
機器學習:特徵工程
特徵選擇直接影響模型靈活性、效能及是否簡潔。
好特徵的靈活性在於它允許你選擇不復雜的模型,同時執行速度也更快,也更容易理解和維護。
特徵選擇
四個過程:產生過程,評價函式,停止準則,驗證過程。
目的:過濾特徵集合中不重要特徵,挑選一組最具統計意義的特徵子集,從而達到降維的效果。
選擇標準:特徵項和類別項之間的相關性(特徵重要性)。
- - -搜尋特徵子空間的產生過程- - -
搜尋的演算法分為完全搜尋(Complete),啟發式搜尋(Heuristic), 隨機搜尋(Random) 3大類。
完全搜尋包括(4種):廣度優先搜尋(窮舉法)、分支限界搜尋(窮舉法+剪枝)、 定向搜尋(選擇TopN)、最優優先搜尋(TopN問題不限制N)
啟發式搜尋包括(6種):
序列前向選擇SFS(簡單貪心,每次選使評價函式達到最優的特徵)、序列後向選擇SBS(簡單貪心,每次剔除特徵)、 雙向搜尋BDS(SFS與SBS同時開始,碰撞時結束);
增L去R選擇演算法 LRS(空集開始先加L後去R、全集開始先去R後加L)、序列浮動選擇(LRS法不固定L與R)、決策樹搜尋(讓樹充分生長、然後剪枝,通過資訊熵評價)
隨機演算法搜尋(3種):隨機產生序列選擇演算法RGSS(隨機產生特徵子集,執行SFS或SBS)、模擬退火演算法SA(克服序列搜尋區域性最優、但最優解區域很小時不適用)、遺傳演算法GA(隨機產生特徵子集,評分,然後交叉、突變等繁衍出下一代特徵子集)
- - - - 特徵選擇與評價函式 - - - -
評價函式的作用是評價產生過程所提供的特徵子集的好壞。
評價函式根據其工作原理,主要分為篩選器(Filter)、封裝器( Wrapper )兩大類。
封裝器實質上是一個分類器,封裝器用選取的特徵子集對樣本集進行分類,分類的錯誤率作為衡量特徵子集好壞的標準。
篩選器通過分析特徵子集內部的特點來衡量其好壞。篩選器一般用作預處理,與分類器的選擇無關。特徵選擇法主要指篩選器的選擇方法。
篩選器選擇特徵:
預處理:首先去掉取值變化小的特徵(對系統影響最小、最不重要的特徵),接下來有四種方法:
單變數的特徵選擇方法、基於機器學習模型的選擇法、隨機森林法、頂層特徵選擇法(基於不同的模型選擇法)
1.單變數的特徵選擇方法
獨立地衡量每個特徵與響應變數之間的關係,分為兩大類:
基於距離計算的特徵選擇——Pearson相關係數,Gini-index(基尼指數),IG(資訊增益)、常規距離公式;
基於樹與交叉驗證的特徵選擇法——適用於非線性關係。
(1) Pearson相關係數
按照大學的線性數學水平來理解, 它可以看做是兩組資料的向量夾角的餘弦。
皮爾遜相關的約束條件:兩變數獨立、兩個變數間有線性關係、變數是連續變數、均符合正態分佈且二元分佈也符合正態分佈。
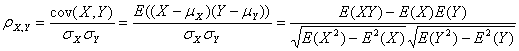


評價:
Pearson相關係數結果取值區間為[-1,1],-1表示完全的負相關(這個變數下降,那個就會上升),+1表示完全的正相關,0表示沒有線性相關。
優點:速度快、易於計算,經常在拿到資料(經過清洗和特徵提取之後的)之後第一時間就執行。
缺點:只對線性關係敏感。如果關係是非線性的,即便兩個變數具有一一對應的關係,Pearson相關性也可能會接近0。
(2) Gini-index(基尼指數)
 基尼公式
其中,X代表各組的人口比重,Y代表各組的收入比重,V代表各組累計的收入比重,i=1,2,3,…,n,n代表分組的組數。
GiniIndex的演算法為IBM智慧挖掘所使用的方法。
(3) IG(資訊增益)
基尼公式
其中,X代表各組的人口比重,Y代表各組的收入比重,V代表各組累計的收入比重,i=1,2,3,…,n,n代表分組的組數。
GiniIndex的演算法為IBM智慧挖掘所使用的方法。
(3) IG(資訊增益)G(D,A)=H(D)-H(D|A)
系統資訊熵:
![clip_image002[4]](http://www.blogjava.net/images/blogjava_net/zhenandaci/WindowsLiveWriter/7fce385fe28b_D158/clip_image002%5B4%5D.gif "clip_image002[4]")
條件熵(指特徵X被固定為值xi時):
![clip_image002[6]](http://www.blogjava.net/images/blogjava_net/zhenandaci/WindowsLiveWriter/7fce385fe28b_D158/clip_image002%5B6%5D_thumb.gif)
條件熵(指特徵X被固定時):
![clip_image002[8]](http://www.blogjava.net/images/blogjava_net/zhenandaci/WindowsLiveWriter/7fce385fe28b_D158/clip_image002%5B8%5D_thumb.gif)
資訊增益:
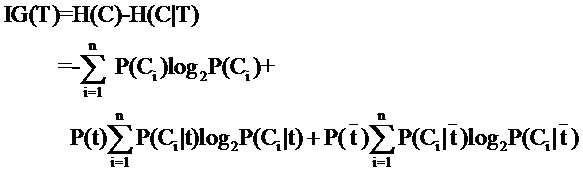
(4) 常規距離公式 (Distance Metrics )
運用距離度量進行特徵選擇是基於這樣的假設:好的特徵子集應該使得屬於同一類的樣本距離儘可能小,屬於不同類的樣本之間的距離儘可能遠。
常用的距離度量(相似性度量)包括歐氏距離、標準化歐氏距離、馬氏距離等。
(5) 基於樹與交叉驗證的特徵選擇法
假如某個特徵和響應變數之間的關係是非線性的,可以用基於樹的方法(決策樹、隨機森林)、交叉驗證、擴充套件的線性模型等。
基於樹的方法比較易於使用,因為他們對非線性關係的建模比較好,並且不需要太多的除錯。但要注意過擬合問題,因此樹的深度最好不要太大。
2.基於機器學習模型的選擇法
有些機器學習方法本身就具有對特徵進行打分的機制,或者很容易將其運用到特徵選擇任務中,例如迴歸模型,SVM,決策樹,隨機森林等等。
在一些地方叫做wrapper型別,大意是,特徵排序模型和機器學習模型是耦盒在一起的,對應的非wrapper型別的特徵選擇方法叫做filter型別。
例如在迴歸模型中利用的係數來選擇特徵。越是重要的特徵在模型中對應的係數就會越大,而跟輸出變數越是無關的特徵對應的係數就會越接近於0。在噪音不多的資料上,或者是資料量遠遠大於特徵數的資料上,如果特徵之間相對來說是比較獨立的,那麼即便是運用最簡單的線性迴歸模型也一樣能取得非常好的效果。同樣的方法和套路可以用到類似的線性模型上,比如邏輯迴歸。
正則化模型:就是把額外的約束或者懲罰項加到已有模型(損失函式)上,以防止過擬合併提高泛化能力。損失函式由原來的E(X,Y)變為E(X,Y)+alpha||w||,w是模型係數組成的向量(有些地方也叫引數parameter,coefficients),||·||一般是L1或者L2範數,alpha是一個可調的引數,控制著正則化的強度。當用線上性模型上時,L1正則化和L2正則化也稱為Lasso和Ridge。
3. 隨機森林
隨機森林具有準確率高、魯棒性好、易於使用等優點,這使得它成為了目前最流行的機器學習演算法之一。
隨機森林提供了兩種特徵選擇的方法:平均不純度減少、平均精確率減少。
(1) 平均不純度減少 (mean decrease impurity)
隨機森林由多個決策樹構成。決策樹中的每一個節點都是關於某個特徵的條件,為的是將資料集按照不同的響應變數一分為二。利用不純度可以確定節點(最優條件),對於分類問題,通常採用基尼不純度或者資訊增益,對於迴歸問題,通常採用的是方差或者最小二乘擬合。當訓練決策樹的時候,可以計算出每個特徵減少了多少樹的不純度。對於一個決策樹森林來說,可以算出每個特徵平均減少了多少不純度,並把它平均減少的不純度作為特徵選擇的值。
使用基於不純度的方法的時候,要注意:
1、這種方法存在偏向,對具有更多類別的變數會更有利;
2、對於存在關聯的多個特徵,其中任意一個都可以作為指示器(優秀的特徵),並且一旦某個特徵被選擇之後,其他特徵的重要度就會急劇下降,因為不純度已經被選中的那個特徵降下來了,其他的特徵就很難再降低那麼多不純度了,這樣一來,只有先被選中的那個特徵重要度很高,其他的關聯特徵重要度往往較低。在理解資料時,這就會造成誤解,導致錯誤的認為先被選中的特徵是很重要的,而其餘的特徵是不重要的,但實際上這些特徵對響應變數的作用確實非常接近的(這跟Lasso是很像的)。
特徵隨機選擇方法稍微緩解了這個問題,但總的來說並沒有完全解決。
(2) 平均精確率減少 (Mean decrease accuracy)
主要思路是直接度量每個特徵對模型精確率的影響,通過打亂每個特徵的特徵值順序,來度量順序變動對模型的精確率的影響。
很明顯,對於不重要的變數來說,打亂順序對模型的精確率影響不會太大,但是對於重要的變數來說,打亂順序就會降低模型的精確率。
4. 兩種頂層特徵選擇演算法
之所以叫做頂層,是因為他們都是建立在基於模型的特徵選擇方法基礎之上的,例如迴歸和SVM,在不同的子集上建立模型,然後彙總最終確定特徵得分。
有兩種方法:穩定性選擇 (Stability selection);遞迴特徵消除RFE (Recursive feature elimination)
穩定性選擇是一種基於二次抽樣和選擇演算法相結合較新的方法,選擇演算法可以是迴歸、SVM或其他類似的方法。它的主要思想是在不同的資料子集和特徵子集上執行特徵選擇演算法,不斷的重複,最終彙總特徵選擇結果。比如可以統計某個特徵被認為是重要特徵的頻率(被選為重要特徵的次數除以它所在的子集被測試的次數)。理想情況下,重要特徵的得分會接近100%。稍微弱一點的特徵得分會是非0的數,而最無用的特徵得分將會接近於0。
遞迴特徵消除的主要思想是反覆的構建模型(如SVM或者回歸模型)然後選出最好的(或者最差的)的特徵(可以根據係數來選),把選出來的特徵放到一遍,然後在剩餘的特徵上重複這個過程,直到所有特徵都遍歷了。這個過程中特徵被消除的次序就是特徵的排序。因此,這是一種尋找最優特徵子集的貪心演算法。
- - - - 過濾器方法的簡單比較 - - - -
Lasso能夠挑出一些優質特徵,同時讓其他特徵的係數趨於0。當如需要減少特徵數的時候它很有用,但是對於資料理解來說不是很好用。(例如在結果中,X11,X12,X13的得分都是0,好像他們跟輸出變數之間沒有很強的聯絡,但實際上不是這樣的)
MIC對特徵一視同仁,這一點上和關聯絡數有點像。另外,它能夠找出X3和響應變數之間的非線性關係。
隨機森林基於不純度的排序結果非常鮮明。在得分最高的幾個特徵之後的特徵,得分急劇的下降。從表中可以看到,得分第三的特徵比第一的小4倍。而其他的特徵選擇演算法就沒有下降的這麼劇烈。
Ridge將回歸係數均勻的分攤到各個關聯變數上,從表中可以看出,X11,…,X14和X1,…,X4的得分非常接近。
穩定性選擇常常是一種既能夠有助於理解資料又能夠挑出優質特徵的這種選擇。像Lasso一樣,它能找到那些效能比較好的特徵(X1,X2,X4,X5),同時,與這些特徵關聯度很強的變數也得到了較高的得分。
參考資料:
相關推薦
機器學習:特徵工程
特徵選擇直接影響模型靈活性、效能及是否簡潔。 好特徵的靈活性在於它允許你選擇不復雜的模型,同時執行速度也更快,也更容易理解和維護。 特徵選擇 四個過程:產生過程,評價函式,停止準則,驗證過程。 目
系統學習機器學習之特徵工程(二)--離散型特徵編碼方式:LabelEncoder、one-hot與啞變數*
轉自:https://www.cnblogs.com/lianyingteng/p/7792693.html 在機器學習問題中,我們通過訓練資料集學習得到的其實就是一組模型的引數,然後通過學習得到的引數確定模型的表示,最後用這個模型再去進行我們後續的預測分類等工作。在模型訓練過程中,我們會對訓練
機器學習-2.特徵工程和文字特徵提取
1. 資料集的組成 前面講了,機器學習是從歷史資料當中獲得規律,那這些歷史資料的組成是個什麼格式?大都儲存在哪裡? – 在機器學習裡大多數資料不會存在資料庫中,大都存在檔案中(比如csv檔案) – 不存在資料庫原因:1. 讀取速度導致存在效能瓶頸。2. 儲存的格式不太符合機器學習
【機器學習】特徵工程多特徵值序列化數值化獨熱編碼處理(LabelEncoder, pd.factorize())
多特徵值序列化數值化獨熱編碼處理 當我們在運用某些模型時,比如在Scikit-learn中,它要求資料都得是numberic(數值型),若是文字型別就無法進行訓練。 那麼在這種情況下,我們就應該先對資料進行序列化數值化: 下面是幾種在Python中數值化的方法: 1
機器學習之特徵工程-資料預處理
摘自 jacksu在簡書 機器學習之特徵工程-資料預處理 https://www.jianshu.com/p/23b493d38b5b 通過特徵提取,我們能得到未經處理的特徵,這時的特徵可能有以下問題: 不屬於同一量綱:即特徵的規格不一樣,不能夠放在
Python機器學習之特徵工程
import numpy as np import matplotlib.pyplot as plt import pandas as pd import seaborn as sns from sklearn.model_selection import
機器學習之特徵工程
首先,給一張特徵工程的思維導圖: 【如果要瀏覽圖片,建議將其下載到本地,使用圖片瀏覽軟體檢視】 關於特徵工程(Feature Engineering),已經是很古老很常見的話題了,坊間常說:“資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已”。由此可見,特徵工程在機器學習中佔
機器學習之特徵工程-特徵選擇
點選“閱讀原文”直接開啟【北京站 | GPU CUDA 進階課程】報名連結 一個基本的資料探勘場景如下: 資料探勘.jpg 從上面的資料探勘場景可知,當資料預處理完成後,我們需要選擇有意義的特徵,輸入機器學習的演算法模型進行訓練。通常來說,從兩個方面考慮來選擇特徵: 特徵是否發散:如果一個特徵
系統學習機器學習之特徵工程(一)--維度歸約
這裡,我們討論特徵選擇和特徵提取,前者選取重要的特徵子集,後者由原始輸入形成較少的新特徵,理想情況下,無論是分類還是迴歸,我們不應該將特徵選擇或特徵提取作為一個單獨的程序,分類或者回歸方法應該能夠利用任何必要的特徵,而丟棄不相關的特徵。但是,考慮到演算法儲存量和時間的複雜度,
機器學習2-特徵工程
特徵工程 特徵抽取 文字特徵提取-CountVectorizer 作用:對文字資料進行特徵值化 sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回詞頻矩陣 CountVect
機器學習筆記4:特徵工程
一、特徵工程概述 “資料決定了機器學習的上限,而演算法只是儘可能逼近這個上限”,這裡的資料指的就是經過特徵工程得到的資料。特徵工程指的是把原始資料轉變為模型的訓練資料的過程,它的目的就是獲取更好的訓練資料特徵,使得機器學習模型逼近這個上限。特徵工程能使得模型的效能
機器學習:Scikit-learn與特徵工程
“資料決定了機器學習的上限,而演算法只是儘可能逼近這個上限”,這句話很好的闡述了資料在機器學習中的重要性。大部分直接拿過來的資料都是特徵不明顯的、沒有經過處理的或者說是存在很多無用的資料,那麼需要進行一些特徵處理,特徵的縮放等等,滿足訓練資料的要求。我們將初次接觸到Sciki
機器學習:sklearn模型指標和特徵貢獻度檢視
模型訓練完成後,即使模型評估很好,各項指標都很到位,業務人員肯定也是心裡沒底的,哪怕有模型公式,他們也看不懂啊。咋整,當然是先把模型的重要評估指標列印給他們看,再把特徵貢獻度從大到小,畫成圖給他們看啦。今天就通過sklearn實現模型評估指標和特徵貢獻度的圖形檢視。 本文的資料集採用泰坦尼克號倖
AI學習筆記:特徵工程
實踐篇
class rom enter instr function ont 線性 gin 向量 線性回歸(linear regression)實踐篇 之前一段時間在coursera看了Andrew ng的機器學習的課程,感覺還不錯,算是入門了。這次打算以該課程的作業
機器學習:Python實現聚類算法(三)之總結
.fig ask class ted ssi 缺點 處理 blob ron 考慮到學習知識的順序及效率問題,所以後續的幾種聚類方法不再詳細講解原理,也不再寫python實現的源代碼,只介紹下算法的基本思路,使大家對每種算法有個直觀的印象,從而可以更好的理解函數中
機器學習:線性判別式分析(LDA)
get generated 分類 learn 參數 關註 ble 直線 圖片 1.概述 線性判別式分析(Linear Discriminant Analysis),簡稱為LDA。也稱為Fisher線性判別(Fisher Linear Disc
機器學習:緒論
訓練 ner special dict ttr 空間 attr cti 輸出 學習教材為周誌華教授的西瓜書《機器學習》 1.2 基本術語 維數 dimensionality 示例 instance 屬性或特征 attribute or feature 特征向量 featur
機器學習:模型評估和選擇
val 上一個 bootstrap 自助法 break all 誤差 rec 數據集 2.1 經驗誤差與擬合 精度(accuracy)和錯誤率(error rate):精度=1-錯誤率 訓練誤差(training error)或經驗誤差(empirical error) 泛