_k|}{|D|}(1-\frac{|C_k|}{|D|})\)
\(C_k\)代表某一類,\(\frac{|C_k|}{|D|}\)代表這個集合中樣本是第k類的概率。
基尼指數越大,表示樣本集合的不確定性越大,我們在選取A的時候肯定希望分完後集合越確定越好,所以以後在進行特徵選擇的時候就需要選取基尼指數最小的那個特徵。
決策樹(CART)生成演算法
- 對於當前根節點Root,對現有的樣本集D,對所有的特徵\(A_i\)的所有可能取值\(a_j\)計算基尼指數,選擇使基尼指數最小的\(A_i\)和\(a_j\),根據樣本點對\(A_i=a_j\)的測試為“是”或“否”將D分為\(D_1\)和\(D_2\)。
- \(D_1\)作為根節點Root的左子樹的根節點Root_L的樣本集,\(D_2\)作為根節點Root的右子樹的根節點Root_R的樣本集。
- 重複1,2直到結點中樣本個數小於閾值,或樣本集基本屬於同一類,或者沒有更多特徵(代表已經將所有的特徵都過一遍了)。
CART剪枝
請自行看書,反正我也沒實現。
決策樹的c++實現
程式碼結構
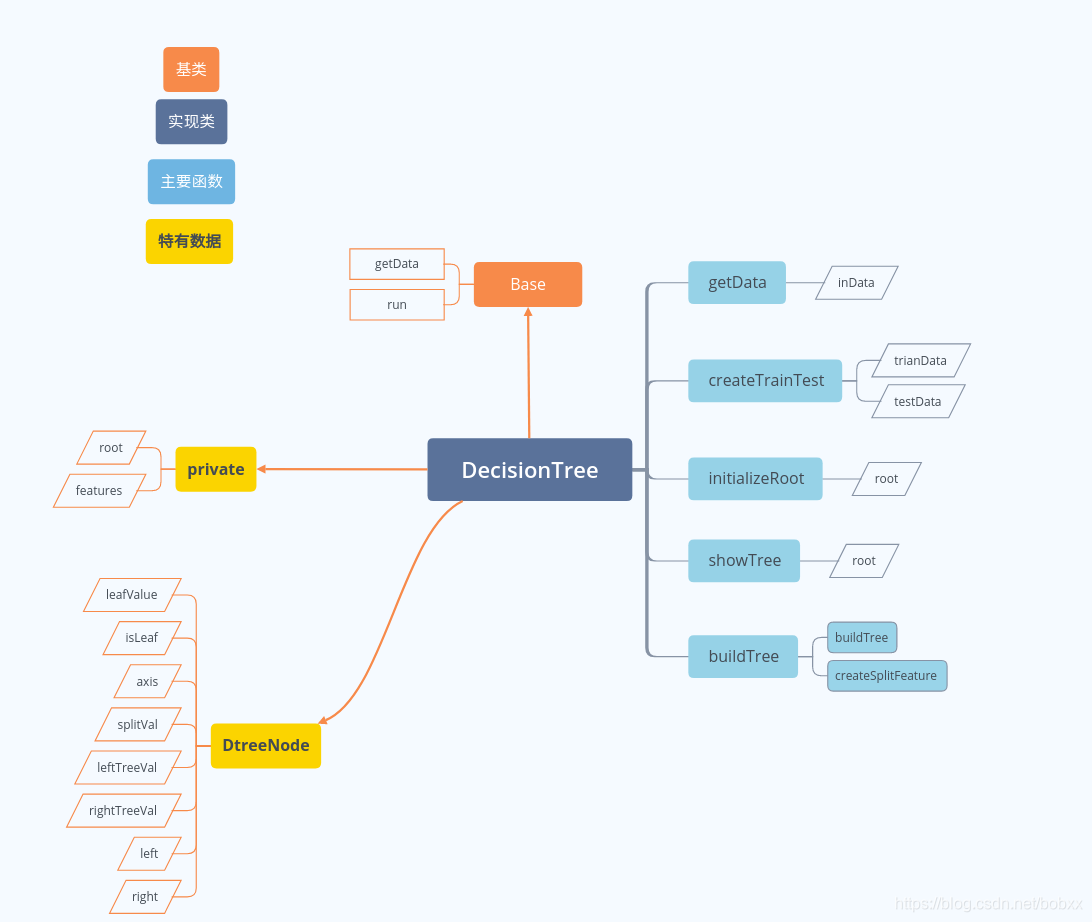
實現
這裡只展示如何確定分割的特徵和值
pair<int, double> DecisionTree::createSplitFeature(vector<vector<double >>& valRange){
priority_queue<pair<double, pair<int, double>>, vector<pair<double, pair<int, double>>>, std::greater<pair<double, pair<int, double>>>> minheap;
//pair<double, pair<int, double>> first value is Gini value, second pair (pair<int, double>) first value is split
//axis, second value is split value
vector<map<double, int>> dataDivByFeature(indim); //vector size is num of axis, map's key is the value of feature, map's value is
//num belong to feature'value
vector<set<double>> featureVal(indim); //store value for each axis
vector<map<pair<double, double>, int>> datDivByFC(indim); //vector size is num of axis, map's key is the feature value and class value, map's value is
//num belong to that feature value and class
set<double> cls; //store num of class
for(const auto& featureId:features) {
if (featureId<0)
continue;
map<double, int> dataDivByF;
map<pair<double, double>, int> dtDivFC;
set<double> fVal;
for (auto& data:valRange){ //below data[featureId] is the value of one feature axis, data.back() is class value
cls.insert(data.back());
fVal.insert(data[featureId]);
if (dataDivByF.count(data[featureId]))
dataDivByF[data[featureId]] += 1;
else
dataDivByF[data[featureId]] = 0;
if (dtDivFC.count(std::make_pair(data[featureId], data.back())))
dtDivFC[std::make_pair(data[featureId], data.back())] += 1;
else
dtDivFC[std::make_pair(data[featureId], data.back())] = 0;
}
featureVal[featureId] = fVal;
dataDivByFeature[featureId] = dataDivByF;
datDivByFC[featureId] = dtDivFC;
}
for (auto& featureId: features) { // for each feature axis
if (featureId<0)
continue;
for (auto& feVal: featureVal[featureId]){ //for each feature value
double gini1 = 0 ;
double gini2 = 0 ;
double prob1 = dataDivByFeature[featureId][feVal]/double(valRange.size());
double prob2 = 1 - prob1;
for (auto& c : cls){ //for each class
double pro1 = double(datDivByFC[featureId][std::make_pair(feVal, c)])/dataDivByFeature[featureId][feVal];
gini1 += pro1*(1-pro1);
int numC = 0;
for (auto& feVal2: featureVal[featureId])
numC += datDivByFC[featureId][std::make_pair(feVal2, c)];
double pro2 = double(numC-datDivByFC[featureId][std::make_pair(feVal, c)])/(valRange.size()-dataDivByFeature[featureId][feVal]);
gini2 += pro2*(1-pro2);
}
double gini = prob1*gini1+prob2*gini2;
minheap.push(std::make_pair(gini, std::make_pair(featureId, feVal)));
}
}
features[minheap.top().second.first]=-1;
return minheap.top().second;
}這裡使用迴圈巢狀計算符合條件的資料的數量,效率很低,有更好方法的同學麻煩告知一下,叩拜~