
__setup巨集以及表驅動程式設計
在linux的程式碼中,經常可以看到這樣的寫法:
__setup("root=", root_dev_setup);其中__setup為巨集,root_dev_setup為函式名,這樣的寫法是什麼意義呢?
查詢巨集的定義
#define __setup_param(str, unique_id, fn, early) \ static const char __setup_str_##unique_id[] __initconst \ __aligned(1) = str; \ static struct obs_kernel_param __setup_##unique_id \ __used __section(.init.setup) \ __attribute__((aligned((sizeof(long))))) \ = { __setup_str_##unique_id, fn, early } #define __setup(str, fn) \ __setup_param(str, fn, fn, 0)
把巨集展開:
static const char __setup_str_root_dev_setup[] __initconst __aligned(1) = "root=";
static struct obs_kernel_param __setup_root_dev_setup __used __section(.init.setup) __attribute__((aligned((sizeof(long)))))
= { __setup_str_root_dev_setup, root_dev_setup, 0 }定義了2個變數:
1)字串陣列__setup_str_root_dev_setup[]
2)結構體struct obs_kernel_param __setup_root_dev_setup
其中結構體型別定義為:
struct obs_kernel_param {
const char *str;
int (*setup_func)(char *);
int early;
};包含一個字元指標,函式指標和一個標記位。
資料__setup_root_dev_setup放置在__section(.init.setup)段,在vmlinux.lds.h中定義:
#define INIT_SETUP(initsetup_align) \ . = ALIGN(initsetup_align); \ __setup_start = .; \ KEEP(*(.init.setup)) \ __setup_end = .;
程式碼中所有使用__setup("XXXX", XXXXX);經過編譯後放置在.init.setup段中,構成一個struct obs_kernel_param型別的陣列, 同樣:
#define early_param(str, fn) __setup_param(str, fn, fn, 1)
同__setup定義的結構提只是欄位early初始化的值不同,如下圖所示:
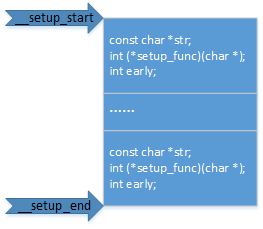
在linux的初始化階段可以通過結構體中的字元指標,查詢呼叫。
1): early options
start_kernel--->setup_arch--->parse_early_parm ---> parse_early_options --->parse_args --->parse_one ---> do_early_param
static int __init do_early_param(char *param, char *val,
const char *unused, void *arg)
{
const struct obs_kernel_param *p;
/*查詢字元指標同入參parm相同,且early為1(即early_param巨集定義的資料)
或者引數parm為”console”或者巨集定義的str為”earlycon”*/
for (p = __setup_start; p < __setup_end; p++) {
if ((p->early && parameq(param, p->str)) ||
(strcmp(param, "console") == 0 &&
strcmp(p->str, "earlycon") == 0)
) {
if (p->setup_func(val) != 0)
pr_warn("Malformed early option '%s'\n", param);
}
}
/* We accept everything at this stage. */
return 0;
}2)booting kernel
start_kernel--->parse_args--->parse_one ---> unknown_bootoption ---> obsolete_checksetup
static bool __init obsolete_checksetup(char *line)
{
const struct obs_kernel_param *p;
bool had_early_param = false;
p = __setup_start;
/*執行引數匹配成功,且標記early為0的函式*/
do {
int n = strlen(p->str);
if (parameqn(line, p->str, n)) {
if (p->early) {
if (line[n] == '\0' || line[n] == '=')
had_early_param = true;
} else if (!p->setup_func) {
pr_warn("Parameter %s is obsolete, ignored\n",
p->str);
return true;
} else if (p->setup_func(line + n))
return true;
}
p++;
} while (p < __setup_end);
return had_early_param;
}
類似還有pure_initcall, __initcall都是一套相同的實現機制,在編碼中可以根據業務劃分,將程式碼放入對應的業務模組,在編譯階段將這些程式碼構造為一個表,可以集中呼叫或按需查詢呼叫。這很好的體現了linux機制與策略分離的思想,在這裡採用了一種程式設計策略:表驅動法,按照《CODE COMPLETE》的說法:
表驅動法是一種程式設計策略(scheme)-- 從表裡面查詢資訊而不使用邏輯語句。事實上,凡是能通過邏輯語句來選擇的事物,都可以通過查表來選擇。簡單情況使用邏輯語句更為容易直白。但隨著邏輯鏈越來越複雜,查表就顯得更具有吸引力。
查表的方式主要有:
- 直接訪問
- 索引訪問
- 階梯訪問
直接訪問
即直接通過下標,找到要訪問的內容,比較常用的場景如,報文處理回撥函式。
如定義的報文格式為:
![]()
報文了型別可以用列舉表示:
Enum type{
Type_1,
Type_2.
…
Type_ALL
}定義報文的處理函式:
Int process_type1(int len, char*data)
{
….
}定義表:
Typedef struct tagP_F{
Int int (*setup_func)(int, char *);
}P_F;以報文型別下標為索引
P_F table = {f1, f2};可以直接通過table[Type_1](len, data); 呼叫對應的報文處理函式。
索引訪問
要建立索引表,比直接建立主表要節約記憶體。
如上面描述的setup巨集。
階梯訪問
也稱為分段訪問,是通過對某表中資料分段,根據分段再進行查詢的過程。比較常見的是績點查詢
無論什麼程式設計模式,都只是提供一個思路,而不是特定的模式,要根據實際情況靈活運用,適當調整。對應表驅動法要注意兩點:1)如何去訪問 以及 2)把什麼放在表中。