
CMU開源:多目標人體關鍵點實時檢測
OpenPose是一個利用OpenCV和Caffe並以C++寫成的開源庫,用來實現多執行緒的多人關鍵點實時檢測,作者包括Gines Hidalgo,Zhe Cao,Tomas Simon,Shih-En Wei,Hanbyul Joo以及Yaser Sheikh。
即將加入(但是已經實現!)身體+手勢+人臉估計展示:

儘管該庫使用了Caffe,但是程式碼還是很容易向其他框架(如Tensorflow 或者Torch 等)中移植。如果你實現了任何這方面的程式碼,請發出合併請求我們會很樂意在該庫中新增你的實現。
OpenPose對於自由的非商業用途的使用是免費的,同時也可以在這種情況下被重新發布。請檢視證書瞭解詳情。如果有商業用途請聯絡作者。
OpenPose庫的主要功能性:
-
多人15或18關鍵點身體位姿估計和渲染:
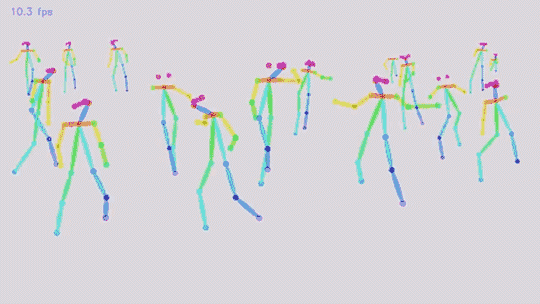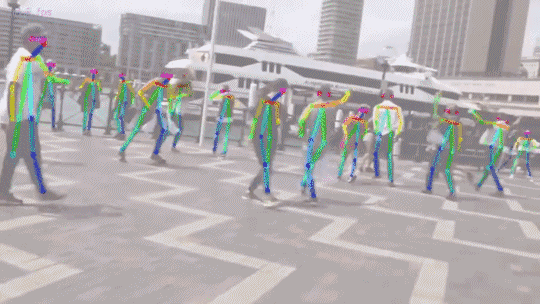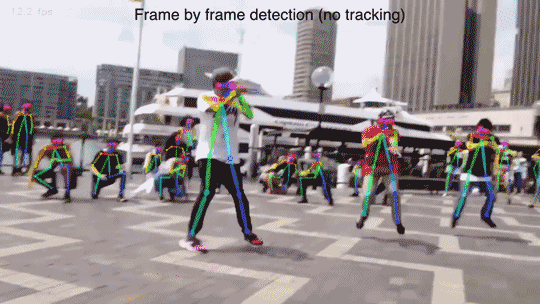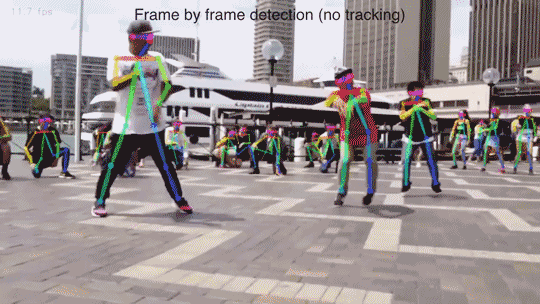
-
多人2*21關鍵點手勢估計和渲染(未來1-2月內開源!)

-
多人70關鍵點人臉估計和渲染(未來2-3月內開源!)

-
靈活並且易於配置的多執行緒模組。
-
影象,視訊以及網路相機讀取器。
-
能夠以多種格式(JSON,XML,PNG,JPG,...)儲存和載入結果。
-
用於結果視覺化的小型顯示視窗以及GUI。
-
所有這些功能性都封裝進了一個易於使用的OpenPose Wrapper類中。
姿態估計的成果基於ECCV 2016樣例"RealtimeMultiperson
Pose Estimation",
ECCV 2016姿態估計視訊
如何安裝:
安裝步驟詳見Github內的:doc/installation.md檔案。
如何快速上手:
大部分使用者用例不需要對該庫有太深入的瞭解,這樣的使用者可能只能夠使用Demo或者簡單的OpenPoes封裝。因此你大可不必太在意OpenPose庫中的細節。
樣例:
如果在你的用例中你只是想處理一個影象或視訊又或者網路相機資料夾並顯示或者儲存位姿結果。
那麼你不必在意OpenPose庫的實現細節同時只要閱讀doc/demo_overview.md
OpenPose封裝:
在你的用例中如果你打算讀取某一特定的影象格式並且/或者新增某個特定的後處理函式並且/或者實現你自己的顯示或儲存功能。
(幾乎可以)不用理會該庫本身的實現,只要看一下examples/tutorial_wrapper/.中關於Wrapper的教程即可。
注意:你並不需要修改OpenPose原始碼或者例程,這樣你將來就能隨時無需修改你的程式碼直接升級OpenPose庫。你可以在examples/user_code/中建立你自定義的程式碼並在OpenPose資料夾下使用make all命令編譯它。
OpenPose庫:
在你的用例中如果你想要改變內部函式並且/或者擴充套件它的功能性。首先,請先看一眼樣例以及OpenPose封裝。其次,閱讀以下兩個小節:OpenPose概覽和功能性擴充套件。
1.OpenPose概覽:在doc/library_overview.md中學習關於我們庫原始碼的基礎。
2.功能性擴充套件:在doc/library_extend_functionality.md中學習如何擴充套件我們的庫。
3.新增一個額外的模組:在doc/library_add_new_module.md中學習如何新增一個額外的模組。
Doxygen文件自動生成
你可以通過執行如下命令來生成文件。文件將會在此doc/doxygen/html/index.html生成。你只需要雙擊就可以開啟它(你的預設瀏覽器會自動顯示它)。
cd doc/doxygen doc_autogeneration.doxygen
如何輸出:
1.輸出格式
這裡有兩種可替換的方法用來儲存身體各部位的位置資訊(x,y,score)。標誌write_pose使用中cv::FileStorage的預設格式儲存(JSON,XML和YML)。然而,JSON格式只有OpenCV3.0以後的版本才支援。因此,標誌位write_pose_json專門用來將人體位姿資料以自定義的JSON格式儲存。這樣一來,每一個JSON檔案都有一個people物件陣列,其中的每個物件都具有一個body_parts陣列,該陣列中包含了身體各部位的位置資訊和檢測置信度,其格式為x1,y1,c1,x2,y2,c2,...座標x和y可以被歸一化至區間[0,1],[-1,1],[0,源尺寸],[0,輸出尺寸],等等,這取決於標誌位scale_mode。另外,c值是位於區間[0,1]的置信度。
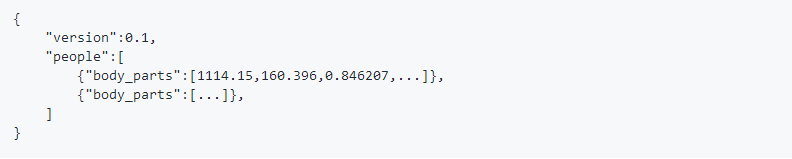
至於身體部位關鍵點的順序,無論是COCO(18個身體部位)還是MPI(15個身體部位),都是由標頭檔案include/openpose/pose/poseParameters.hpp中的POSE_BODY_PART_MAPPING來描述的。拿COCO格式舉例:

對於熱點圖的儲存格式,並不是獨立儲存67張熱點圖(18個身體部位+背景+2*19個PAF檔案),而是將這些圖垂直拼接起來形成一個巨大的(寬*熱點圖數量)*(高)矩陣。也就是說該庫將熱點圖按列拼接起來。比如,向量[0,單個熱點圖寬]包含了第一張熱點圖,向量[單個熱點圖寬度+1,2*單個熱點圖寬]包含了第二章熱點圖,等等。要注意,有些顯示工具在給定的尺寸下不能顯示結果影象。然而,Chrome和Firefox能夠恰當地開啟他們。
儲存的順序是身體部位+背景+PAF檔案。其中的任何一類資訊都可以用程式的標誌位遮蔽掉。如果背景被遮蔽了,那麼最終的影象將會是身體部位和PAF資訊的組合。身體部位資訊和背景遵從POSE_COCO_BODY_PARTS或POSE_MPI_BODY_PARTS中的順序,同時PAF資訊遵循標頭檔案poseParameters.hpp中POSE_BODY_PART_PAIRS指定的順序。比如,對於COCO格式:
POSE_COCO_PAIRS {1,2, 1,5, 2,3, 3,4, 5,6, 6,7, 1,8, 8,9, 9,10, 1,11, 11,12, 12,13, 1,0, 0,14, 14,16, 0,15, 15,17, 2,16, 5,17};
其中每一個索引都是POSE_COCO_BODY_PARTS中相應身體部位的鍵值,比如0對應”Neck”,1對應”RShould”,諸如此類。
2.讀取儲存的結果
我們使用標準格式(JSON,XML,PNG,JPG,...)來儲存結果,這樣一來之後就有很多框架可以讀取它們,但是你也可以直接在include/openpose/filestream.hpp上使用我們的函式。特別是使用loadData(針對JSON,XML和YML檔案)和loadImage(針對例如PNG或者JPG這樣的影象格式)將資料載入到cv::Mat格式中。
3.給我們傳送反饋
對於研究目的,我們的庫是開源的,同時我們也想要持續改善它!所以請讓我們知道如果...
1.你發現了任何bug(在功能性或者速度方面)
2.你向某些類或者新的Worker子類中添加了某種功能性,我們可能會將其糅合進我們的庫中
3.你知道如何提高速度或者讓這個庫的任何地方變得簡潔
4.你有關於可能的功能性的需求
5.諸如此類
請在GibHub上評論或者發出合併請求!我們會盡快答覆你!
4.自定義Caffe
我們僅僅修改了一些Caffe的彙編標誌和一點點細節。你可以使用你自己的Caffe版本,下面是我們新增和修改的檔案:
1.新增的檔案:install_caffe.sh;以及Makefile.config.Ubuntu14.example,Makefile.config.Ubuntu16.example,Makefile.config.Ubuntu14_cuda_7.example和Makefile.config.Ubuntu16_cuda_7.example(從Makefile.config.example中抽取)。基本上你必須使能cuDNN。
2.修改的檔案:在Makefile中搜索“#OpenPose:”來查詢修改過的程式碼。總的來說我們添加了C++11標誌來避免一些舊版機器上的問題。
3.可選項-刪除Caffe檔案:Makefile.config.example。
4.最後,在你的Caffe版本上執行make all && make distribute命令並在./Makefile.config.UbuntuX.example(其中X是14或16,取決於你的Ubuntu版本)中修改Caffe目錄空間的變數,設定CAFFE_DIR引數為Caffe資料夾中include和lib所在的路徑。
引用
如果這對你的研究有所幫助請在你的出版物中引用本文。
姿態估計:

論文地址:https://arxiv.org/abs/1611.08050
GitHub地址:https://github.com/CMU-Perceptual-Computing-Lab/openpose#output
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields 是CVPR2017的一篇論文,作者稱是世界上第一個基於深度學習的實時多人二維姿態估計。
優酷演示地址:連結
前幾天作者公佈了windows下的程式碼,下面來說說如何配置:
英文配置地址可以參考作者的github:https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/installation.md#windows
首先你得裝好CUDA8,cudnn5.1,vs2015. 其他版本都不行,只有vs2015可以裝
作者說要下載Python 2.4.13 64 bits,其實我的anaconda2也可以(2.7的那個版本)
cmake,ninja(我下載了,但是貌似沒用到)
下載windows版的 openpose https://github.com/CMU-Perceptual-Computing-Lab/openpose/tree/windows
並解壓,我放在D盤。下載model ,作者給了2個,
http://posefs1.perception.cs.cmu.edu/Users/tsimon/Projects/coco/data/models/coco/pose_iter_440000.caffemodel (精度高,速度較慢)下載後放到 D:\openpose-windows\models\pose\coco下
http://posefs1.perception.cs.cmu.edu/Users/tsimon/Projects/coco/data/models/mpi/pose_iter_160000.caffemodel(速度快,但是精度低)
下載後放到D:\openpose-windows\models\pose\mpi\下
開啟D:\openpose-windows\3rdparty\caffe\caffe-windows\scripts 下的build_win.cmd,開始編譯。
提示出錯hash 什麼不匹配的,原因是網的問題,https://github-production-release-asset-2e65be.s3.amazonaws.com/39632178/8053cdd0-0068-11e7-8b60-c46f580c47e0?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20170531%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20170531T072412Z&X-Amz-Expires=300&X-Amz-Signature=1860d1ab5ee6598f6a93e6230d1b74a09200e95e22d72021043f5176b9d73de3&X-Amz-SignedHeaders=host&actor_id=28419338&response-content-disposition=attachment%3B%20filename%3Dlibraries_v140_x64_py27_1.1.0.tar.bz2&response-content-type=application%2Foctet-stream 下載後複製到D:\openpose-windows\3rdparty\caffe\dependencies\download下。再編譯,等待半個小時,就會編譯完畢。(若出現no c compiler could be found 請參考我另一篇博文)
接著 開啟 D:\openpose-windows\windows_project\OpenPose.sln 右鍵點選OpenPoseDemo 生成,此時會報錯。提示 找不到D:\openpose-windows\3rdparty\lib\Release caffe.lib 。其實它在 D:\openpose-windows\3rdparty\caffe\lib\Release下,路徑的問題。
把release下的的兩個檔案 放到D:\openpose-windows\3rdparty\lib\Release下 就OK 了。 再編譯 又提示錯誤,說找不到pythoh27(其實也可以在build_win.cmd下 把Python的路徑改成你自己的python路徑,這樣這裡就不會報錯。)右鍵OpenPoseDemo,屬性,聯結器,常規,附加庫目錄,把你的python路徑加進去,我為了防止出錯,把2個路徑都加了。

再生成,就成功了。順便再生成一下openpose(貌似沒什麼東西生成)
此時你會在D:\openpose-windows\windows_project\x64\Release下找到OpenPoseDemo.exe。但是你雙擊它會提示你缺少各種東西。
作者說把{openpose_folder}\3rdparty\caffe\caffe-windows\build\install\bin\ 下的所有DLL檔案複製到{openpose_folder}\windows_project\x64\Release.下
但是我沒有找到這個路徑。我把D:\openpose-windows\3rdparty\caffe\caffe-windows\scripts\build\tools\Release下的所有DLL檔案複製過去。
再把{}openpose_folder}\3rdparty\caffe\dependencies\libraries_v140_x64_py27_1.1.0\libraries\x64\vc14\bin\下的
opencv_ffmpeg310_64.dll, opencv_video310.dll 和opencv_videoio310.複製到{openpose_folder}\windows_project\x64\Release下。
此時開啟OpenPoseDemo.exe,發現還是缺少一些東西,我在D:\openpose-windows 下搜尋缺少的檔案,並複製到{openpose_folder}\windows_project\x64\Release下。
此時,發現oppenpose可以打開了,但是提示找不到model,其實是路徑的問題,開啟OpenPose.sln ,雙擊OpenPoseDemo下的openpose.cpp.
在第66行,手動設定models的絕對路徑,比如我的是這個:

儲存,並再次編譯。發現oppenpose終於可以打開了!
有些同學可能會提示報錯 out of memory (比如說我),其實就是視訊記憶體不夠,爆視訊記憶體了(1G GT650M傷不起啊 )
)
開啟OpenPose.sln
,雙擊OpenPoseDemo下的openpose.cpp.
在第67行、68行 修改網路的大小,我設定成如上的大小,1G視訊記憶體也可以跑了。
大功告成!
如果想在視訊下跑,可以在cmd下使用如下命令:windows_project\x64\Release\OpenPoseDemo.exe --video examples/media/video.avi
如果是圖片的話bin\OpenPoseDemo.exe --image_dir examples/media/
相關推薦
CMU開源:多目標人體關鍵點實時檢測
OpenPose是一個利用OpenCV和Caffe並以C++寫成的開源庫,用來實現多執行緒的多人關鍵點實時檢測,作者包括Gines Hidalgo,Zhe Cao,Tomas Simon,Shih-En Wei,Hanbyul Joo以及Yaser Sheikh。
基於粒子群優化的分類特徵選擇:多目標方法
#引用 ##LaTex @ARTICLE{6381531, author={B. Xue and M. Zhang and W. N. Browne}, journal={IEEE Transactions on Cybernetics}, title={Par
MOTS:多目標跟蹤和分割論文翻譯
MOTS:多目標跟蹤和分割論文翻譯 摘要: 本文將目前流行的多目標跟蹤技術擴充套件到多目標跟蹤與分割技術(MOTS)。為了實現這個目標,我們使用半自動化的標註為兩個現有的跟蹤資料集建立了密集的畫素級標註。我們的新標註包含了10870個視訊幀中977個不同物件(汽車和行人)的65,213個畫素掩膜。為了
開源|2017 CVPR(Oral Paper) 多目標實時體態估測 專案開源
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
論文學習筆記:曹哲 實時多人人體姿態識別 CVPR2017
最近學習了曹哲的這篇Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,認真讀了,也看了曹哲直播的視訊,雖然程式還是看不懂,但也算是學到東西了,寫個筆記記錄一下,其實大部分也就是直接
DICOM:DICOM開源庫多線程分析之“ThreadPoolQueue in fo-dicom”
lower win man 例如 fec called sof current 資源下載 背景: 上篇博文介紹了dcm4chee中使用的Leader/Follower線程池模型。主要目的是節省上下文切換,提高運行效率。本博文同屬【DICOM開源庫多線程
微軟愛開源:向Linux社群開放60000多項專利
10月10日,微軟在部落格中宣佈正式加入開放創新網路(Open Invention Network, 簡稱“OIN”),向所有開源專利聯盟的成員開放其專利組合。 微軟的加入意味著,旗下60000多項專利將免費開源給Linux系統,幫助其發展。這60000多項已授權的寶貴專利
BERT 現已開源:最先進的 NLP 預訓練技術,支援中文和更多語言
文 / Jacob Devlin 和 Ming-Wei Chang, Research Scientists, Google AI Language 缺少訓練資料是自然語言處理(Natural Language Processing, NLP)面臨的最大挑戰之一。由
太極鏈:多層開源技術協議
太極鏈核心和生態系統 在最底層,太極鏈是一個多層的、基於密碼學的開源技術協議。它的不同功能模組通過設計進行了全面的整合,作為一個整體,它是一個建立和部署現代化的去中心化應用的綜合平臺。 它被設計為一個通用的去中心化平臺,擁有一套完整的、可以擴充套件其功能的工具。 雖然,太極
閱讀Book: MultiObjective using Evolutionary Algorithms (2) -- Multi-Objective Optimization: 各種解釋多目標
1. 多目標相關的概念 In a single-objective optimization problem, the task is tp find one solution (Except in some specific multi-model (除了多峰函式) which optim
閱讀Book: MultiObjective using Evolutionary Algorithms (1) --prologue 單目標和多目標的不同
1. 日常購買車we為例子, 假設使用者在舒適度和花費進行權衡。 各種pin'品牌的車的花費與舒適度的曲線如下:、 自己覺得: 或許在我們的shen生活中就是不存在最完美的,就是一種鞋子要穿到自己的腳上才知道才知道合適不合適。我們沒有辦法,讓所有的事物,都是統一的規格尺度。 &
【原始碼】NSGA - II:一種基於進化演算法的多目標優化函式
NSGA-II是一種著名的多目標優化演算法。 NSGA-II is a very famous multi-objective optimization algorithm. 相應的函式為nsga_2(pop,gen)。 The function is nsga_2(pop,g
多目標跟蹤綜述:Multiple Object Tracking: A Literature Review
摘要 多目標跟蹤因其學術和商業潛力,在計算機視覺中逐漸備受關注。儘管如今已經有多種多樣的方法來處理這個課題,但諸如目標重疊、外觀劇變等問題仍然是它所面臨的重大挑戰。在本文中,我們將提供關於多目標跟蹤最綜合、最新的資訊,檢驗當下最新技術突破,並對未來研究提出幾
閱讀Book: MultiObjective using Evolutionary Algorithms (1) --prologue 單目標和多目標的不同
1. 日常購買車we為例子, 假設使用者在舒適度和花費進行權衡。 各種pin'品牌的車的花費與舒適度的曲線如下:、 自己覺得: 或許在我們的shen生活中就是不存在最完美的,就是一種鞋子要穿到自
Sort多目標跟蹤中的:指派問題與匈牙利解法
多目標跟蹤中SORT演算法的理解 在跟蹤之前,對所有目標已經完成檢測,實現了特徵建模過程。 1. 第一幀進來時,以檢測到的目標初始化並建立新的跟蹤器,標註id。 2. 後面幀進來時,先到卡爾曼濾波器中得到由前面幀box產生的狀態預測和協方差預測。求跟蹤器所有目標狀態
Matlab多目標跟蹤示例(一):Motion-Based Multiple Object Tracking
簡單來說,基於動態的多目標跟蹤主要分為兩步:①在每幀中檢測出移動的目標②將檢測到的目標與之前正在跟蹤的同一個目標關聯起來第①步又分為:a)使用混合高斯模型做背景減法,得到移動的目標。(前後景分離)b)通過形態學操作消除前景掩膜中的噪聲。c)通過blob分析檢測連通域,得到對應的
Druid:一個用於大資料實時處理的開源分散式系統
Druid是一個用於大資料實時查詢和分析的高容錯、高效能開源分散式系統,旨在快速處理大規模的資料,並能夠實現快速查詢和分析。尤其是當發生程式碼部署、機器故障以及其他產品系統遇到宕機等情況時,Druid仍能夠保持100%正常執行。建立Druid的最初意圖主要是為了解決查詢延遲問題,當時試圖使用Hadoop來實現
人臉跟蹤:POI多目標跟蹤
網上已有很多關於MOT的文章,此係列僅為個人閱讀隨筆,便於初學者的共同成長。若希望詳細瞭解,建議閱讀原文。 本文是tracking by detection 方法進行多目標跟蹤的文章,最大的特點是使用了state-of-the-art的detection和feature
多目標跟蹤競賽結果摘要:Multiple Object Tracking Challenge 2017 Results
測評專案: MOT17第一名:A Novel Multi-Detector Fusion Framework for Multi-Object Tracking 摘要:由於僅用一個檢