
機器學習效能指標精確率、召回率、F1值、ROC、PRC與AUC
精確率、召回率、F1、AUC和ROC曲線都是評價模型好壞的指標,那麼它們之間有什麼不同,又有什麼聯絡呢。下面讓我們分別來看一下這幾個指標分別是什麼意思。
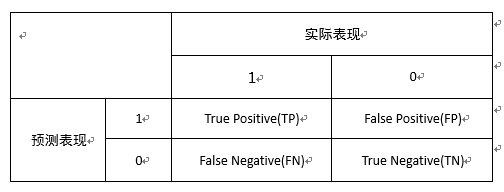
針對一個二分類問題,將例項分成正類(postive)或者負類(negative)。但是實際中分類時,會出現四種情況.
(1)若一個例項是正類並且被預測為正類,即為真正類(True Postive TP)
(2)若一個例項是正類,但是被預測成為負類,即為假負類(False Negative FN)
(3)若一個例項是負類,但是被預測成為正類,即為假正類(False Postive FP)
(4)若一個例項是負類,但是被預測成為負類,即為真負類(True Negative TN)
如下圖所示:
精確率(Precision)為TP/(TP+FP),即實際是正類並且被預測為正類的樣本佔所有預測為正類的比例,精確率更為關注將負樣本錯分為正樣本(FP)的情況。
召回率(Recall)為TP/(TP+FN),即實際是正類並且被預測為正類的樣本佔所有實際為正類樣本的比例,召回率更為關注將正樣本分類為負樣本(FN)的情況。
F1值是精確率和召回率的調和均值,即F1=2PR/(P+R) (P代表精確率,R代表召回率),相當於精確率和召回率的綜合評價指標。
有的時候,我們對recall 與 precision 賦予不同的權重,表示對分類模型的偏好:
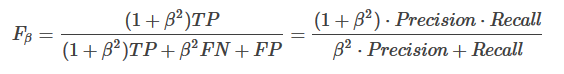
可以看到,當
β=1,那麼Fβ就退回到F
ROC曲線其實是多個混淆矩陣的結果組合,如果在上述模型中我們沒有定好閾值,而是將模型預測結果從高到低排序,將每個概率值依次作為閾值,那麼就有多個混淆矩陣。
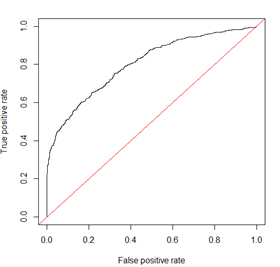
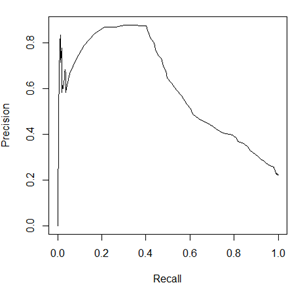 除此之外,在評價模型時還會用到KS(Kolmogorov-Smirnov)值,KS=max(TPR-FPR),即為TPR與FPR的差的最大值,KS值可以反映模型的最優區分效果,此時所取的閾值一般作為定義好壞使用者的最優閾值。
除此之外,在評價模型時還會用到KS(Kolmogorov-Smirnov)值,KS=max(TPR-FPR),即為TPR與FPR的差的最大值,KS值可以反映模型的最優區分效果,此時所取的閾值一般作為定義好壞使用者的最優閾值。TPR、FPR、Precision、Recall的定義來對比,TPR、Recall的分母為樣本中正樣本的個數,FPR的分母為樣本中負樣本的個數,樣本一旦確定分母即為定值,因此三個指標的變化隨分子增加單調遞增。但是Precision的分母為預測為正樣本的個數,會隨著閾值的變化而變化,因此Precision的變化受TP和FP的綜合影響,不單調,變化情況不可預測。 精確度的弊端在不均衡的樣本中體現的尤為明顯,比如有1000個樣本,其中10個負樣本,990個正樣本,那麼模型只要簡單的把所有的樣本都劃分為正樣本就可以獲得99%的正確率,但是這樣的劃分並沒有什麼意義。
相對來講ROC曲線會穩定很多,在正負樣本量都足夠的情況下,ROC曲線足夠反映模型的判斷能力。
因此,對於同一模型,PRC和ROC曲線都可以說明一定的問題,而且二者有一定的相關性,如果想評測模型效果,也可以把兩條曲線都畫出來綜合評價。
對於有監督的二分類問題,在正負樣本都足夠的情況下,可以直接用ROC曲線、AUC、KS評價模型效果。在確定閾值過程中,可以根據Precision、Recall或者F1來評價模型的分類效果。
對於多分類問題,可以對每一類分別計算Precision、Recall和F1,綜合作為模型評價指標。
參考:
相關推薦
機器學習效能指標精確率、召回率、F1值、ROC、PRC與AUC--周振洋
機器學習效能指標精確率、召回率、F1值、ROC、PRC與AUC 精確率、召回率、F1、AUC和ROC曲線都是評價模型好壞的指標,那麼它們之間有什麼不同,又有什麼聯絡呢。下面讓我們分別來看一下這幾個指標分別是什麼意思。 針對
機器學習效能指標精確率、召回率、F1值、ROC、PRC與AUC
精確率、召回率、F1、AUC和ROC曲線都是評價模型好壞的指標,那麼它們之間有什麼不同,又有什麼聯絡呢。下面讓我們分別來看一下這幾個指標分別是什麼意思。 針對一個二分類問題,將例項分成正類(postive)或者負類(negative)。但是實際中分類時,會出現四種情況
機器學習效能指標(ROC、AUC、)
混淆矩陣 TP(真正樣本數): 預測是正樣本(positive),預測正確(ture)的個數,即實際是正樣本預測成正樣本的樣本數 FN(假負樣本數) TN(真負樣本數) FP(假正樣本數) ROC 橫軸:FPR(負正樣本率)=FP/(FP+TN) 即,預測錯的原本負樣本佔總體
機器學習效能評估指標(精確率、召回率、ROC、AUC)
實際上非常簡單,精確率是針對我們預測結果而言的,它表示的是預測為正的樣本中有多少是對的。那麼預測為正就有兩種可能了,一種就是把正類預測為正類(TP),另一種就是把負類預測為正類(FP)。 P = TP/(TP+FP) 而召回
【機器學習】分類效能度量指標 : ROC曲線、AUC值、正確率、召回率、敏感度、特異度
在分類任務中,人們總是喜歡基於錯誤率來衡量分類器任務的成功程度。錯誤率指的是在所有測試樣例中錯分的樣例比例。實際上,這樣的度量錯誤掩蓋了樣例如何被分錯的事實。在機器學習中,有一個普遍適用的稱為混淆矩陣(confusion matrix)的工具,它可以幫助人們
機器學習之分類問題的評估指標2---準確率、精確率、召回率以及F1值
本節主要了解一下sklearn.metrics下計算準確率、精確率、召回率和F1值的函式以及對於多分類問題計算時的理解 1、sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weigh
機器學習效能評估指標---準確率(Accuracy), 精確率(Precision), 召回率(Recall)
分類 混淆矩陣1 True Positive(真正, TP):將正類預測為正類數.True Negative(真負 , TN):將負類預測為負類數.False Positive(假正, FP):將負類預測為正類數 →→ 誤報 (Type I
機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介
模型 可擴展性 決策樹 balance rman bsp 理解 多個 缺失值 數據挖掘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。 引言: 在機器學習、數據挖掘、推薦系統完成建模之後,需要對模型的
機器學習模型準確率,精確率,召回率,F-1指標及ROC曲線
01準確率,精確率,召回率,F-1指標及ROC曲線 假設原樣本有兩類,正樣本True和負樣本False 正樣本 -------------------------------True 負樣本 --------------------------------False 真 正樣本 True P
機器學習實踐(十五)—sklearn之分類演算法-邏輯迴歸、精確率、召回率、ROC、AUC
邏輯迴歸雖然名字中帶有迴歸兩字,但它實際是一個分類演算法。 一、邏輯迴歸的應用場景 廣告點選率 是否為垃圾郵件 是否患病 金融詐騙 虛假賬號 看到上面的例子,我們可以發現其中的特點,那就是都屬於兩個類別之間的判斷。 邏輯迴歸就是
機器學習算法中的評價指標(準確率、召回率、F值、ROC、AUC等)
html eight inf 曲線 mba cor 方法 指標 pan 參考鏈接:https://www.cnblogs.com/Zhi-Z/p/8728168.html 具體更詳細的可以查閱周誌華的西瓜書第二章,寫的非常詳細~ 一、機器學習性能評估指標 1.準確率(A
機器學習演算法中的評價指標(準確率、召回率、F值、ROC、AUC等)
參考連結:https://www.cnblogs.com/Zhi-Z/p/8728168.html 具體更詳細的可以查閱周志華的西瓜書第二章,寫的非常詳細~ 一、機器學習效能評估指標 1.準確率(Accurary) 準確率是我們最常見的評價指標,而且很容易理解,就是被分對的樣本
【深度學習-機器學習】分類度量指標 : 正確率、召回率、靈敏度、特異度,ROC曲線、AUC等
在分類任務中,人們總是喜歡基於錯誤率來衡量分類器任務的成功程度。錯誤率指的是在所有測試樣例中錯分的樣例比例。實際上,這樣的度量錯誤掩蓋了樣例如何被分錯的事實。在機器學習中,有一個普遍適用的稱為混淆矩陣(confusion matrix)的工具,它可以幫助人們更好地瞭解
機器學習 模型評估中的 精確率、召回率、F1、ROC、AUC
文章目錄 1 混淆矩陣 1.2 多分類的例子 2.2 二分類的例子 2.3 二分類真實數值計算 2 各類指標的優缺點 1 混淆矩陣 準確率對於分類器的效能分析來說,並不是一個很好地衡量指標,因為如果資料
【機器學習-西瓜書】二、效能度量:召回率;P-R曲線;F1值;ROC;AUC
關鍵詞:準確率(查準率,precision);召回率(查全率,recall);P-R曲線,平衡點(Break-Even Point, BEP);F1值,F值;ROC(Receiver Operating Characteristic,受試者工作特徵);AUC(A
機器學習之分類(Classification) 精確率、準確率、召回率
在機器學習中,模型評估涉及許多方法和名次,在此將其彙總一下,方便以後溫習。一 分類 (Classification):真假與正類負類a. 真正例(TP) 是指模型將正類別樣本正確地預測為正類別。b. 真負例(TN) 是指模型將負類別樣本正確地預測為負類別。c. 假正例
機器學習:評價分類結果(實現混淆矩陣、精準率、召回率)
test set 目的 mod 二分 參數 nbsp return try 一、實例 1)構造極度偏差的數據 import numpy as np from sklearn import datasets digits = datasets.load_digits
機器學習演算法中的準確率(Precision)、召回率(Recall)、F值(F-Measure)
資料探勘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。 在機器學習、資料探勘、推薦系統完成建模之後,需要對模型的效果做評價。 業內目前常常採用的評價指標有準確率(Precision)、召回率(Recall)、F值(F-
機器學習效能度量指標:ROC曲線、查準率、查全率、F1
錯誤率 在常見的具體機器學習演算法模型中,一般都使用錯誤率來優化loss function來保證模型達到最優。 \[錯誤率=\frac{分類錯誤的樣本}{樣本總數}\] \[error_rate=\frac{1}{m} \sum_{i=1}^{m} I(f(x_{i})\neq y_{i})\] 但是錯誤
機器學習--資料判斷依據 精確度、召回率、調和平均值F1值
精準度(precision) precision = 正確預測的個數(TP) / 被預測正確的個數(TP+FP) 召回率(recall) recall = 正確預測的個數(TP)/ 預測個數(FN) 調和平均值 F1-Socre f1 = 2*精準度 * 召回率 /(精度