
Learning How To Code Neural Networks
Learning How To Code Neural Networks
This is the second post in a series of me trying to learn something new over a short period of time. The first time consisted of learning how to do machine learning in a week.
This time I’ve tried to learn neural networks. While I didn’t manage to do it within a week, due to various reasons, I did get a basic understanding of it throughout the summer and autumn of 2015.
By basic understanding, I mean that I finally know how to code simple neural networks from scratch on my own.
In this post, I’ll give a few explanations and guide you to the resources I’ve used, in case you’re interested in doing this yourself.
Step 1: Neurons and forward propagation
So what is a neural network? Let’s wait with the network part and start off with one single neuron.
A neuron is like a function; it takes a few inputs and calculates an output.
The circle below illustrates an artificial neuron. Its input is 5 and its output is 1. The input is the sum of the three synapses connecting to the neuron (the three arrows at the left).
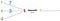

At the far left we see two input values plus a bias value. The input values are 1 and 0 (the green numbers), while the bias holds a value of -2 (the brown number).
The inputs here might be numerical representations of two different features. If we’re building a spam filter, it could be wether or not the email contains more than one CAPITALIZED WORD and wether or not it contains the word ‘viagra’.
The two inputs are then multiplied by their so called weights, which are 7 and 3 (the blue numbers).
Finally we add it up with the bias and end up with a number, in this case: 5 (the red number). This is the input for our artificial neuron.

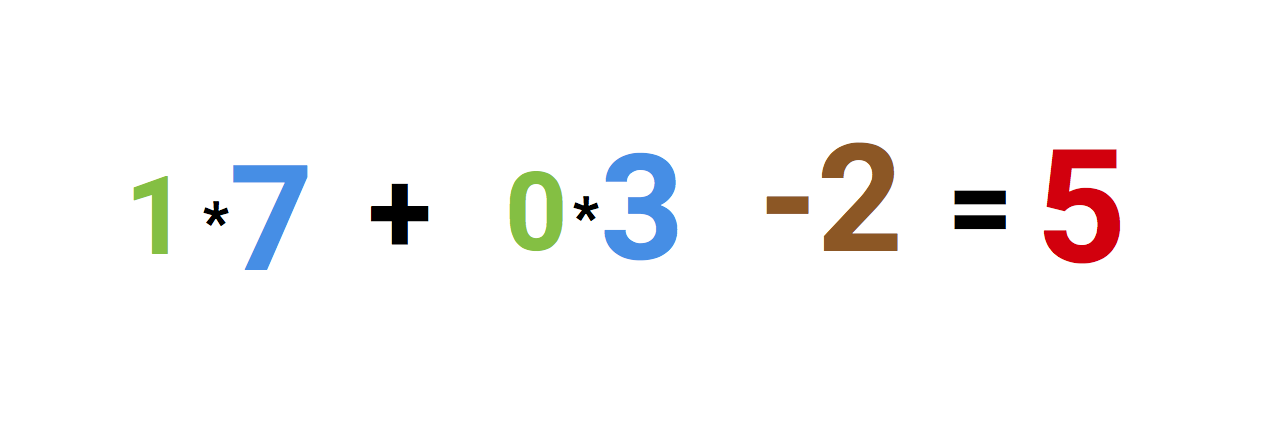
The neuron then performs some kind of computation on this number — in our case the Sigmoid function, and then spits out an output. This happens to be 1, as Sigmoid of 5 equals to 1, if we round the number up (more info on the Sigmoid function follows later).
If this was a spam filter, the fact that we’re outputting 1 (as opposed to 0) probably means that the neuron has labeled the text as ‘spam’.

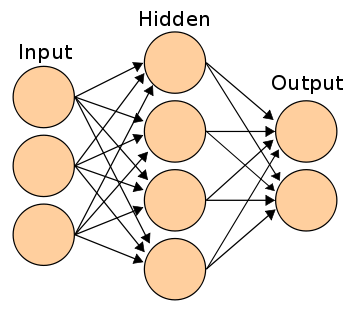
If you connect a network of these neurons together, you have a neural network, which propagates forward — from input output, via neurons which are connected to each other through synapses, like on the image to the left.
I can strongly recommend the Welch Labs videos on YouTube for getting a better intuitive explanation of this process.
Step 2: Understanding the Sigmoid function
After you’ve seen the Welch Labs videos, its a good idea to spend some time watching Week 4 of the Coursera’s Machine Learning course, which covers neural networks, as it’ll give you more intuition of how they work.
The course is fairly mathematical, and its based around Octave, while I prefer Python. Because of this, I did not do the programming exercises. Instead, I used the videos to help me understand what I needed to learn.
The first thing I realized I needed to investigate further was the Sigmoid function, as this seemed to be a critical part of many neural networks. I knew a little bit about the function, as it was also covered in Week 3 of the same course. So I went back and watched these videos again.
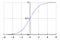
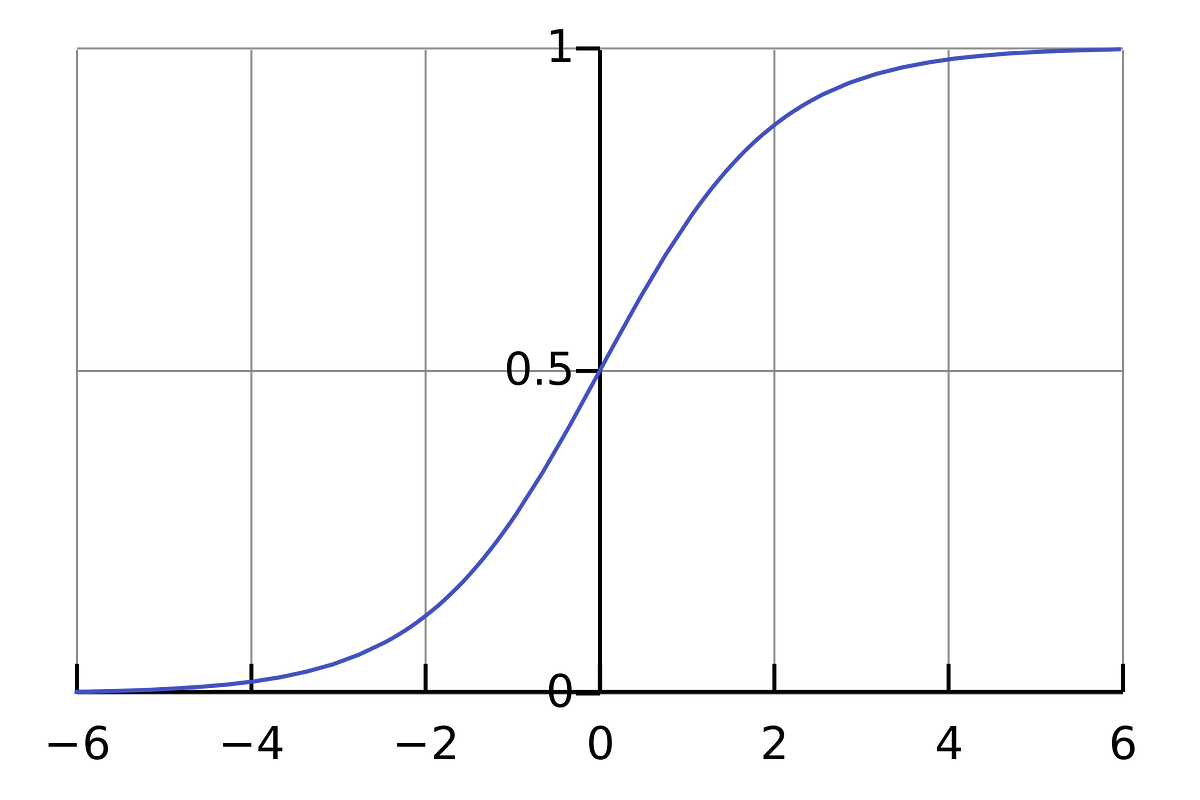
But watching videos won’t get you all the way. To really understand it, I felt I needed to code it from the ground up.
So I started to code a logistic regression algorithm from scratch (which happened to use the Sigmoid function).
It took a whole day, and it’s probably not a very good implementation of logistic regression. But that doesn’t matter, as I finally understood how it works. Check the code here.
You don’t need to perform this entire exercise yourself, as it requires some knowledge about and cost functions and gradient descent, which you might not have at this point.
But make sure you understand how the Sigmoid function works.
Step 3: Understanding backpropagation
Understanding how a neural network works from input to output isn’t that difficult to understand, at least conceptually.
More difficult though, is understanding how the neural network actually learns from looking at a set of data samples.
The concept is called backpropagation.
This essentially means that you look at how wrong the network guessed, and then adjust the networks weights accordingly.
The weights were the blue numbers on our neuron in the beginning of the article.
This process happens backwards, because you start at the end of the network (observe how wrong the networks ‘guess’ is), and then move backwards through the network, while adjusting the weights on the way, until you finally reach the inputs.
To calculate this by hand requires some calculus, as it involves getting some derivatives of the networks’ weights. The Kahn Academy calculus courses seems like a good way to start, though I haven’t used them myself, as I took calculus on university.
Note: there are a lot of libraries that calculates the derivatives for you, so if you’d like to start coding neural networks before completely understanding the math, you’re fully able to do this as well.
The three best sources I found for understanding backpropagation are these:
You should definitely code along while you’re reading the articles, especially the two first ones. It’ll give you some sample code to look back at when you’re confused in the future.
Plus, I can’t really emphasize this enough:
You don’t learn much by reading about neural nets, you need to practice it to make the knowledge stick.
The third article is also fantastic, but I’ve used this more as a wiki than a plain tutorial, as it’s actually an entire book. It contains thorough explanations all the important concepts in neural networks.
These articles will also help you understand important concepts as cost functions and gradient descent, which play equally important roles in neural networks.
Step 4: Coding your own neural networks
In some articles and tutorials you’ll actually end up coding small neural networks. As soon as you’re comfortable with that, I recommend you to go all in on this strategy. It’s both fun and an extremely effective way of learning.
One of the articles I also learned a lot from was A Neural Network in 11 Lines Of Python by IAmTrask. It contains an extraordinary amount of compressed knowledge and concepts in just 11 lines.
After you’ve coded along with this example, you should do as the article states at the bottom, which is to implement it once again without looking at the tutorial. This forces you to really understand the concepts, and will likely reveal holes in your knowledge, which isn’t fun. However, when you finally manage it, you’ll feel like you’ve just acquired a new superpower.
A little side note: When doing exercises I was often confused by the vectorized implementations some tutorials use, as it requires a little bit of linear algebra to understand. Once again, I turned myself back to the Coursera ML course, as Week 1 contains a full section of linear algebra review. This helps you to understand how matrixes and vectors are multiplied in the networks.
When you’ve done this, you can continue with this Wild ML tutorial, by Denny Britz, which guides you through a little more robust neural network.
At this point, you could either try and code your own neural network from scratch or start playing around with some of the networks you have coded up already. It’s great fun to find a dataset that interests you and try to make some predictions with your neural nets.
To get a hold of a dataset, just visit my side project Datasets.co (← shameless self promotion) and find one you like.
Anyway, the point is that you’re now better off experimenting with stuff that interests you rather than following my advices.
Personally, I’m currently learning how to use Python libraries that makes it easier to code up neural networks, like Theano, Lasagne and nolearn. I’m using this to do challenges on Kaggle, which is both great fun and great learning.
Good luck!
And don’t forget to press the heart button if you liked the article :)
相關推薦
Learning How To Code Neural Networks
Learning How To Code Neural NetworksThis is the second post in a series of me trying to learn something new over a short period of time. The first time con
Lewagon — Learning how to code in Rio de Janeiro
Lewagon — Learning how to code in Rio de JaneiroI started to code — first with an app on my iphone — after work. I did not think about becoming a coder, I
Learn How to Code and Deploy Machine Learning Models on Spark Structured Streaming
This post is a token of appreciation for the amazing open source community of Data Science, to which I owe a lot of what I have learned. For last few month
元學習-Learning How to Learn-Q&A:Terry訪談錄
完全 知識 反思 div 提問 blog 專業 激情 堅持 Q&A:Terry訪談錄 Q1:怎樣面對完全陌生的學習領域? A1:敢於實踐,而不是大量閱讀;取得專家的指點 Q2:怎樣長時間保持註意力集中? A2:以向講述人或者自己提問的方式積極參與 Q3:如何
元學習-Learning How to Learn-第三課:學習新知識的一般過程
自主 註意 找到 專註 閱讀 集中 ear 針對性 練習 第三課:學習新知識的一般過程 一、建立組塊:整理新的知識 1.前提——排除幹擾,集中註意力:創意的基礎是專註; 2.找到建立組塊的位置——通讀材料,抓住標題類信息,掌握知識分布的情況:自頂向下,而不是從前往後;
How to train Neural Network faster with optimizers?
from:https://towardsdatascience.com/how-to-train-neural-network-faster-with-optimizers-d297730b3713 AsI worked on the last article, I had the o
關於coursera上Learning How to Learn課程的讀書筆記3
課程進行到第二週了,雖然該課程也只有四周,不過收益匪淺,對吧。 第二週 第一節: introduction: 介紹組塊的概念(小而緊湊的資訊塊)和組塊對應試的技巧;討論一些事半功倍和事倍功半的學習方法,提到如overlearning和interleaving等概
How to code The Transformer in Pytorch
Could The Transformer be another nail in the coffin for RNNs? Doing away with the clunky for loops, it finds a way to allow whole sentences to simultaneous
Machine Learning: How to Build a Model From Scratch
As an online travel booking company, Momentum Travel realized early on that identifying and preventing fraud is a vital part of their business. Hear from S
Machine learning: How to go from theory to reality
Too bad so few people know how to use them. As recent 451 Research survey data indicates, a lack of skilled people continues to stymie the AI revolution. I
Meet The Dog That’s Learning How to Help Save An Endangered Owl
An owl pellet, also known by falconers as a casting, is similar to a hairball coughed up by a cat, except an owl pellet contains the undigestible remains o
How to code like a Hacker in the terminal
How to code like a Hacker in the terminalYou are a hacker. Your home is the terminal. You know every key stroke is valuable. If something is less than 100%
譯:《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》
今天看了CS231n關於dropout部分的講述,不是很清晰,拿來一篇關於Dropout的代表性文章來讀一讀,體會一下。 摘要 在具有大量引數的深度神經網路中,Overfitting是一個嚴重的問題。Dropout是解決這個問題的一種技巧。主要思想是
Learning how to learn
[轉發] Barbara Oakley 是系統工程學博士,但對於「學習」方面也頗有研究,在 Coursera 上也有相應的課程。還出了幾本書,比如 A Mind For Numbers: How to Exce
【論文精讀】Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Dropout: A Simple Way to Prevent Neural Networks from Overfitting 來填坑了,上次讀了《Deep Learning under Privileged Information Using Heter
Learning How to Learn(1)
學習一項技能,尤其是比較困難代學科,就像舉重一樣,不可能在比賽的前一天才開始訓練。功夫在平時,每天鍛鍊,才能不斷提高。在放鬆的時候大腦容易出現有創意的想法。 在睡覺時,大腦神經元根據學習內容會生長出新
論文筆記-Sequence to Sequence Learning with Neural Networks
map tran between work down all 9.png ever onf 大體思想和RNN encoder-decoder是一樣的,只是用來LSTM來實現。 paper提到三個important point: 1)encoder和decoder的LSTM
【DeepLearning學習筆記】Coursera課程《Neural Networks and Deep Learning》——Week1 Introduction to deep learning課堂筆記
決定 如同 樣本 理解 你是 水平 包含 rod spa Coursera課程《Neural Networks and Deep Learning》 deeplearning.ai Week1 Introduction to deep learning What is a
課程一(Neural Networks and Deep Learning),第一週(Introduction to Deep Learning)—— 0、學習目標
1. Understand the major trends driving the rise of deep learning. 2. Be able to explain how deep learning is applied to supervised learning. 3. Unde
課程一(Neural Networks and Deep Learning),第一週(Introduction to Deep Learning)—— 2、10個測驗題
1、What does the analogy “AI is the new electricity” refer to? (B) A. Through the “smart grid”, AI is delivering a new wave of electricity.