
資料結構與演算法學習筆記——貪心演算法(greedy algorithm)
理解貪心演算法:
假設我們有一個可以容納100kg物品的揹包,可以裝各種物品。我們有以下5種豆子,每種豆子的總量和總價值都各不相同。為了讓揹包中所裝物品的總價值最大,我們如何選擇在揹包中裝哪些豆子?每種豆子又該裝多少呢?
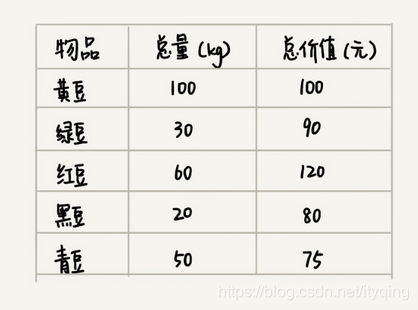
先算一算每個物品的單價,按照單價由高到低依次來裝就好了。單價從高到低排列,依次是:黑豆、綠豆、紅豆、青豆、黃豆,所以,我們可以往揹包裡裝20kg黑豆、30kg綠豆、50kg紅豆。
相關推薦
資料結構與演算法學習筆記——貪心演算法(greedy algorithm)
理解貪心演算法: 假設我們有一個可以容納100kg物品的揹包,可以裝各種物品。我們有以下5種豆子,每種豆子的總量和總價值都各不相同。為了讓揹包中所裝物品的總價值最大,我們如何選擇在揹包中裝哪些豆子?每種豆子又該裝多少呢?
python資料分析與挖掘學習筆記(6)-電商網站資料分析及商品自動推薦實戰與關聯規則演算法
這一節主要涉及到的資料探勘演算法是關聯規則及Apriori演算法。 由此展開電商網站資料分析模型的構建和電商網站商品自動推薦的實現,並擴充套件到協同過濾演算法。 關聯規則最有名的故事就是啤酒與尿布的故事,非常有效地說明了關聯規則在知識發現和資料探勘中起的作用和意義。 其中有
野生前端的資料結構練習(12)貪心演算法
參考程式碼可見:https://github.com/dashnowords/blogs/tree/master/Structure/GreedyAlogrithm 一.貪心演算法 貪心演算法屬於比較簡單的演算法,它總是會選擇當下最優解,而不去考慮單次遞迴時是否會對未來造成影響,也就是說不考
ARM體系結構與程式設計學習筆記3
第三章 ARM指令集介紹 ARM的指令集可以分為6類,即跳轉指令,資料處理指令,程式狀態暫存器,Load/Store指令,協處理器指令,和異常中斷產生指令。 1:跳轉指令: 長跳轉: 直接向PC暫存器中寫入目標地址值可以實現4G地址空間的任意跳轉。MOV LR,PC 1:B:跳轉指令 2;B
ARM體系結構與程式設計學習筆記2
1:ARM指令分類 1:ARM指令集可以分為跳轉指令,資料處理指令,程式狀態暫存器(PSR)傳輸指令,load/Store指令,協處理指令和異常中斷產生指令 2:ARM指令集字長為固定的32位,一條典型的ARM指令編碼格式如下 opcode:指令助記符; 如ADD表示演算法加操作指令 c
ARM體系結構與程式設計學習筆記1
第一章 ARM概述與其基本程式設計模型 一、ARM資料型別 1、字(Word):在ARM體系結構中,字的長度為32位。 2、半字(Half-Word):在ARM體系結構中,半字的長度為16位。 3、位元組(Byte):在ARM體系結構中,位元組的長度為8位。 二、ARM處理器儲存
資料結構之圖學習筆記
一、圖的定義: 圖(Graph)是由頂點的有窮非空集合和頂點之間邊的集合組成,通常表示為:G(V,E),其中,G表示一個圖,V表示圖G中頂點的集合,E是圖G中的邊集合。 a.線性表中的資料元素我們稱為元素,樹中資料元素稱為節點,而圖中的
Python資料分析與挖掘學習筆記(2)使用pandas進行資料匯入
一、匯入pandas模組: import pandas as pda 二、匯入CSV格式資料: #資料匯入 i=pda.read_csv("E:/hexun.csv") 可對匯入的資料進行統計以及按列排序: #統計 i.describe() #排序 i
Python資料分析與挖掘學習筆記(4)淘寶商品資料探索與清洗實戰
一、相關理論: 資料探索的核心: (1)資料質量分析(跟資料清洗密切聯絡) (2)資料特徵分析(分佈、對比、週期性、相關性、常見統計量等) 資料清洗的步驟: (1)缺失值處理(通過describe與len直接發現、通過0資料發現) (2)異常值處理(通過散點圖發現
Python資料分析與挖掘學習筆記(5)資料規範化與資料離散化實戰
一、相關理論: 1、資料規範化的常見方法: (1)離差標準化(最小-最大標準化)--消除量綱(單位)影響以及變異大小因素的影響。(最小-最大標準化) x1=(x-min)/(max-min) (2)標準差標準化--消除單
Python-資料分析與展示學習筆記(二)
前言 此次學習的主題是圍繞機器學習所需的python庫展開。 在學完了python的基礎語法後,瞭解到機器學習還需要掌握一些python進階知識:利用python爬取資料、資料分析與展示。 於是在網上找了許多教程,發現北理工嵩天老師的pyth
演算法學習日記————貪心演算法(一)
“人心不足蛇吞象” 一個貪心演算法總是做出當前最好的選擇,也就是說,它期望通過區域性最優選擇從而得到全域性最優選擇 在貪心演算法中需要注意的問題: 沒有後悔藥。一旦做出選擇,不可以反悔。 有可能得到的不是最優解,而是最優解的近似解。 選擇什麼樣的貪心策略決定演算
資料結構-基本概念學習筆記
1.1 資料(資訊的載體); 資料元素(資料的基本單位,由若干資料項組成); 資料物件(相同性質的資料元素的集合); 資料型別(原子、結構、抽象); 抽象資料型別(ADT,通常有資料物件,資料關係,基本操作來表示); 資料結構(
Python資料分析與挖掘學習筆記一:庫和環境搭建
概念介紹: 資料分析: 用適當的統計分析方法對收集來的大量資料進行詳細研究和概括總結,以求最大化地發揮資料的作用,提取有用資訊和形成結論 資料探勘: 從大量資料中通過演算法搜尋隱藏於其中資訊的過程. 資料分析的三大作用:現狀分析、原因分析、預測分析。 資料分析的流程
第123講:Hadoop叢集管理之Namenode目錄元資料結構詳解學習筆記
第123講:Hadoop叢集管理之Namenode目錄元資料結構詳解學習筆記 hadoop-2.x的叢集管理與hadoop-1.x有很大不同 hdfs-site.xml: dfs.replication dfs.namenode.name.dir 存放namenode元資
python資料分析與挖掘學習筆記(3)_小說文字資料探勘part1
這一節主要是對小說文字資料的挖掘專案。 文字挖掘的一個重要的應用是進行站點的個性化推薦。將使用者感興趣的資訊推送給對應的使用者,可以更好地發揮該資訊的價值。比如,我們常常會在瀏覽網頁的時候看到相關的廣告是我們感興趣的,新聞推送的是我們感興趣的文章,閱讀小說推薦的是我們想看的
資料結構之樹學習筆記
一.樹中的節點關係和一些概念 1.基本概念 樹中節點數可以使用n來表示 空樹:n為0的樹 節點的度:指節點的子節點數目,如上圖中B節點為一度,D節點為三度 父子兄弟關係:如上圖中D是G的父節點,H是D的子節點,G是H的兄弟節點,I是J的堂兄弟節點(這個概念不重要) 樹的層次:還是如上圖,A節點為第一層,B、
資料結構與演算法之美專欄學習筆記-排序(上)
排序方法 氣泡排序、插入排序、選擇排序、快速排序、歸併排序、計數排序、基數排序、桶排序。 複雜度歸類 氣泡排序、插入排序、選擇排序 O(n^2) 快速排序、歸併排序 O(nlogn) 計數排序、基數排序、桶排序 O(n) 演算法的執行效率 1. 最
資料結構與演算法之美專欄學習筆記-排序(下)
分治思想 分治思想 分治,顧明思意就是分而治之,將一個大問題分解成小的子問題來解決,小的子問題解決了,大問題也就解決了。 分治與遞迴的區別 分治演算法一般都用遞迴來實現的。分治是一種解決問題的處理思想,遞迴是一種程式設計技巧。 歸併排序 演算法原理 歸併的思想 先把陣列從中間分
資料結構與演算法學習筆記之後進先出的“桶”
前言 棧最為一種的常用的資料結構,用“桶”來形容最合適不過;今天我們就來學習一下 正文 一、棧的定義? 1.“後進先出,先進後出”的資料結構。 2.從操作特性來看,是一種“操作受限”的線性表,只可以在一端插入和刪除資料。 二、為什麼需要棧?