
【論文精讀】Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
來填坑了,上次讀了《Deep Learning under Privileged Information Using Heteroscedastic Dropout》這篇論文(筆記看這裡),感覺有很多東西還沒弄懂,原論文也多次提到了這篇文章,今天來拜讀一下(貌似Gaussian Dropout就是在這裡被首先提出來的)。這篇文章很長,實驗部分就不多講了,重點看看作者對於Dropout的理解和認識。
Abstract
深層神經網路是非常強大的機器學習系統。然而,在這樣的網路中,過擬合是一個嚴重的問題。大型網路的使用速度也較慢,這使得在測試時結合許多不同的大型神經網路的預測來處理過擬合問題變得非常棘手。Dropout是解決這個問題的一種技巧。關鍵的想法是在訓練過程中,從神經網路中隨機丟棄神經元(以及它們的連線)。這就防止了神經元之間過度的協同適應。在訓練過程中,dropout技巧會從指數級的的不同的“稀疏”網路中抽取樣本。在測試時,就可以很容易地估計出所有這些稀疏網路的預測結果的平均。這顯著地減少了過擬合,並且比其他正則化方法有了很大的改進。我們證明,drop改進了神經網路在視覺、語音識別、文件分類和計算生物學等監督學習任務上的效能,獲得了許多基準資料集state-of-the-art結果。
關鍵詞:neural networks, regularization, model combination, deep learning
Introduction
深度神經網路深層的結構讓他們有很強的學習能力。然而,在訓練資料有限的情況下,這些複雜的關係有許多是取樣噪聲的結果,因此它們將存在於訓練集中,而不存在於真實的測試資料中,即使它們來自相同的分佈(就是說在訓練集資料少的情況下,深層的網路會把噪聲造成的輸入輸出之間複雜的關係也完美擬合,使其不再具有好的泛化能力)。解決方法主要有:提前終止、L1和L2正則化、軟權重共享(soft weight sharing)。
不考慮計算的成本,對於固定尺寸的模型來說,最好的正則化策略就根據訓練資料的後驗概率大小加權平均所有的可能的引數。但對於較複雜的網路,這種方法計算量太大了。所以作者採用另一種對指數數量級的共享引數的網路的進行平均策略。
組合不同的大型網路是最好的方法,但是卻不可行,一方面沒有那麼多資料去訓練,訓練那麼多網路很耗時,找到合適的超參也很難,同時在測試時響應速度會很慢。
圖1介紹了Dropout的用法,通常dropout率可以通過驗證集確定,或者設為0.5(這樣產生的可能情況是最多的),但是輸入層的dropout率要接近1。
使用了Dropout技巧,如果一個網路有個神經元,那麼就有種子網路結構可能出現,但是由於權值都是共享的,所以引數還是數量級的。
測試時,直接用子網路輸出結果的平均不是可行的 ,但使用子網路權值的加權平均構成新的網路卻可以表現很好。為了讓這個組合的網路輸出的期望和真實的期望相同,那麼在子網路組合時,應該將權值都乘以dropout率。這種方法也能用在受限波爾茨曼機(RBM)中。
Motivation
Dropout的動機來自於關於性別在進化中的作用的理論。有性生殖包括從一個親本和另一個親本中提取一半的基因,加入非常少量的隨機突變,並將它們結合產生受精卵。無性繁殖是通過父母基因的拷貝中加入微小突變來創造後代。無性繁殖應該是一種更好的方法來優化個體的健康,這似乎是合理的,因為一組良好的基因組合在一起可以直接傳遞給後代。另一方面,有性生殖很可能會破壞這些共同適應的基因,特別是如果這些基因的數量很大,而且直覺上,這應該會降低已經進化出複雜的共同適應的生物體的適應性。然而,有性繁殖是最先進的生物進化的方式。
對有性生殖優勢的一種可能解釋是,從長期來看,自然選擇的標準可能不是個體特性,而是基因的混合能力。就是說那些能夠和更多隨機的基因協作的基因才是更加健壯的。因此一些基因必須要自己學會做一些事而不只是跟很多其他基因合作,這種合作會減少個體適應性。類似地,隨機的選擇dropout可以增加隱層神經元的健壯性。
有個密切相關但卻略有不同的例子,十個陰謀,每個五人蔘與和一個大陰謀五十人蔘與相比,顯然前者獲得一次成功概率較大。一個複雜的共同協作的網路在訓練集表現會很出色,但到測試集中,出現了很多新的資料,他就不如很多個更為簡單的協作神經元工作的效果好。
Related Work
Dropout可以被解釋為一種通過在隱藏的單元中新增噪聲來調節神經網路的方法。Vincent et al.(2008, 2010)曾在去噪自動編碼器(DAEs)的背景下,將噪聲新增到自動編碼器的輸入單元中,並訓練網路重構無噪聲輸入。作者的工作擴充套件了這一思想,展示了dropout可以有效地應用到隱藏層中,並且它可以被解釋為一種模型平均的形式。作者還表明,增加噪聲不僅對無監督特徵學習有用,而且可以擴充套件到有監督學習問題。事實上,我們的方法可以應用於其他基於神經的架構,例如,Boltzmann機器。雖然5%的噪聲通常對DAEs最有效,但我們發現我們在測試時應用的加權縮放程式使我們能夠使用更高的噪聲級別。放棄20%的輸入單元和50%的隱藏單元通常是最優的。
由於dropout可以看作是一種隨機正則化技術,因此很自然地要考慮它的確定性對應物,而確定性對應物是通過邊緣化噪聲得到的(就是把和dropout效果相同的正則項提取出來)。在本文中,我們證明了,在簡單的情況下,可以用邊緣化的方法提取出來,從而獲得確定性的正則化方法。最近,van der Maaten et al.(2013)也探究了與不同指數族噪音分佈相對應的確定性調節因子,包括輟學者(他們稱之為\blankout noise)。然而,他們將噪聲應用到輸入中,只探索沒有隱藏層的模型。Wang和Manning(2013)提出了一種通過邊緣化dropout噪聲來加速dropout的方法。Chen等人(2012)在去噪自動編碼器的背景下探討了邊緣化問題。
在dropout中,我們隨機地最小化噪聲分佈下的損失函式。這可以看作是最小化期望損失函式。Globerson and Roweis (2006);Dekel et al.(2010)研究了另一種情況,即當對手選擇放棄哪個unit時,損失最小化。在這裡,可以刪除的單元的最大數量不是噪聲分佈,而是被取消的。然而,這項工作也沒有探究隱藏單元的模型。
Model Description
Dropout技巧很簡單,可由以下公式描述:
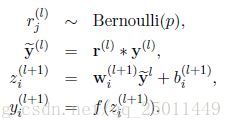
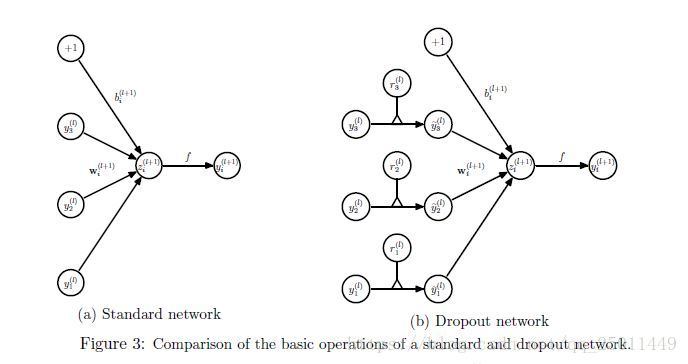
其中表示一個由多個獨立的服從相同伯努利分佈的變數構成的向量,表示點乘,即對應元素相乘,第層的輸出經過dropout變為。層的輸入和輸出演算法不變。在應用BP進行訓練時,只對子網路的引數求導即可,測試時子網路的引數需要被縮放:。如圖二所示。
Learning Dropout Nets
這一節介紹dropout的網路是如何訓練的。
Backpropagation
帶dropout的神經網路和普通神經網路訓練起來差不多,唯一的區別就是在一個mini-batch中引數的更新只發生在子網路中,那些被dropout遮蔽的網路神經元引數都不會被更新。那些用來改善SGD效果的演算法,比如:momentum、退火法、L2正則化在有dropout的情況下也都適用。
另一種對於dropout很有用的策略是將每層隱層權重的模的大小限制為(感覺類似於L2正則化)。這樣可以限制引數在learning rate很大的情況下不至於blowing up。
Unsupervised Pretraining
Dropout如果用在預訓練的網路上,需要先把權值乘以,learning rate儘量選小一點,不然會抹去預訓練時學到的資訊。
Experimental Results
作者在不同型別的很多資料集上做了實驗,具體資料集情況見下表1,得到的實驗結果均證明dropout的有效性。
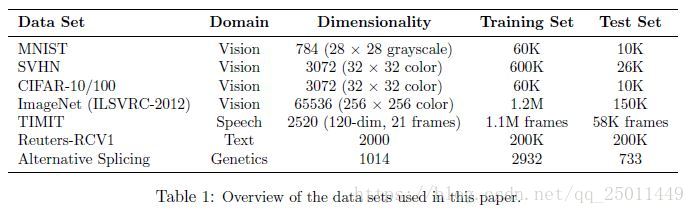
具體的實驗結果有興趣的話可以到原論文裡檢視。
Salient Features
這一節為了探究dropout為啥有效,探究了以下幾個方面:dropout對特徵產生的影響;對隱層神經元啟用值稀疏性的影響;dropout率、神經網路規模和訓練集規模大小對dropout效果的影響。
Effect on Features

圖7是擁有256個修正線性單元的一層隱層的自編碼器在MNIST上的訓練結果,很明顯地看出,左邊沒有dropout的情況下,每個單元並沒有很明確地要去檢測某個影象特徵,這是由於單元之間的相互適應性太強,需要組合在一起才能比較好地工作,但是就右圖有dropout的情況而言很明顯可以看出,每個單元都在檢測一種邊緣、筆畫或者點,也就是說每個單元之間沒有那麼強的相互適應性。泛化能力會強很多。
Effect on Sparsity
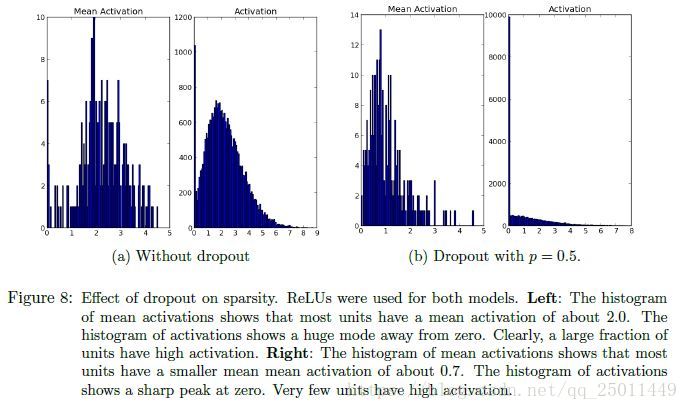
圖8展示了dropout對隱層啟用值稀疏性的影響,可以看出加入了dropout以後啟用值的分佈向0靠近,稀疏性明顯增加。
Effect of Dropout Rate
這一小節探究dropout率(神經元保留率)對效果的影響。作者從下面兩種情況進行比較:
- 隱層神經元個數固定( fixed)。
- 在經過了dropout後被保留的神經元期望是恆定的( fixed).
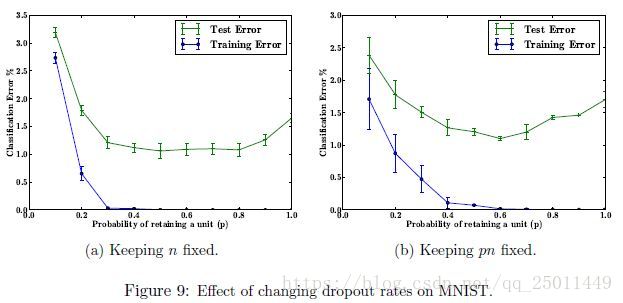
結果如圖9所示,值得注意的是,如果保持不變,那麼在很小時,誤差要比保持不變時小很多。兩種情況下,都是在0.5左右得到最小的測試誤差。(我感覺這個實驗這樣縱向對比不是很合理)
Effect of Data Set Size
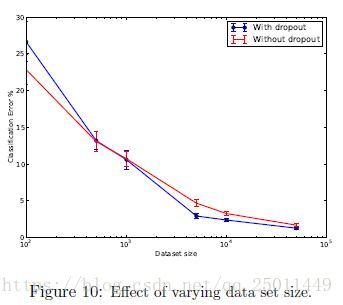
這個結果很有意思,在訓練資料極小的情況下,即使加了dropout也不會使訓練效果變好,因為資料集太小時,就算加了dropout網路還是有足夠多的引數使結果過擬合,這個很好理解。
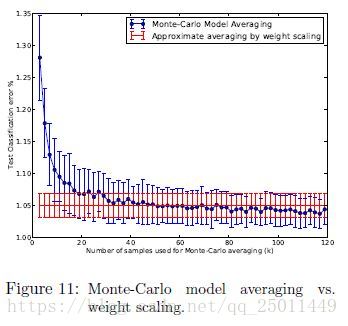
Monte-Carlo Model Averaging vs. Weight Scaling
在測試時需要把子網路組合起來,使用文中提到的Monte-Carlo Model Averaging模型,當取樣的很大時,效果很好,但是很耗時,直接使用前面提到的Weight Scaling,即把子網路權值按照dropout率縮放後組合的方式更有效率。
Dropout Restricted Boltzmann Machines
這裡把dropout技巧用在了受限波爾茨曼機,挖個坑等學了RBM再來感受一下。
Marginalizing Dropout
這一小節作者將dropout隨機的部分邊緣化,使dropout的效果邊緣化到損失函式,使其成為一種“確定性”的模型。
Linear Regression
把dropout應用到最簡單的線性迴歸,即僅在輸入的基礎上點乘的Bernoulli矩陣,那麼優化問題就會由:
變為:
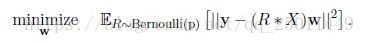
化簡後:
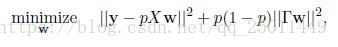
其中:
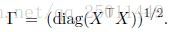
或者還可以寫成:
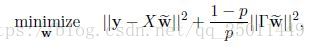
其中:
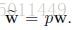
這個式子的格式有沒有很是熟悉。
Logistic Regression and Deep Networks
這裡作者也沒給出具體的說明。
Multiplicative Gaussian Noise
這裡作者討論了將Bernoulli隨機數改為Gaussian隨機數的效果,在Bernoulli情況下如果單元保留的概率為,那麼方差為,在Gaussian的情況下將方差也設為,得到的實驗結果如下表10,對於這樣的結果,作者解釋為,Gaussian的情況下熵要高一些。

Conclusion
總結的展望中作者主要談了dropout加速問題,由於隨機捨棄掉一些單元會使得引數的更新很“noisy”,解決辦法可以是找到一個有相同效果的正則項來代替dropout。
相關推薦
【論文精讀】Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Dropout: A Simple Way to Prevent Neural Networks from Overfitting 來填坑了,上次讀了《Deep Learning under Privileged Information Using Heter
譯:《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》
今天看了CS231n關於dropout部分的講述,不是很清晰,拿來一篇關於Dropout的代表性文章來讀一讀,體會一下。 摘要 在具有大量引數的深度神經網路中,Overfitting是一個嚴重的問題。Dropout是解決這個問題的一種技巧。主要思想是
【論文精讀】Curriculum Learning
Curriculum Learning 課程學習(Curriculum Learning)由Montreal大學的Bengio教授團隊在2009年的ICML會議上提出,主要思想是模仿人類學習的特點,由簡單到困難來學習課程(在機器學習裡就是容易學習的樣本和不容易
【論文精讀】Select Via Proxy: Efficient Data Selection For Training DeepNetworks
Select Via Proxy: Efficient Data Selection For Training DeepNetworks 2019ICLR的文章,介紹了Select Via Proxy(SVP)通過較小規模的模型來確定樣本的uncertainty
【論文閱讀】Learning a Deep Convolutional Network for Image Super-Resolution
開發十年,就只剩下這套架構體系了! >>>
a simple way to watch TV.
About a year ago, I cut the cords and canceled my cable subscription. I watch a lot of TV shows, but I stream everything anyway, and avoiding all the c
Show HN: Views Tools, a simple way to design React interfaces (YC SUS '18)
Hi everyone!We're launching Views Tools today as part of YC Startup School 2018!Our long term goal is to simplify development and we're starting with how p
【論文閱讀】Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
【論文閱讀】Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition 這是2017ICCV workshop的一篇文章,這篇文章只是提出了一個3D-ResNets網路,與之前介紹的
【深度學習】卷積層提速Factorized Convolutional Neural Networks
Wang, Min, Baoyuan Liu, and Hassan Foroosh. “Factorized Convolutional Neural Networks.” arXiv preprint arXiv:1608.04337 (2016).
【論文解讀】【半監督學習】【Google教你水論文】A Simple Semi-Supervised Learning Framework for Object Detection
題記:最近在做LLL(Life Long Learning),接觸到了SSL(Semi-Supervised Learning)正好讀到了谷歌今年的論文,也是比較有點開創性的,淺顯易懂,對比實驗豐富,非常適合缺乏基礎科學常識和剛剛讀研不會寫論文的同學讀一讀,觸類旁通嘛。 這篇論文思路等等也非常適合剛剛開始
【論文翻譯】中英對照翻譯--(Attentive Generative Adversarial Network for Raindrop Removal from A Single Image)
【開始時間】2018.10.08 【完成時間】2018.10.09 【論文翻譯】Attentive GAN論文中英對照翻譯--(Attentive Generative Adversarial Network for Raindrop Removal from A Single Imag
Teaching Is a Fruitful Way to Learn【教學是一種有效的學習方式】
Teaching Is a Fruitful Way to Learn For thousands of years, people have known that the best way to understand a concept is to explain it to
【hdu】5974 A Simple Math Problem
題目大意: 給出 A 和 B 。 A = x + y;B = lcm( x, y)。 求 x 和 y 。 題解: 直觀思路,只要求出 x*y 我們就可以直接解方程了。 易知 x*y = lcm * gcd。 但是 x 和 y 我們都不知道,怎麼求 gcd
【論文筆記】用形狀做擋風玻璃上的雨滴檢測《Detection Of Raindrop With Various Shapes On A Windshield》
《Detection of Raindrop with Various Shapes on a Windshield》 1 介紹 2 雨滴檢測方法 在白天和夜晚使用不同的演算法。通過整幅影象的強度水平判斷是白天還是夜晚。 2.1 白天的雨滴檢測方法 這個方法假設
【論文閱讀】A Correlated Topic Model Using Word Embeddings
《A Correlated Topic Model Using Word Embeddings》 Abstract 傳統的主題模型能夠通過用邏輯正態分佈代替先驗的Dirichlet來捕捉潛在主題之間的相關結構。word embeddings 已經被證明能夠捕捉語義規律,因此語義相
【論文閱讀】A Neural Probabilistic Language Model
《A Neural Probabilistic Language Model》 Yoshua Bengio 2003 Abstract 統計語言模型建模(Statistical Language Modeling)目標是學習一種語言中單詞序列的聯合概率函式。維度限制會導致:模
【論文筆記】Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification
摘要 Person re-identification (ReID) is an important task in computer vision. Recently, deep learning with a metric learning loss has becom
【論文筆記】視訊分類系列 Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video (OFF)
0. 簡述 運動資訊對於視訊中動作的識別有著重要的作用。其中最常用的一種運動資訊,是光流。之前的方法計算光流是offline的,比較耗時,本文提出了一種新的簡潔的運動表示,叫做Optical Flow guided Feature (OFF)。OFF通
【論文閱讀】A Closer Look at Spatiotemporal Convolutions for Action Recognition
【論文閱讀】A Closer Look at Spatiotemporal Convolutions for Action Recognition 這是一篇facebook的論文,它和一篇google的論文連結地址的研究內容非常相似,而且幾乎是同一時刻的研究,感覺這兩個公司真的冤家路窄,
【論文閱讀】Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
【論文閱讀】Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset 這是一篇2017CVPR的論文,我感覺這篇論文最大的貢獻就是提出了kinetics資料集,這個資料集與之前的行為識別資料集相比有質的飛躍。同