
python資料分析與挖掘學習筆記(6)-電商網站資料分析及商品自動推薦實戰與關聯規則演算法
這一節主要涉及到的資料探勘演算法是關聯規則及Apriori演算法。
由此展開電商網站資料分析模型的構建和電商網站商品自動推薦的實現,並擴充套件到協同過濾演算法。
關聯規則最有名的故事就是啤酒與尿布的故事,非常有效地說明了關聯規則在知識發現和資料探勘中起的作用和意義。
其中有幾個專用詞的概念:
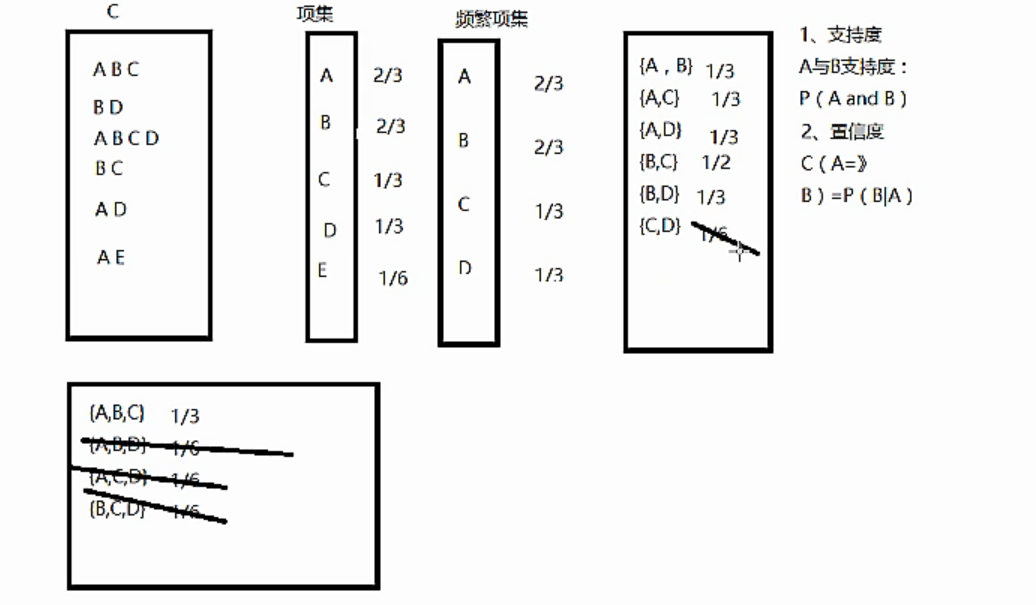
支援度:A與B的支援度Support(A->B)表示為P(A and B)。支援度揭示了A與B同時出現的概率。如果A與B同時出現的概率小,說明A與B的關係不大;如果A與B同時出現的非常頻繁,則說明A與B總是相關的。
置信度:如果A發生那麼B發生的概率。Confidence(A->B)=support(A->B)/suport(A)。置信度揭示了A出現時,B是否也會出現或有多大概率出現。如果置信度度為100%,則A和B可以捆綁銷售了。如果置信度太低,則說明A的出現與B是否出現關係不大。
項集:項的集合稱為項集。包含k個項的項集稱為k-項集。
如果存在一條關聯規則,它的支援度和置信度都大於預先定義好的最小支援度與置信度,我們就稱它為強關聯規則。強關聯規則就可以用來了解項之間的隱藏關係。所以關聯分析的主要目的就是為了尋找強關聯規則,而Apriori演算法則主要用來幫助尋找強關聯規則。
Apriori演算法的步驟如下:
1.自連接獲取候選集。第一輪的候選集就是資料集D中的項,而其他輪次的候選集則是由前一輪次頻繁集自連線得到(頻繁集由候選集剪枝得到)。
2.對於候選集進行剪枝。如何剪枝呢?候選集的每一條記錄T,如果它的支援度小於最小支援度,那麼就會被剪掉;此外,如果一條記錄T,它的子集有不是頻繁集的,也會被剪掉。
一個實際的粗糙例子是:
Apriori的實現如下:
# -*- coding: utf-8 -*- from __future__ import print_function import pandas as pd # 自定義連線函式,用於實現L_{k-1}到C_k的連線 def connect_string(x, ms): x = list(map(lambda i: sorted(i.split(ms)), x)) l = len(x[0]) r = [] for i in range(len(x)): for j in range(i, len(x)): if x[i][:l - 1] == x[j][:l - 1] and x[i][l - 1] != x[j][l - 1]: r.append(x[i][:l - 1] + sorted([x[j][l - 1], x[i][l - 1]])) return r # 尋找關聯規則的函式 def find_rule(d, support, confidence, ms=u'--'): result = pd.DataFrame(index=['support', 'confidence']) # 定義輸出結果 support_series = 1.0 * d.sum() / len(d) # 支援度序列 column = list(support_series[support_series > support].index) # 初步根據支援度篩選 k = 0 while len(column) > 1: k = k + 1 print(u'\n正在進行第%s次搜尋...' % k) column = connect_string(column, ms) print(u'數目:%s...' % len(column)) sf = lambda i: d[i].prod(axis=1, numeric_only=True) # 新一批支援度的計算函式 # 建立連線資料,這一步耗時、耗記憶體最嚴重。當資料集較大時,可以考慮並行運算優化。 d_2 = pd.DataFrame(list(map(sf, column)), index=[ms.join(i) for i in column]).T support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum() / len(d) # 計算連線後的支援度 column = list(support_series_2[support_series_2 > support].index) # 新一輪支援度篩選 support_series = support_series.append(support_series_2) column2 = [] for i in column: # 遍歷可能的推理,如{A,B,C}究竟是A+B-->C還是B+C-->A還是C+A-->B? i = i.split(ms) for j in range(len(i)): column2.append(i[:j] + i[j + 1:] + i[j:j + 1]) cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) # 定義置信度序列 for i in column2: # 計算置信度序列 cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))] / support_series[ms.join(i[:len(i) - 1])] for i in cofidence_series[cofidence_series > confidence].index: # 置信度篩選 result[i] = 0.0 result[i]['confidence'] = cofidence_series[i] result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))] result = result.T.sort(['confidence', 'support'], ascending=False) # 結果整理,輸出 print(u'\n結果為:') print(result) return result
主要為連線函式和尋找關聯規則的函式,其中需要定義support和confidence的值,需要折中選擇這兩個值,保證得到滿意的結果。
ms為連線符。就是一個迴圈連線和查詢的過程。
下面是使用Apriori演算法實現商品個性化的推薦。
# coding = utf-8
# Apriori演算法,實現見apriori模組,以下為應用
# 使用Apriori演算法實現商品個性化推薦
from apriori import *
import pandas as pda
filename = "/home/hadoop/Downloads/lesson_buy.xls"
dataframe = pda.read_excel(filename, sheetname=0, header=None)
# 轉化一下資料
change = lambda x: pda.Series(1, index=x[pda.notnull(x)])
mapok = map(change, dataframe.as_matrix())
data = pda.DataFrame(list(mapok)).fillna(0)
print(data)
# 臨界支援度、置信度設定
support = 0.2
confidence = 0.5
# 使用Apriori演算法計算關聯結果
find_rule(data, support, confidence, "-->")下面是得到的結果:
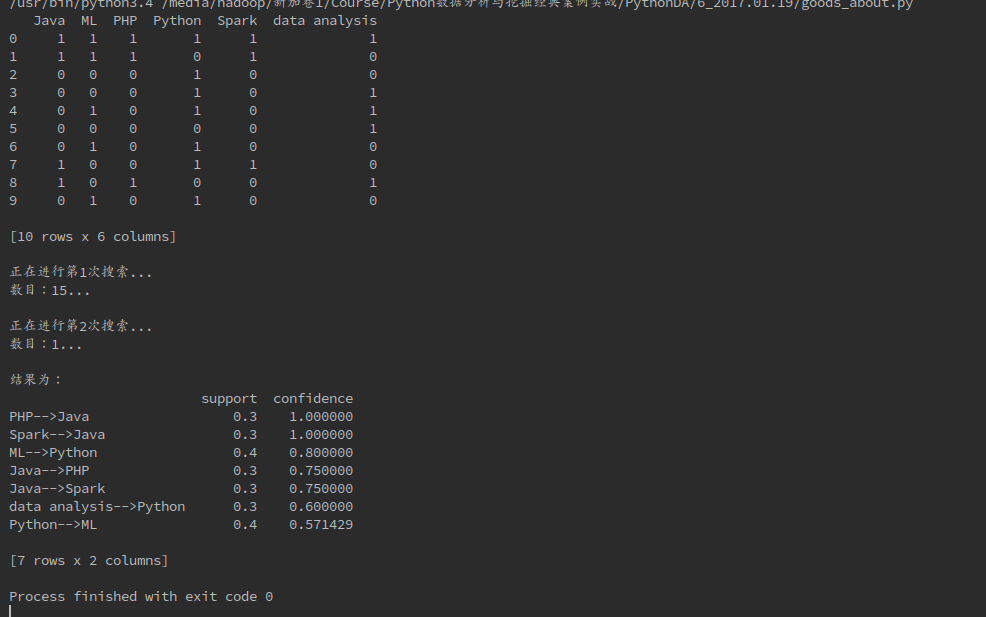
可以通過不同嘗試不同的置信度和支援度來獲得更可靠的結果。
下面提一下協同過濾演算法:

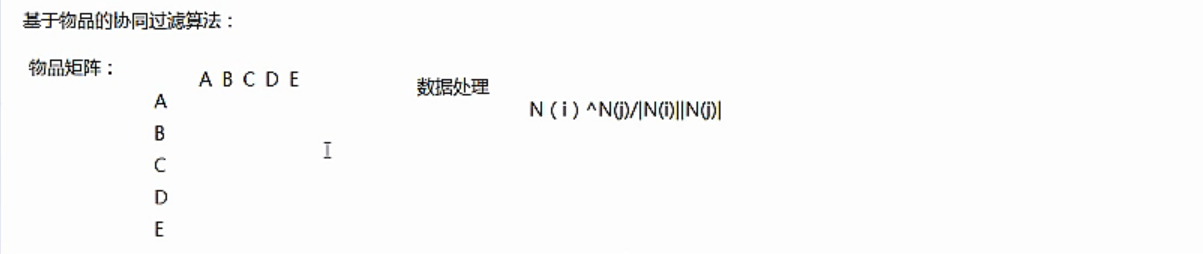
協同過濾演算法是將每個點轉換為概率的形式,根據倒排表,得到矩陣,計算出同一使用者對不同物品感興趣的概率之後,可以將相似品味的使用者喜歡的物品推薦給該使用者。比如,上面計算對於使用者2,分別對A,D,E感興趣的概率,然後取最大的推薦給該使用者。其中每一個物品的計算方法是求得對該物品感興趣的使用者與使用者2之間的相似度,比如,計算使用者2對D物品感興趣的概率,則計算使用者2與對D感興趣的使用者1,4,5之間的相似度w之和,其中w的計算方法為餘弦公式的計算,w(2,1) = |使用者1和使用者2的交集|/|使用者1|×|使用者2|.其中|.|為求模。
協同過濾演算法分為兩種,一種是基於使用者的協同過濾演算法,第二種是基於物品的協同過濾演算法。