
kafka java程式碼編寫
上篇,我介紹瞭如何搭建kafka,但在如何使用kafka上,還沒做過去但介紹,大多人都是寫改main方法去傳送和接受,但我們實際業務肯定不是這樣但。我們公司是以一種方式,類似一直啟動main然後接受訊息的。這裡我也還沒去具體瞭解,之後我會再看看,瞭解之後可能會再寫一篇文章出來。
kafka啟動之後,需要建立topic和partitions,java程式碼只能幫你傳遞訊息和接受訊息,這建立topic和partitions的工作還是得有你自己親自完成
topic相當於一個主題,broker相當於伺服器。比如建立一個日誌的topic,傳送日誌訊息 ,建立一個訂單的topic,傳送訂單資訊。
當然topic裡還有分割槽(partition)的概念,由於一個topic可能太大,利用分割槽更好的接受和傳送訊息,也可以用不同的consumer去消費一個topic下不同partition裡的資料,分割槽規則可以自定義。

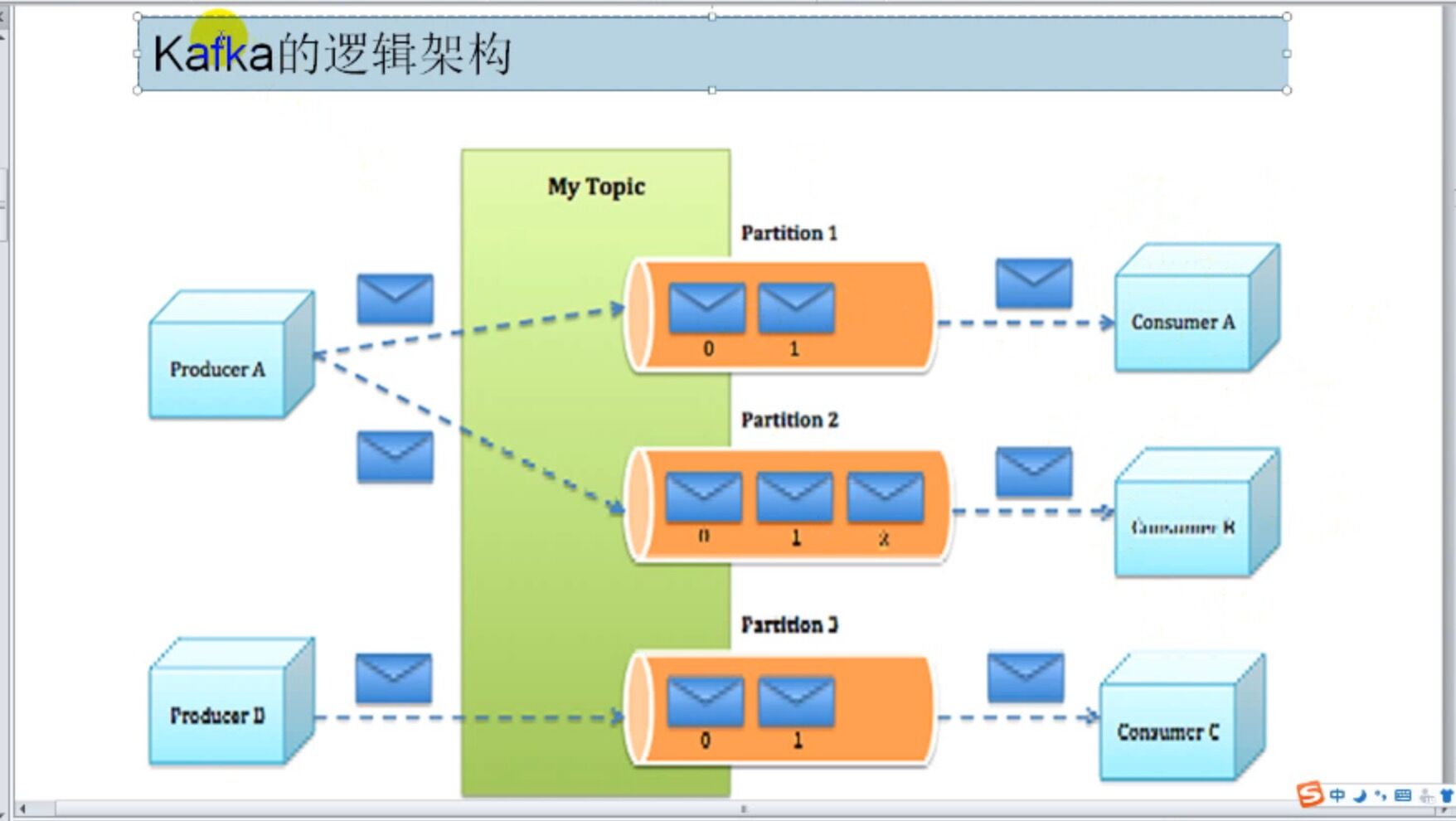
每個partition對應一個索引檔案,每個索引檔案對應一個日誌檔案,日誌裡有seq,稀疏索引的主鍵。。(萬一kafka掛了,可以讀這個檔案,用二分法找到自己之前所讀取的那條kafka資料)
像之前一樣,進到kafka目錄,cd /home/kafka
執行以下命令
bin/kafka-topics.sh --create --zookeeper h1:2181,h2:2181,h3:2181 --partition 3 --replication-factor 3 --topic 'test3'
然後你跑到 cd /home/kafka/kafka-logs就會看到有3個檔案生成了
replication-factor 是在幾個broke上生產副本,partition是代表一個topic的分割槽檔案
我這裡建立了一個wmtest2的topic,副本數是1 --replication-factor1,就等於沒有副本,就一個檔案,partition是3,整句話執行完之後是zk會再每個broker上建立一個wmtest2的topic,但每個機器存的分割槽不一樣(如我現在三臺虛擬機器h1,h2,h3 建立之後,wmtest2-0 0號partition放在h1裡,wmtest2-1 1號partition放在h2裡,wmtest2-2 2號partition放在h3裡)

我這裡又多建了幾個topic,為了讓讀者能更深刻的理解

3個分割槽,2個備份

1個分割槽,2個備份

2個分割槽,2個備份
以下是h1伺服器的topic情況,我這裡是建立了3個log檔案,所以topic會分配到上檔案裡的

以下是h2伺服器的topic情況

以下是h3伺服器topic情況

也可以根據命令去查詢
cd到kafka目錄,然後輸入以下命令
bin/kafka-topics.sh --describe --zookeeper h1:2181 --topic 'wmtest2'
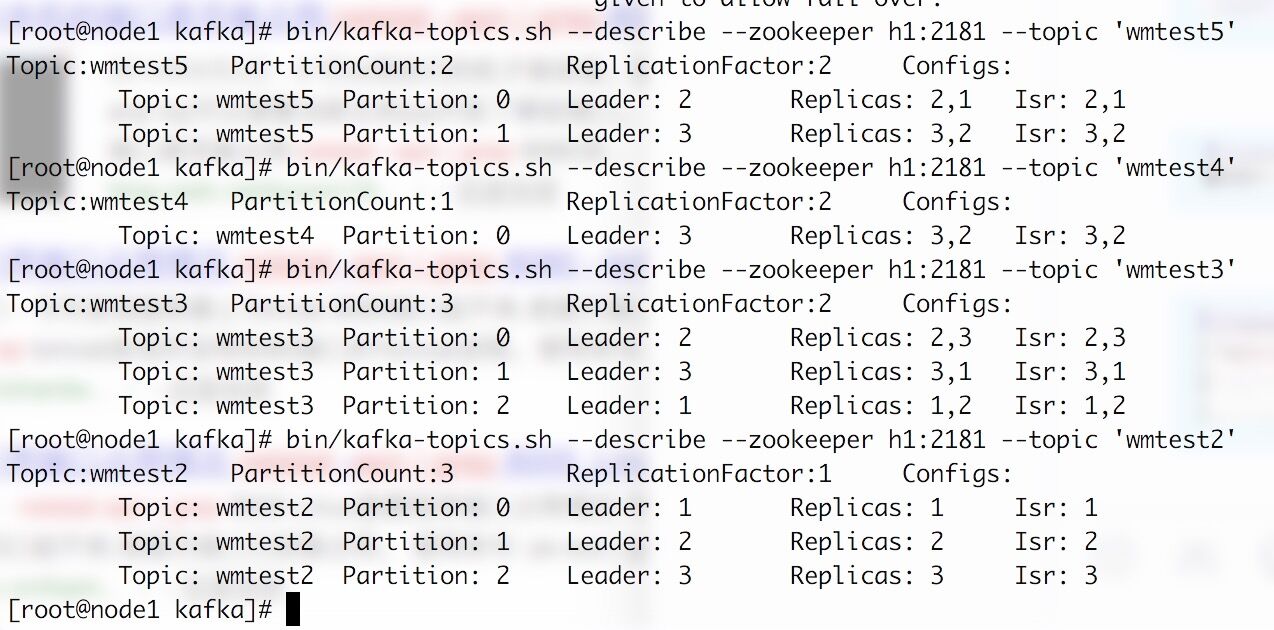
Leader: 如果有多個brokerBroker儲存同一個topic,那麼同時只能有一個Broker負責該topic的讀寫,其它的Broker作為實時備份。負責讀寫的Broker稱為Leader.
Replicas : 表示該topic的幾號分割槽在哪幾個broker中儲存
Isr : 表示當前有效的broker, Isr是Replicas的子集
現在殺掉一個broker,操作如下
切到第三臺機器,為這裡是h3,jps一下
然後殺死程序,再看下kafka topic 'wmtest5'的情況

Isr:現在有效的broker就是2了,3已經沒了
本來partition1的leader是3,也變成2了
再啟動你就發現,Isr有效的broker中3回來了,但是leader還是2
http://blog.csdn.net/wangjia184/article/details/37921183這篇文章也詳細介紹了,我所說的東西,還不錯
-----------------------現在開始講解專案工程
首先建一個maven工程
pom檔案如下
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.9.0.0</version>
</dependency>就引入這些就可以了
我這裡一開始也按照網上流程,那樣搭建,跑是能跑起來,但有些我需要模擬但就跑不起來了
一共要建5個類
package com.wm.utilm2;
import java.util.ArrayList;
import java.util.List;
/**
* Created by wangmiao on 2017/6/9.
*/
public class ConsumerGroup {
private List<ConsumerRunnable> consumers;
public ConsumerGroup(int consumerNum, String groupId, String topic, String brokerList) {
consumers = new ArrayList<ConsumerRunnable>(consumerNum);
for (int i = 0; i < consumerNum; ++i) {
ConsumerRunnable consumerThread = new ConsumerRunnable(brokerList, groupId, topic);
consumers.add(consumerThread);
}
}
public void execute() {
for (ConsumerRunnable task : consumers) {
new Thread(task).start();
}
}
}
package com.wm.utilm2;
/**
* Created by wangmiao on 2017/6/9.
*/
public class ConsumerMain {
public static void main(String[] args) {
String brokerList = "h1:9092,h2:9092,h3:9092";
String groupId = "testGroup1";
String topic = "test3";
int consumerNum = 1;
ConsumerGroup consumerGroup = new ConsumerGroup(consumerNum, groupId, topic, brokerList);
consumerGroup.execute();
}
}
package com.wm.utilm2;
/**
* Created by wangmiao on 2017/6/9.
*/
public class ConsumerMainTwo {
public static void main(String[] args) {
String brokerList = "h1:9092,h2:9092,h3:9092";
String groupId = "testGroup2";
String topic = "test3";
int consumerNum = 1;
ConsumerGroup consumerGroup = new ConsumerGroup(consumerNum, groupId, topic, brokerList);
consumerGroup.execute();
}
}
package com.wm.utilm2;
import kafka.consumer.*;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.springframework.util.CollectionUtils;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
/**
* Created by wangmiao on 2017/6/8.
*/
public class ConsumerRunnable implements Runnable {
// 每個執行緒維護私有的KafkaConsumer例項
private final KafkaConsumer<String, String> consumer;
public ConsumerRunnable(String brokerList, String groupId, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("enable.auto.commit", "true"); //本例使用自動提交位移
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic)); // 本例使用分割槽副本自動分配策略
}
public void run() {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(200); // 本例使用200ms作為獲取超時時間
for (ConsumerRecord<String, String> record : records) {
// 這裡面寫處理訊息的邏輯,本例中只是簡單地列印訊息
System.out.println(Thread.currentThread().getName() + " consumed " + record.partition() +
" ------message is :" + new String(record.value()));
}
}
}
}
package com.wm.util;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.Random;
/**
* Created by wangmiao on 2017/6/8.
*/
public class KafkaProducerTest extends Thread {
private String topic;
public KafkaProducerTest(String topic){
super();
this.topic = topic;
}
@Override
public void run() {
KafkaProducer<String,String> producer =createProducer();
int i=0;
while(true) {
String msg = "test wm shuai"+i++;
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(topic, msg);
producer.send(producerRecord);
System.out.println("send " + msg);
try {
Thread.sleep(5000);
}catch (Exception e){
e.printStackTrace();
}
}
}
private KafkaProducer createProducer(){
Properties props = new Properties();
// props.setProperty("zookeeper.connect","h1:2181,h2:2181,h3:2181");
// props.setProperty("serializer.class", StringEncoder.class.getName());
// props.setProperty("metadata.broker.list","h1:9092,h2:9092,h3:9092");
// props.setProperty("partitioner.class","com.wm.util.PersonalPartition");
props.put("bootstrap.servers", "h1:9092,h2:9092,h3:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return new KafkaProducer(props);
}
public static void main(String arg[]){
new KafkaProducerTest("test1").start();
}
}
ConsumerMainTwo 和 ConsumerMain 是模擬兩個使用者組,但每個使用者組只有一個使用者去消費資訊(同時啟動兩個main方法看下消費訊息的情況)
可以看到不同的使用者組,可以消費同一個topic資訊,
可以改變 consumerNum 來模擬一個使用者組裡的使用者數,但這個使用者數不能超過partition的數量,不然又得使用者是收不到訊息的,因為會被組裡的其他使用者給消費掉。
當之只有一個使用者的時候,消費掉水partition1,2,3但是有兩個使用者組的時候訊息會被分配一個使用者消費兩條,一個使用者消費1條。
如何模擬呢:ConsumerMain的consumerNum設定為1,啟動兩個consumerNum,看到消費情況,然後再kill掉一個,再看看消費情況。
使用者組的幾種情況就完美模擬了