
[深度學習大講堂]從NNVM看2016年深度學習框架發展趨勢
本文為微信公眾號[深度學習大講堂]特約稿,轉載請註明出處
虛擬框架殺入

從發現問題到解決問題
半年前的這時候,暑假,我在SIAT MMLAB實習。
看著同事一會兒跑Torch,一會兒跑MXNet,一會兒跑Theano。
SIAT的伺服器一般是不給sudo許可權的,我看著同事掙扎在編譯這一坨框架的海洋中,開始思考:
是否可以寫一個框架:
import xx.tensorflow as tensorflow import xx.mxnet as mxnet import xx.theano as theano import xx.caffe as caffe
這樣,利用工廠模式只編譯執行部件的做法,只需編譯唯一的後端即可,框架的不同僅僅在於前端指令碼的不同。
Caffe2Keras的做法似乎是這樣,但Keras本身是基於Theano的編譯後端,而我們的更希望Theano都不用編譯。
當我9月份拍出一個能跑cifar10的大概原型的時候:
import dragon.vm.caffe as caffe import dragon.vm.theano as theano import dragon.updaters as updaters if __name__ == '__main__': net = caffe.Net('cifar10.prototxt') loss = net.blobs['loss'].data updater= updaters.SGDUpdater(base_lr=0.001, momentum=0.9, l2_decay=0.004) for k,v in net.params().iteritems(): for blob in v: updater.append(v, theano.grad(loss, v)) train = theano.function(outputs=loss) update = theano.function(updater=updater) max_iters = 2333 iter= 0 while iter < max_iters: train() update()
我為這種怪異的寫法取名叫CGVM(Computational Graph Virtual Machine)
然後過了幾天,在微博上看到了陳天奇在MXNet的進一步工作NNVM的釋出 (o(╯□╰)o)......
NNVM使用2000行模擬出了TensorFlow,我大概用了500行模擬出了Caffe1。
VM(Virtual Machine)的想法其實是一個很正常的想法,這幾年我們搞了很多新框架,
名字一個比一個炫,但是本質都差不多,框架的使用者實際上是苦不堪言的:
○ 這篇paper使用了A框架,我要花1天配置A框架。
○ 這篇paper使用了B框架,我要花1天配置B框架。
.......
正如LLVM不是一種編譯器,NNVM也不是一種框架,看起來更像是框架的屠殺者。
NNVM的可行性恰恰證明了現行的各大框架底層的重複性,而上層的多樣性只是一個幌子。
我們真的需要為僅僅是函式封裝不同的框架買單嗎?這是值得思考的。
計算圖走向成熟

計算圖的兩種形式
計算圖最早的出處應該是追溯到Bengio在09年的《Learning Deep Architectures for AI》,
Bengio使用了有向圖結構來描述神經網路的計算:
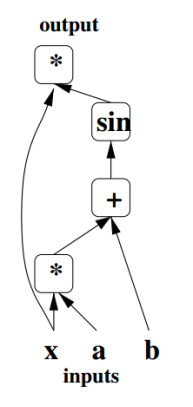
如圖,符號集合{*,+,sin} 構成圖的結點,整張圖可看成三部分:輸入結點、輸出結點、從輸入到輸出的計算函式。
隨後在Bengio組的Theano框架執行中,Graph就被隱式應用於Op的連線。
不過這時候,Op還是執行時-動態編譯的。
Caffe1中計算圖其實就是Net,因為Net可以被Graph模擬出來(CGVM和Caffe2Keras都實現了)。
賈揚清在Caffe1中顯式化了計算圖的表示,使用者可以通過編輯net.prototxt來設計計算圖。
Caffe1在Jonathan Long和Evan Shelhamer接手後,他們開發了PyCaffe。
PyCaffe通過Python天然的工廠(__getattr__),實現了net.prototxt的隱式生成。
之後的Caffe2,也就直接取消了net.prototxt的編輯,同樣利用Python的(__getattr__)獲取符號型別定義。
Caffe1帶來一種新的計算圖組織Op的描述方式,不同於Theano直接翻譯Op為C執行程式碼,然後動態編譯,
軟體工程中的高階設計模式——工廠模式被廣泛使用。
計算圖被劃分為三個階段,定義階段、構造階段、執行階段:
1、定義階段:定義Layer/Op的name、type、bottom(input),top(output)及預設引數。
2、構造階段:通過工廠模式,由字串化的定義指令碼構造類物件。
3、執行階段:根據傳入的bottom(input),得到額外引數(如shape),此時計算圖才能開始執行。
階段劃分帶來的主要問題是限制了編譯程式碼的完整性和優化程度。
在Theano中,C程式碼生成是最後一步,你可以組合數片細粒度的程式碼塊,依靠編譯器做硬體執行前的超級優化。
編譯器優化是的提升指令流水線效率的重要手段,編譯器排程技術減少資料衝突,編譯器分支預測技術減少控制衝突。
而工廠模式編譯符號時只考慮了單元本身,編譯器沒有上下文環境可供參考,故最終只能順序執行多個預先編譯的符號單元。
當符號粒度過細時,一個Layer的實現就會變成連續執行數個單元,每個單元都要處理一遍向量/矩陣,導致“TensorFlowSlow”。
計算圖作為中間表示(IR)
PyCaffe和Caffe2將定義階段移到Python中,而將構造和執行階段保留在C++中做法,是計算圖作為IR的思想啟蒙。
Python與C++最大的不同在於:一個是指令碼程式碼,用於前端。一個是原生代碼,用於後端。
指令碼程式碼建立/修改模型方便(無需因模型變動而重新編譯)、執行慢,原生代碼則正好相反。
兩者取長補短,所以深度學習框架在2016年,迎來了前後端開發的黃金時代。
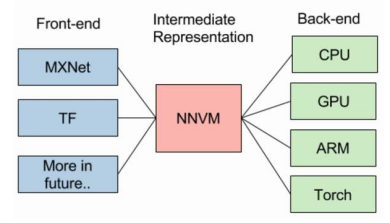
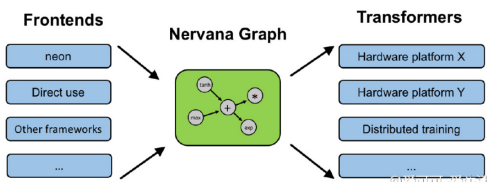
如上圖,無論是9月份先提出的NNVM,還是最近Intel曝光的Nervana,都分離了前後端。
後端的獨立,不僅減少了編譯工作,最大的優勢在於降低了傳統框架做跨裝置計算的程式碼耦合度。
在paper每週都有一大堆的現在,如果後端的每一次變動都要大量修改前端,那麼框架的維護開銷是非常大的。
在前端定義用於描述輸入-輸出關係的計算圖有著良好的互動性,我們可以通過函式和過載指令碼語言的操作符,
定義出媲美MATLAB的運算語言,這些語言以顯式的Tensor作為資料結構,Operator作為計算符和函式,
Theano和MXNet都是這樣隱蔽處理由表示式向計算圖過渡的。
而Caffe2則比較直接,你需要先建立一個Graph,然後顯示地呼叫Graph.AddOperator(xxx)
TensorFlow同樣可以顯式化處理Graph。
與使用者互動得到的計算圖描述字串是唯一的,但是與使用者互動的方式卻是不唯一的。
所以IR之上,分為兩派:
第一派要搞自己的API,函式封裝非常有個性,宣示這是自己的專利、獨門語言。
第二派不搞自己的API,反而去模擬現有的API,表示我很低調。
顯然,使用者更喜歡用自己熟悉框架的寫法去描述模型,不喜歡天天揹著個函式速查手冊。
計算圖優化
用於中間表示得到的計算圖描述最好不要直接構造,因為存在冗餘的求解目標,且可共享變數尚未提取。
當限制計算圖描述為有向無環圖(DAG)時,一些基本的圖論演算法便可應用於計算圖描述的化簡與變換。
陳天奇在今年的MSR Talk:Programming Models and Systems Design for Deep Learning中,總結了計算圖優化的三個點:

①依賴性剪枝
分為前向傳播剪枝,例:已知A+B=X,A+B=Y,求X?
反向傳播剪枝, 例:A+B=X,A+B=Y,求X、Y,dX/dA?
根據使用者的求解需求,可以剪掉沒有求解的圖分支。
②符號融合
符號融合的自動實現是困難的,因為Kernel基本不再實時編譯了,所以更多體現在符號粗細粒度的設計上。
粗粒度的符號融合了數個細粒度的符號,一次編譯出連續多個執行步驟的高效率程式碼。
粗粒度和細粒度並無好壞區分,一個速度快,一個更靈活。
從貪心角度,VM框架通常會提供粗細粒度兩種實現給使用者,因而需要更多人力維護編譯後端。
③記憶體共享
Caffe1對於啟用函式大多使用的inplace處理——即bottom和top是同一個Blob。
inplace使用新的輸出y立即覆蓋的輸入x,需要以下兩個條件:
1、bottom和top數量都為1,即:計算圖中構成一條直線路徑,
2、d(y)/d(x)與x是無關的,所以x被y覆蓋不影響求導結果。
常見的啟用函式都符號以上兩個條件,因而可以減少記憶體的開銷。
但是Caffe1在多網路記憶體共享優化上極其糟糕的,以至於Caffe1並不適合用來跑GAN,以及更復雜的網路。
一個簡單例子是交叉驗證上的優化:訓練網路和驗證網路的大部分Layer都是可以共享的,
但是由於Caffe1錯誤地將Blob獨立的放在每個Net裡,使得跨Net間很難共享資料。
除此之外,Caffe1還錯誤地將臨時變數Blob獨立放在每個Layer裡,導致列卷積重複佔用幾個G記憶體。
讓Net和Layer都能共享記憶體,只需要將Tensor/Blob置於最頂層,採用MVC來寫框架即可。
Caffe2引入了Workspace來管理Tensor,並將工作空間的指標傳給每一個Op、每一個Graph的建構函式。
這將使記憶體區域完全暴露在全域性(類似MFC的Document),與TensorFlow一樣,提供Feed/Fetch這一組API用於Python的外部訪問。
這種記憶體的管理方式,同時也為模擬Theano的API提供便利(e.g. theano.shared和get_value,本質就是Feed與Fetch)。
使用Workspace優化視訊記憶體,可使Caffe1做列卷積僅比CUDNN多300M(VGG16全連線) / 900M(VGG16全卷積),且時間開銷近似為零。
遺憾的是,Caffe1臃腫、錯誤的程式碼結構似乎是無緣Workspace的引入了(這將面臨大面積的程式碼重寫,後果就是社群爆炸)。
P.S: 賈揚清在知乎還吐槽過Caffe1中大面積錯誤的模板寫法,導致Caffe1似乎也是無緣FP16了..(大家趕緊研究Caffe2吧)
面向計算圖的直接除錯
很多使用者抱怨TensorFlow除錯困難,不像Caffe1那樣更容易命中Bug的要害。
Caffe1的除錯簡單,源於Layer/Op的執行段很容易定位,Debug資訊可以有效的輸出。
而TensorFlow在計算圖之上,為了迎合工業界搞了許多莫名其妙的API。
面向計算圖的除錯技術宗旨就是,可以實時輸出模型執行計算圖的文字描述。
對於一個符號單元而言:
①明確它的輸入輸出是什麼Tensor,附加的靜態引數是什麼。
②它的符號名是什麼,是什麼符號型別,如果懷疑錯了,直接if(name=xxx) {.....} 即可針對性除錯。
對於幾個符號組成的區域性圖單元:
只需要各個符號間輸入輸出的拓撲連線關係,這個和看net.prototxt沒什麼區別。
以上兩種規格的單元除錯,最好能夠跳過API,直接暴露給使用者。
只要符號單元的實現正確、計算圖的拓撲連線及傳入引數正確,那麼模型的執行結果理論上是不會錯的。
新的風暴已經出現

VM的側重點
CGVM和NNVM的側重點是不太一樣的,CGVM更強調前端上的擴充套件化,後端上的唯一化。
所以CGVM不會去支援Torch編譯後端,也不會去支援Caffe編譯後端。
在NNVM的知乎討論帖中,有一種觀點認為VM是輕視Operator的實現。
但實際上,我們手裡的一堆框架,在Operator、Kernel、Math級別的不少實現是沒有多少區別的。
但恰恰折磨使用者的正是這些沒有多少區別的編譯後端:各種依賴庫、裝Linux、編譯各種錯。
所以我個人更傾向整個DL社群能夠提供一份完善的跨平臺、跨裝置解決方案,而不是多而雜的備選方案。
從這點來看,CGVM似乎是一個更徹底的框架殺手,但在ICML'15上, Jürgen Schmidhuber指出:
真正執行AI 的程式碼是非常簡短的,甚至高中生都能玩轉它。不用有任何擔心會有行業壟斷AI及其研究。
簡短的AI程式碼,未必就是簡單的框架提供的,有可能是自己熟悉的框架,這種需求體現在前端而不是後端。
VM指出了一條多框架混合思路:功能A,框架X寫簡單。功能B,框架Y寫簡單。
功能A和功能B又要end-to-end,那麼顯然混起來用不就行了。
只有使用頻率不高的框架才會消亡,VM將框架混合使用後,熟悉的味道更濃了,那麼便構不成”框架屠殺者“。
強大的AI程式碼,未必就是VM提供的,有可能是龐大的後端提供的。
隨著paper的快速迭代,後端的擴充套件仍然是最繁重的程式設計任務。
VM和後端側重點各有不同,難分好壞。但分離兩者的做法確實是成功的一步。
VM的形式
VM及計算圖描述方式是連線前後端的橋樑。
即便後端是唯一的,根據支援前端的不同,各家寫的VM也很難統一。
實際上這就把框架之間的鬥爭引向了VM之間的鬥爭。
兩人見面談笑風生,與其問對方用什麼框架,不如問對方用什麼VM。
VM的主要工作
合成計算圖描述的過程是乏味的,在Caffe1中,我們恐怕已經受夠了人工編輯prototxt。
API互動方面,即便是MXNet提供給使用者的API也是複雜臃腫的,或許仍然需要一個handbook。
TensorFlow中的TensorBoard借鑑了WebOS,VM上搞一個互動性更強的作業系統也是可行的。
除此之外,我可能比較熟悉一些經典框架,那麼不妨讓VM去實現那些耳熟能詳的函式吧!
1、模擬theano.function
Theano的function是一個非常貼近數學表達計算圖掩飾工具。
function內部轉化表示式為計算圖定義,同時返回一個lambda函式引向計算圖的執行。
總之這是一個百看不膩的API。
2、模擬theano.tensor.grad
結合計算圖優化,我們現在可以指定任意一對求導二元組(cost, wrt)。
因而,放開手,讓自動求導在你的模型中飛舞吧。
3、模擬theano.scan
theano.scan是一個用來搭建RNN的神器。儘管最近Caffe1更新了RNN,但是隻支援固定迴圈步數的RNN。
而theano.scan則可以根據Tensor的shape,為RNN建動態的計算圖,這適合在NLP任務中處理不定長句子。
4、模擬pyCaffe
pyCaffe近來在RCNN、FCN、DeepDream中得到廣泛應用,成為搞CV小夥伴們的最愛。
pyCaffe大部分是由C++資料結構通過Boost.Python匯出的,
不幸的是,Boost.Thread匯出之後與Python的GIL衝突,導致PyCaffe裡無法執行C++執行緒。
嘗試模擬移除Boost.Python後的PyCaffe,在Python裡把Solver、Net、Layer給寫出來吧。
5、模擬你熟悉的任意框架
.......等等,怎麼感覺在寫模擬器.....
當然寫模擬器基本就是在重複造輪子,這個在NNVM的知乎討論帖中已經指明瞭。
VM的重要性
VM是深度學習框架去中心化、解耦化發展邁出的重要一步。
同時暴露了目前框架圈混亂的本質:計算圖之下,眾生平等。計算圖之上,群魔亂舞。
在今年我們可以看多許多框架PK對比的文章,然而大多隻是從使用者觀點出發的簡單評測。
對比之下,NNVM關注度不高、反對者還不少這種情況,確實讓人感到意外。
回顧與展望

回顧2016:框架圈減肥大作戰的開始
高調宣佈開源XXX框架,再封裝一些API,實際上已經多餘了。
VM的出現,將上層介面的編寫引向模擬經典的框架,從而達到減肥的目的。
框架維護者應當將大部分精力主要放在Kernel的編寫上,而不是考慮搞一些大新聞。
展望2017:DL社群能否聯合開源出跨平臺、跨裝置的後端解決方案
後端上,隨著ARM、神經晶片的引入,我們迫切需要緊跟著硬體來完成繁重的程式設計。
後端是一個敏感詞,因為硬體可以拿來賣錢,所以更傾向於閉源。
除此之外,即便出現了開源的後端,在山寨和混戰之前是否能普及也是一個問題。
展望2017:來寫框架吧
VM的出現,帶來另一個值得思考的問題:現在是不是人人應該學寫框架了?
傳統框架編寫的困難在程式碼耦合度高,學習成本昂貴。
VM流框架分離了前後端之後,前端編寫難度很低,後端的則相對固定。
這樣一來,框架的程式設計層次更加分明,Keras地位似乎要危險了。
展望2017:更快迭代的框架,更多變的風格,更難的壟斷地位
相比於paper的迭代,框架的迭代似乎更快了一點。
餘凱老師前段時間發出了TensorFlow壟斷的擔憂,但我們可以很樂觀地看到:越來越多的使用者,在深入框架的底層。
TensorFlow並不是最好的框架,MXNet也不是,最好的框架是自己用的舒服的框架,最好是一行行自己敲出來的。
如果你已經積累的數個框架的使用經驗,是時候把它們無縫銜接在一起了。

相關推薦
[深度學習大講堂]從NNVM看2016年深度學習框架發展趨勢
本文為微信公眾號[深度學習大講堂]特約稿,轉載請註明出處 虛擬框架殺入 從發現問題到解決問題 半年前的這時候,暑假,我在SIAT MMLAB實習。 看著同事一會兒跑Torch,一會兒跑MXNet,一會兒跑Theano。 SIAT的伺服器一般是不給sudo許可權的,我看著同事掙扎在編譯這一坨框架的
2016年技術學習目標
與李兄的溝通總結 1 小公司。早期技術含量不高,主要是快。 2 大公司。要求技術紮實穩定。因為資料量大,所以技術一定要過硬,否則後果不堪。 3 方向。未來技術發展方向。大資料,服務化,架構。物聯網,智慧機器人。 4 語言。谷歌golang 和蘋果的swift 應該學習下。
2018年大數據的發展趨勢,學習大數據有什麽重要優勢?
獲取 數據 移動 優勢 操作 科技 谷歌 spa 規模 2018年已經過去一半多,大數據分析如今已不能再稱之為新技術,大多數移動應用程序開發人員已經明白,他們需要挖掘他們的數據來積極獲取日常的見解。許多大型應用程序開發企業已經意識到,要在市場上不斷地發展和更新,必須采用大
從CVPR2013看計算機視覺研究的三個趨勢
申明:本文非筆者原創,原文轉載自:http://www.bfcat.com/index.php/2013/07/compute-visioni-trends/ tombone‘s blog 最近一直在update關於CVPR2013的感受,今天,他在部
大資料學習:帶你從多個維度來分析大資料發展趨勢
如今“大資料”已不再是單純描述資料特徵的詞彙,而是一個多學科交融的熱點研究領域,其背後有著複雜和深刻的新理念。 今天我們帶大家從“技術、工程、科學和應用”這四個維度分析大資料的研究現狀與挑戰,探討未來研究的側重點和發展趨勢。 推薦下小編的大資料學習群;前面是251中間是956後面是502,不管
未來5年移動支付的發展趨勢
如今不得不說移動支付是無孔不入,遍佈在人們生活的每個角落,從大型商超、影院,到餐廳、咖啡館、甜品店、街頭特色小店、自動販售機,再到計程車、火車、飛機等各類交通工具,衣食住行、吃喝玩樂,但凡要用錢消費的地方,都能移動支付營銷的身影,一部手機就足以。 移動支付市場逐漸成熟 近日,支付寶在微信支付之後也宣佈
2017年中國大資料發展趨勢和展望解讀(上)
導讀:2015年8月,國務院印發《促進大資料發展行動綱要》,首次明確提出建設資料強國;2015年10月,黨的十八屆五中全會提出“實施國家大資料戰略”,將大資料上升為國家戰略。其後,國家政府部門、科技研究院、網際網路大企業、傳統工業企業等不斷髮布戰略藍皮書,對未來進行規劃
2019年棋牌遊戲行業發展趨勢預測 95後成主要玩家
2019年到來,回首2018年棋牌遊戲行業,可謂是百花齊放,萬家爭鳴,房卡模式獨領風騷,金幣模式稍遜一籌,數個棋牌遊戲開發商崛地而起,競爭分外激烈。小編今天根據2018年的棋牌遊戲行業發展情況,給大家預測下今年2019年棋牌行業發展趨勢,供大家參考。 一,90後成主要玩家,移動端需求旺盛
淺談近幾年移動機器人的發展趨勢
題注:聯匯智造專注於應用人工智慧技術的移動機器人的研發,掌握了核心演算法及機器人應用技術,聯匯開發的移動機器人-行動者MOVER憑藉領先的演算法技術,走在了科技的前沿,解決了工業智慧化、柔性化生產的需求。關於移動機器人的發展歷程,聯匯智造根據多年的研究成果及經
2017年中國大資料發展趨勢和展望解讀(下)
(六)工業大資料為實現製造強國提供強大支撐 隨著工業大資料創新應用的不斷深化發展,我國將迎來以資料驅動的全生命週期以及全產業鏈的優化升級。工業大資料在自身基礎設施建設以及同其他產業平臺的融合將更加完善,必將探索出製造業網路化、數字化和智慧化發展的新模式。 *工業大資料是指在工業領域中,圍繞典型智慧製造
廣州天象網絡技術有限公司未來幾年互聯網行業發展趨勢你怎麽看待的
帶來 餐飲 天都 外賣o2o 福利 b2c 今日頭條 綜合 外賣 現階段互聯網依然是處於蓬勃發展,隨著政府號召發展“互聯網 +”,不僅深受各領域的企業追捧,互聯網可以說是成為所有產 業和企業的前進方向。而且“互聯網+”熱潮出現了2個非常明顯 的特點:第一,全國的互聯網市場細
論文2016年《6D位姿估計的多視點自監督深度學習》 在亞馬遜挑選的挑戰——學習筆記二
第一部分:論文的學習的全部理解 關鍵字:多視覺的物體6D姿態估計、自監督訓練網路、自動標記採集、標記資料 、ICP演算法 摘要:機器人倉庫自動化近年來引起了人們的極大興趣,也許最引人注目的是亞馬遜採摘挑戰賽(APC)。完全自主的倉庫取放系統需要強大的視野,可以在雜亂的環境,自我遮擋,感測
2010-2016年被引用次數最多的深度學習論文
我相信世上存在值得閱讀的經典的深度學習論文,不論它們的應用領域是什麼。比起推薦大家長長一大串論文,我更傾向於推薦大家一個某些深度學習領域的必讀論文精選合集。 精選合集標準 2016 : +30 引用 「+50」 2015 : +100
深度學習基礎--從傅立葉分析角度解讀深度學習的泛化能力
從傅立葉分析角度解讀深度學習的泛化能力 從論文《Training behavior of deep neural network in frequency domain》中可以得到以下結論: 頻率原則可以粗糙地表述成:DNN 在擬合目標函式的過程中,有從低頻到高頻的先後順序。
分享《深度學習與計算機視覺算法原理框架應用》《大數據架構詳解從數據獲取到深度學習》PDF數據集
書簽 部分 https log pdf 深入 -s 更多 實用 下載:https://pan.baidu.com/s/12-s95JrHek82tLRk3UQO_w 更多資料分享:http://blog.51cto.com/3215120 《深度學習與計算機視覺 算法原理
打臉!2018年深度學習發展速度被嚴重高估
打臉!2018年深度學習發展速度被嚴重高估 https://mp.weixin.qq.com/s/JaqEbgcJA0VCyL6Zt_xUgg 策劃編輯 | Debra 作者 | Carlos E. Perez 譯者 | Sa
從R-CNN到RFBNet,深度目標檢測5年縱覽,文章+程式碼讓你從入門到精通(轉)
mark一下,最早是從機器學習研究會上看到,收藏之後一直沒時間細讀。現開始閱讀並分享出來。最後感謝作者分享! 文章名 | Deep Learning for Generic Object Detection: A Survey 文章地址 | https://arxiv.org/abs/1
那些年深度學習所踩過的坑-第一坑
博主在學習簡單的深度學習的時候用的是mac電腦,正是因為用的是這個電腦,所以說在跑程式碼的時候遇到過很多坑,因此決定將那些年踩過的坑全部記錄下來。 由於看的論文主要是關於C3D卷積神經網路的,因此我準備將github上面的C3D的程式碼下載下來跑一下 經過整理之後,資料夾裡面的檔案如圖
在 2016 年學 JavaScript 是一種什麼樣的體驗?(React從入門到放棄)
作者:方應杭連結:https://zhuanlan.zhihu.com/p/22782487來源:知乎著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。注:原文是英文,本文是我翻譯的。有人把我翻譯的內容原文照抄,放到他自己的專欄,搞得有人問我是不是我抄襲了……請支援我的勞動成果,花了兩個小時
從Gartner資料看2016全球外部儲存和固態陣列市場格局
前兩天我在文章從IDC資料聊聊2016全年中國外部儲存市場格局裡分享了中國儲存市場的一些情況,今天,我們重點來聊聊全球市場,不過,我採用的是Gartner資料。 還是醜話說在前頭,我的分享僅供參考,對於我整理過程中可能帶來的錯誤,概不負責,O(∩_∩)O哈! 在Gartner的跟蹤資料裡,2016