
用正向和逆向最大匹配演算法進行中文分詞(續)
阿新 • • 發佈:2019-01-12
一、結果分析:
1.程式執行結果,如下圖所示:
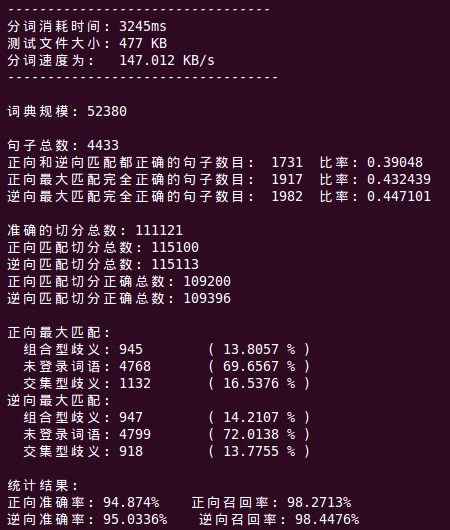
(1)正向和逆向匹配都正確的句子數目為 1731,佔句子總數的39.0%
(2)正向最大匹配完全正確的句子數目為 1917,佔句子總數的43.2%
(3)逆向最大匹配完全正確的句子數目為 1982,佔句子總數的44.7%
(4)至少有一種方法分析正確的句子數為 2168,佔句子總數的48.9%
3.逆向最大匹配比正向最大匹配的準確率和召回率都高。
4.錯誤分析
(1)未登入詞導致的錯誤佔大部分,約70%左右,是導致分詞錯誤的主要因素。
(2)面對交集型歧義,正向最大匹配比逆向最大匹配更容易出錯。
(3)面對組合型歧義,正向最大匹配和逆向最大匹配都無能為力。
二、主要問題分析:
1.準確率為什麼低於召回率;
二者的計算公式如下:
準確率 = 切分正確的詞 / 切分得到的詞數
召回率 = 切分正確的詞 / 準確的詞數
從上述公式來看,他們的區別在於分母。通過對切分錯誤的漢字串的分析,發現未登入詞在其中佔了相當大的比例,大概四分之三左右。演算法對於未登入詞的處理方式是:將它們按照單字進行切分,這樣勢必導致切分出來的詞的數量比真實值偏大。雖然也存在一些組合型歧義問題使切分出來的詞的數量傾向於減少,但是這種情形較少,只佔所有錯誤漢子串的十分之一左右。因此從總體上來看,實際切分得到的詞的數目會比真實的詞的數目要大,所以最終得到的準確率低於召回率。
2.逆向匹配的準確率和召回率為什麼高於正向匹配?
逆向切分的錯誤較少。錯誤分三類:未登入詞、組合型歧義、交集型歧義。其中未登入詞對於兩種切分方式來說是差不多的,組合型歧義也是相差無幾。主要的區別在於交集型歧義問題,對於漢字串ABC,正向切分得到AB /C,逆向切分得到A/BC。在實際應用中,大多數的交集型歧義傾向於切分為A/BC這種形式。因此,正向匹配的錯誤數量相對來說較高。至於為什麼漢語的交集型歧義傾向於切分為A/BC這種形式,那可能涉及到語言學的知識了。
3.錯誤分詞的主要問題什麼?主流的解決辦法是什麼?
從分詞的結果來看,錯誤主要分為三類:
(1)組合型歧義,該切分而未切分的詞。正向切分中大概佔13.8%,逆向切分中大概佔14.2%。
某些漢字串,它本身是詞,切開來也是詞,這就造成了組合型歧義。比如:比如“就是”,它本身是一個詞,其中的“就”和“是”也都可以單獨作為一個詞。
組合型歧義同最大匹配的原則是相矛盾的。最大匹配法的實質是要求切分出來的詞的數量儘可能地少,而組合型歧義切分問題的存在,卻要求考慮將這樣的詞再切分一次的可能性。如果不利用句法以及更高層面上的知識,組合型歧義切分是很難解決的。要利用上下文的語境資訊進行識別。
(2)交集型歧義。正向切分中大概佔16.5%,逆向切分中大概佔13.8%。
交集型歧義切分是指,一個漢字串中包含ABC三個子串,AB和BC都是詞,到底應該切分為A/BC還是AB/C。按照最大匹配切分方式,正向切分得到AB /C,逆向切分得到A/BC。因此,對同一個漢字串同時進行正向切分和逆向切分,可以檢查出一部分交集型歧義,但是未必能發現所有的交集型歧義。
解決交集型歧義,可以用統計學的手段計算出可能性最大的一種切分方式。可以利用最大概率法,基於支援向量機的方法,最大熵模型。
這兩種歧義的區別為:交集型歧義的問題在於在哪裡切分,組合型歧義的問題在於該不該切。
(3)未登入詞。正向切分中大概佔69.66%,逆向切分中大概佔72.01%。
即詞典中不存在的詞。一些未登入詞是比較生僻的、不常用的詞,如糌粑。還有一些是專有名詞、人名、地名等。
未登入詞識別的基本方法主要採用的是:基於規則的方法和統計與規則相結合的方法。從目前的研究來看,多是對人名、地名、機構名等進行單獨的識別研究。基於統計的方法是根據統計得到的各類用字的頻度,加入構詞可信度等概念進行識別。統計與規則相結合的方法是根據未登入詞的用字規律和上下文特徵,觀察未登入詞與標誌位置的關係以及單詞的左右結構,總結出適合絕大多數未登入詞的識別規則,將規則應用於漢語文字的處理過程,從而識別未登入詞。