
Tensorflow中常用的函式總結(一)
1、tf.shape()和x.get_shape().as_list()的使用
(1) tf.shape()
先說tf.shape()很顯然這個是獲取張量的大小的,用法無需多說,直接上例子吧!
import tensorflow as tf
import numpy as np
a_array=np.array([[1,2,3],[4,5,6]])
b_list=[[1,2,3],[3,4,5]]
c_tensor=tf.constant([[1,2,3],[4,5,6]])
with tf.Session() as sess:
print(sess.run(tf.shape(a_array)))
print(sess.run(tf.shape(b_list)))
print(sess.run(tf.shape(c_tensor)))
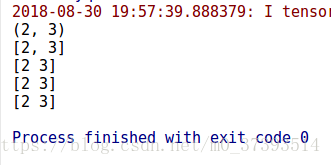
結果:

(2)x.get_shape().as_list()
這個簡單說明一下,x.get_shape(),只有tensor才可以使用這種方法,返回的是一個元組。
import tensorflow as tf
import numpy as np
a_array=np.array([[1,2,3],[4,5,6]])
b_list=[[1,2,3],[3,4,5]]
c_tensor=tf.constant([[1,2,3],[4,5,6]])
print(c_tensor.get_shape())
print(c_tensor.get_shape().as_list())
with tf.Session() as sess:
print(sess.run(tf.shape(a_array)))
print(sess.run(tf.shape(b_list)))
print(sess.run(tf.shape(c_tensor)))
結果:可見只能用於tensor來返回shape,但是是一個元組,需要通過as_list()的操作轉換成list.
2、tf.get_variable()和tf.Variable()的區別
tf.get_variable(name, shape, initializer): name就是變數的名稱,shape是變數的維度,initializer是變數初始化的方式,
3、tf.nn.bias_add和tf.add、tf.add_n
Args: x: A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `string`. y: A `Tensor`. Must have the same type as `x`. name: A name for the operation (optional). Returns: A `Tensor`. Has the same type as `x`.
Adds `bias` to `value`.
This is (mostly) a special case of `tf.add` where `bias` is restricted to 1-D. Broadcasting is supported, so `value` may have any number of dimensions. Unlike `tf.add`, the type of `bias` is allowed to differ from `value` in the case where both types are quantized.
Args:
value: A `Tensor` with type `float`, `double`, `int64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, or `complex128`.
bias: A 1-D `Tensor` with size matching the last dimension of `value`. Must be the same type as `value` unless `value` is a quantized type, in which case a different quantized type may be used.
data_format: A string. 'NHWC' and 'NCHW' are supported.
name: A name for the operation (optional).
Returns:
A `Tensor` with the same type as `value`.3)tf.add_n(inputs,name=None)
函式是實現一個列表的元素的相加。就是輸入的物件是一個列表,列表裡的元素可以是向量,
4)tf.add 和 tf.nn.bias_add 的區別
- tf.nn.bias_add 是 tf.add 中的一個特例,tf.nn.bias_add 中 bias 一定是 1 維的張量;
- tf.nn.bias_add 中 value 最後一維長度和 bias 的長度一定得一樣;
- tf.nn.bias_add 中,當 value 是 quantized type 時,bias 可以取不同的 quantized type。但什麼是 quantized type?TensorFlow API 中 tf.DType 頁面顯示,’tf.qint8’、’tf.quint8’、’tf.qint16’、’tf.quint16’、’tf.qint32’型別就是Quantized type。但這些類別具體如何使用並不知曉。
- tf.add(tf.matmul(x, w), b)
- tf.matmul(x, w) + b

4、tf.nn.bias_add和tf.add、tf.add_n
tf.nn.relu(features, name = None)
max(features, 0)將矩陣中每行的非最大值置0
5、tf.nn.bias_add和tf.add、tf.add_n
tf.nn.max_pool(value, ksize, strides, padding, name=None)
引數是四個,和卷積很類似:
第一個引數value:需要池化的輸入,一般池化層接在卷積層後面,所以輸入通常是feature map,依然是[batch, height, width, channels]這樣的shape
第二個引數ksize:池化視窗的大小,取一個四維向量,一般是[1, height, width, 1],因為我們不想在batch和channels上做池化,所以這兩個維度設為了1
第三個引數strides:和卷積類似,視窗在每一個維度上滑動的步長,一般也是[1, stride,stride, 1]
第四個引數padding:和卷積類似,可以取'VALID' 或者'SAME'
返回一個Tensor,型別不變,shape仍然是[batch, height, width, channels]這種形式
6、 tf.reshape
原始碼:x_image = tf.reshape(x, [-1, 28, 28, 1])這裡是將一組影象矩陣x重建為新的矩陣,該新矩陣的維數為(a,28,28,1),其中-1表示a由實際情況來定。
例如,x是一組影象的矩陣(假設是50張,大小為56×56),則執行x_image = tf.reshape(x, [-1, 28, 28, 1])可以計算a=50×56×56/28/28/1=200。即x_image的維數為(200,28,28,1)。
7、tf.nn.softmax(logits,axis=None,name=None,dim=None)
通過Softmax迴歸,將logistic的預測二分類的概率的問題推廣到了n分類的概率的問題。通過公式
可以看出當月分類的個數變為2時,Softmax迴歸又退化為logistic迴歸問題。
下面的幾行程式碼說明一下用法
import tensorflow as tf
A = [1.0,2.0,3.0,4.0,5.0,6.0]
with tf.Session() as sess:
print sess.run(tf.nn.softmax(A))
結果
[ 0.00426978 0.01160646 0.03154963 0.08576079 0.23312201 0.63369131]
其中所有輸出的和為1
softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), axis)
- logits:
A non-empty Tensor. 一個非空張量
Must be one of the following types: half, float32, float64.必須是以下型別之一:half, float32, float64 - axis:
The dimension softmax would be performed on. 將被執行的softmax維度
The default is -1 which indicates the last dimension.預設值是-1,表示最後一個維度。 - name:
A name for the operation (optional).操作的名稱(可選)。 - dim:
Deprecated alias for axis. 棄用,axis的別名
8、 tf.argmax() 函式, tf.equal()函式, tf.cast()函式, tf.truncated_normal()
1). tf.argmax()函式
tf.argmax可以認為就是np.argmax。tensorflow使用numpy實現的這個API。
簡單的說,tf.argmax就是返回最大的那個數值所在的下標。tf.argmax(array,axis)
當axis=1時返回每列最大值的下標,當axis=0時返回每行最大值的下班。
2). tf.equal()函式
tf.equal(A,B)是對比這兩個矩陣或者向量的相等的元素,如果是相等的那就返回True,反正返回False,返回的值的矩陣維度和A是一樣的
A = [[1,3,4,5,6]]
B = [[1,3,4,3,2]]
with tf.Session() as sess:
print(sess.run(tf.equal(A, B)))
[[ True True True False False]]3). tf.cast()函式
tf.cast(x, dtype)將x的資料格式轉化成dtype.
cast(x,dtype,name=None)
將x的資料格式轉化成dtype.例如,原來x的資料格式是bool,
那麼將其轉化成float以後,就能夠將其轉化成0和1的序列。反之也可以
a = tf.Variable([1,0,0,1,1])
b = tf.cast(a,dtype=tf.bool)
sess = tf.Session()
a = tf.Variable([1,0,0,1,1])
b = tf.cast(a,dtype=tf.bool)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print(sess.run(b))
[ True False False True True]4). tf.truncated_normal()
tf.truncated_normal(shape, mean, stddev):shape表示生成張量的維度,mean是均值,stddev是標準差。這個函式產生正太分佈,均值和標準差自己設定。這是一個截斷的產生正太分佈的函式,就是說產生正太分佈的值如果與均值的差值大於兩倍的標準差,那就重新生成。和一般的正太分佈的產生隨機資料比起來,這個函式產生的隨機數與均值的差距不會超過兩倍的標準差,但是一般的別的函式是可能的。
import tensorflow as tf;
import numpy as np;
import matplotlib.pyplot as plt;
c = tf.truncated_normal(shape=[10,10], mean=0, stddev=1)
with tf.Session() as sess:
print(sess.run(c))
[[ 0.56077307 1.74287605 -0.15655719 0.87136668 -0.4219175 0.94079614
-1.31186545 1.94287431 0.70748854 1.15509737]
[ 0.32469562 -0.91890186 -0.44398952 1.25986481 -1.07295966 0.21889997
0.19389877 -1.22909117 1.34865403 0.87812191]
[-0.83542323 -0.05598836 -1.05256093 -1.16475403 -0.17121609 -0.55075479
-0.37847248 0.14151201 0.36596569 0.55171227]
[ 0.45216689 0.12429248 -0.4333829 -0.00368057 -0.20933141 0.5465408
1.06096387 1.47238612 -1.99268937 1.28203201]
[ 0.36932501 0.30012983 1.94679129 0.59601396 -0.16721351 -0.42786792
0.917597 -1.6504811 -0.81060582 -0.35126168]
[-1.48954999 -0.42889833 0.31517059 1.00009787 0.26073182 1.26285052
-1.80997884 0.51399821 -0.27673215 0.15389352]
[ 0.8669793 -0.28650126 1.39484227 -0.4041909 -1.70028269 0.58513969
0.75772232 -0.47386578 -0.34529254 -0.71658897]
[ 0.74709773 -0.0835886 1.14453304 0.70367438 0.07037418 -0.15808868
0.23158503 -0.67268801 0.55869597 0.12777361]
[-0.52604282 0.64181858 -0.04147881 0.78596973 0.69087744 0.56500375
-1.12409449 -0.42864376 0.30804652 1.33116138]
[-1.36940789 -0.4526186 -0.87445366 0.19748467 -0.06541829 -0.2672275
0.63084471 0.76155263 0.83874393 0.91775542]]9、tf.reduce_max(),tf.reduce_mean()
求最大值tf.reduce_max(input_tensor, reduction_indices=None, keep_dims=False, name=None)
求平均值tf.reduce_mean(input_tensor, reduction_indices=None, keep_dims=False, name=None)
引數1--input_tensor:待求值的tensor。
引數2--reduction_indices:在哪一維上求解。
引數(3)(4)可忽略
import tensorflow as tf
X = [[1., 2.],
[3., 4.]]
re1 = tf.reduce_mean(x) ==> 2.5 #如果不指定第二個引數,那麼就在所有的元素中取平均值
re2 = tf.reduce_mean(x, 0) ==> [2., 3.] #指定第二個引數為0,則第一維的元素取平均值,即每一列求平均值
#re2 = tf.reduce_mean(x, reduction_indices = 0)
re3 = tf.reduce_mean(x, 1) ==> [1.5, 3.5] #
#re3 = tf.reduce_mean(x, reduction_indices = 1)
with tf.Session() as sess:
print(sess.run(re1))
print(sess.run(re2))
print(sess.run(re3))tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)
10、tf.app.flags函式
tf定義了tf.app.flags,用於支援接受命令列傳遞引數,相當於接受argv。
import tensorflow as tf
#第一個是引數名稱,第二個引數是預設值,第三個是引數描述
tf.app.flags.DEFINE_string('str_name', 'def_v_1',"descrip1")
tf.app.flags.DEFINE_integer('int_name', 10,"descript2")
tf.app.flags.DEFINE_boolean('bool_name', False, "descript3")
FLAGS = tf.app.flags.FLAGS
#必須帶引數,否則:'TypeError: main() takes no arguments (1 given)'; main的引數名隨意定義,無要求
def main(_):
print(FLAGS.str_name)
print(FLAGS.int_name)
print(FLAGS.bool_name)
if __name__ == '__main__':
tf.app.run() #執行main函式執行:
[[email protected] test]# python tt.py
def_v_1
10
False
[[email protected] test]# python tt.py --str_name test_str --int_name 99 --bool_name True
test_str
99
True11、python glob模組
glob.glob
返回所有匹配的檔案路徑列表。它只有一個引數pathname,定義了檔案路徑匹配規則,這裡可以是絕對路徑,也可以是相對路徑。下面是使用glob.glob的例子:
import glob
#獲取指定目錄下的所有圖片
print glob.glob(r"E:\Picture\*\*.jpg")
#獲取上級目錄的所有.py檔案
print glob.glob(r'../*.py') #相對路徑 12、Python中split()和os.path.split()兩個分割函式
函式:split()
Python中有split()和os.path.split()兩個函式,具體作用如下:
split():拆分字串。通過指定分隔符對字串進行切片,並返回分割後的字串列表(list)
os.path.split():按照路徑將檔名和路徑分割開
1)、函式說明
1、split()函式
語法:str.split(str="",num=string.count(str))[n]
引數說明:
str:表示為分隔符,預設為空格,但是不能為空('')。若字串中沒有分隔符,則把整個字串作為列表的一個元素
num:表示分割次數。如果存在引數num,則僅分隔成 num+1 個子字串,並且每一個子字串可以賦給新的變數
[n]:表示選取第n個分片
注意:當使用空格作為分隔符時,對於中間為空的項會自動忽略
2、os.path.split()函式
語法:os.path.split('PATH')
引數說明:
1.PATH指一個檔案的全路徑作為引數:
2.如果給出的是一個目錄和檔名,則輸出路徑和檔名
3.如果給出的是一個目錄名,則輸出路徑和為空檔名
2)、分離字串
string = "www.gziscas.com.cn"
1.以'.'為分隔符
print(string.split('.'))
['www', 'gziscas', 'com', 'cn']
2.分割兩次
print(string.split('.',2))
['www', 'gziscas', 'com.cn']
3.分割兩次,並取序列為1的項
print(string.split('.',2)[1])
gziscas
4.分割兩次,並把分割後的三個部分儲存到三個檔案
u1, u2, u3 =string.split('.',2)
print(u1)—— www
print(u2)—— gziscas
print(u3) ——com.cn
3)、分離檔名和路徑
import os
print(os.path.split('/dodo/soft/python/'))
('/dodo/soft/python', '')
print(os.path.split('/dodo/soft/python'))
('/dodo/soft', 'python')
4)、例項
str="hello boy<[www.baidu.com]>byebye"
print(str.split("[")[1].split("]")[0])
www.baidu.com
相關推薦
string中常用函式總結四(append和assign)(C++11)
append(新增字元(串)) (1)basic_string& append(const basic_string& __str); //在字串末尾新增字串str (2) basic_string& append(const basic_st
MFC中常用函式總結
1、MFC編輯框、靜態文字框相關的常用函式 《1》GetDlgItemText(ID ,str) 作用:從對話方塊中獲取文字 第一個引數為要獲取的編輯框(或者靜態文字框、單選按鈕等可以顯示內容的控制元件)的ID,第二個引數為字串(Cstring 型別)的變數,獲取的文字
postgis常用函式總結(一)
1,基本操作函式AddGeometryColumn(<schema_name>, <table_name>, <column_name>, <srid>, <type>, <dimension>)給一個已
mysql中常用函式總結
1、interval函式select now()-INTERVAL '7 d' 獲取當前日期七天前的時間專案使用:order_time > now() - interval '7 d' 用於獲
Tensorflow中常用的函式總結(一)
1、tf.shape()和x.get_shape().as_list()的使用 (1) tf.shape() 先說tf.shape()很顯然這個是獲取張量的大小的,用法無需多說,直接上例子吧! import tensorflow as tf import numpy
jQuery中的常用內容總結(一)
說明 一個 select 兩個 身體健康 作用域 class block class選擇器 jQuery中的常用內容總結(一) 前言 不好意思(????),由於回家看病以及處理一些其它事情耽擱了,不然這篇博客本該上上周或者上周寫的;同時閑談幾句:在這裏建議各位開發的
tensorflow中常用的啟用函式
啟用函式(activation function)執行時啟用神經網路中某一部分神經元,將啟用神經元的資訊輸入到下一層神經網路中。神經網路之所以能處理非線性問題,這歸功於啟用函式的非線性表達能力。啟用函式需要滿足資料的輸入和輸出都是可微的,因為在進行反向傳播的時候,需要對啟用函式求導。 在Te
生產環境中Oracle常用函式總結
1>to_char,將日期轉換為字元;add_months,在第一個引數的日期上加或者減第二個引數的值 select dkzh,jkhtbh,yhkrq,dkffrq,shqs,dqyqcs,to_char(add_months(dkffrq,shqs+dqyqcs+1),'yyyymm'
Python中re(正則表示式)常用函式總結
1 re.match #嘗試從字串的開始匹配一個模式 re.match的函式原型為:re.match(pattern, string, flags) 第一個引數是正則表示式,這裡為"(\w+)\s",如果匹配成功,則返回一個Match,否則返
Java中Math類常用函式總結
Java中比較常用的幾個數學公式的總結: //取整,返回小於目標函式的最大整數,如下將會返回-2 Math.floor(-1.8); //取整,返回發育目標數的最小整數 Math.ceil() //
【Java中Math類常用函式總結】
Java中比較常用的幾個數學公式的總結: //取整,返回小於目標函式的最大整數,如下將會返回-2 Math.floor(-1.8); //取整,返回發育目標數的最小整數 Math.ceil() //四捨五入取整 Math.round() //計算平
PHP中對陣列進行操作的常用函式總結
在PHP中,對陣列的操作是非常常見的,所以,掌握一些常用且重要的陣列操作函式尤其重要。現將一些本人認為較為重要的函式總結如下: 1.建立陣列使用的是array(),如: <?php $a = array("a","b"); //當然還有其他一些基礎的建立陣列的方法
Linux c中一些常用函式總結(c語言中文網。。。)
fgets()函式 標頭檔案:include<stdio.h> fgets()函式 標頭檔案:include<stdio.h>fgets()函式用於從檔案流中讀取一行或指定個數的字元,其原型為: char * fgets(char *
自然語言處理爬過的坑:使用python遍歷所有的資料夾中的所有文字.標準庫OS的常用函式總結大全
# -*- coding: utf-8 -*- import os import codecs def search(filepath): #遍歷filepath下所有檔案,包括子目錄 files = os.listdir(filepath) for fil
Go常用功能總結一階段
sep format 字節數組 ngx str1 [] 構造函數 當前時間 mat 1. go語言從鍵盤獲取輸入內容 <1. 最簡單的辦法是使用 fmt 包提供的 Scan 和 Sscan 開頭的函數。請看以下程序: package main import "
第十八節,TensorFlow中使用批量歸一化
item con 用法 它的 線性 dev 樣本 需要 sca 在深度學習章節裏,已經介紹了批量歸一化的概念,詳情請點擊這裏:第九節,改善深層神經網絡:超參數調試、正則化以優化(下) 由於在深層網絡中,不同層的分布都不一樣,會導致訓練時出現飽和的問題。而批量歸一化就是為了緩
JavaScript常用函式總結
最近正在學習js語法,講到函式這一塊內容,感覺有些細節還是挺有用的,所以發文總結一下。 javascript這門語言本身就是一種弱型別語言,它不和像java, c ,c#等等這些語言一樣,在宣告變數和方法的時候不需要對齊進行指定資料型別的修飾,
【六】 makefile常用函式總結
函式的呼叫語法 函式使用“$”呼叫: $(function arguments) ${function arguments} 例如: $(subst .c, .o, test1.c test2.c) 還是來看一個示例: #$(comma)值是一個逗號
opencv常用函式總結
最近做影象處理專案,總結一下常用的函式: 1,converto :函式轉為任意想要的格式,以及可以新增歸一化係數,這個係數可能要用到mat的最大值和最小值,下面這個函式可以取出最大最小值 2,cv::minMaxLoc(mat,&minim,&maxim);,取出的最大最小值
python中常用的模組一
一,常用的模組 模組就是我們將裝有特定功能的程式碼進行歸類,從程式碼編寫的單位來看我們的程式,從小到大的順序: 一條程式碼<語句塊,<程式碼塊(函式,類)<模組我們所寫的所有py檔案都是模組 引入模組的方式 1,import 模組 2,from xxx impo