
Spark2.0.1偽分散式安裝配置
前言.Spark簡介和hadoop的區別
Spark 是一種與 Hadoop 相似的開源叢集計算環境,但是兩者之間還存在一些不同之處,Spark 啟用了記憶體分佈資料集,除了能夠提供互動式查詢外,它還可以優化迭代工作負載。
1.架構不同。
Hadoop是對大資料集進行分散式計算的標準工具。提供了包括工具和技巧在內的豐富的生態系統,允許使用相對便宜的商業硬體叢集進行超級計算機級別的計算。
Spark使用函數語言程式設計正規化擴充套件了MapReduce程式設計模型以支援更多計算型別,可以涵蓋廣泛的工作流。且需要一個第三方的分散式儲存系統作為依賴。
2.處理物件不同
Spark處理資料的方式不一樣,會比MapReduce快上很多。MapReduce是分步對資料進行處理的: 從叢集中讀取資料,進行一次處理,將結果寫到叢集,從叢集中讀取更新後的資料,進行下一次的處理,將結果寫到叢集,反觀Spark,它會在記憶體中以接近“實時”的時間完成所有的資料分析:從叢集中讀取資料,完成所有必須的分析處理,將結果寫回叢集.所以Hadoop適合處理靜態資料,而Spark適合對流資料進行分析。
3.速度
Spark基於記憶體:Spark使用記憶體快取來提升效能,因此進行互動式分析也足夠快速(就如同使用Python直譯器,與叢集進行互動一樣)。快取同時提升了迭代演算法的效能,這使得Spark非常適合資料理論任務,特別是機器學習。
Hadoop基於磁碟:MapReduce要求每隔步驟之間的資料要序列化到磁碟,這意味著MapReduce作業的I/O成本很高,導致互動分析和迭代演算法(iterative algorithms)開銷很大。而事實是,幾乎所有的最優化和機器學習都是迭代的。
4.災難恢復
Hadoop將每次處理後的資料都寫入到磁碟上,所以其天生就能很有彈性的對系統錯誤進行處理。
Spark的資料物件儲存在分佈於資料叢集中的叫做彈性分散式資料集(RDD: Resilient Distributed Dataset)中。這些資料物件既可以放在記憶體,也可以放在磁碟,所以RDD同樣也可以提供完成的災難恢復功能。
一.環境準備
jdk 1.8.0
hadoop2.7.2 偽分散式部署
scala 2.12.1 支援spark2.0.1及以上版本
spark2.0.1
二.Spark安裝模式(本文偽分散式)
spark有以下幾種安裝模式,每種安裝模式都有自己不同的優點和長處。
local(本地模式):
常用於本地開發測試,本地還分為local單執行緒和local-cluster多執行緒;
standalone(叢集模式):
典型的Mater/slave模式,Master可能有單點故障的;Spark支援ZooKeeper來實現 HA。
on yarn(叢集模式):
執行在 yarn 資源管理器框架之上,由 yarn 負責資源管理,Spark 負責任務排程和計算。
on mesos(叢集模式):
執行在 mesos 資源管理器框架之上,由 mesos 負責資源管理,Spark 負責任務排程和計算。
on cloud(叢集模式):
比如 AWS 的 EC2,使用這個模式能很方便的訪問 Amazon的 S3;Spark 支援多種分散式儲存系統:HDFS 和 S3。
目前Apache Spark支援三種分散式部署方式,分別是standalone、Spark on mesos和 spark on YARN,其中,第一種類似於MapReduce 1.0所採用的模式,內部實現了容錯性和資源管理,後兩種則是未來發展的趨勢,部分容錯性和資源管理交由統一的資源管理系統完成:讓Spark執行在一個通用的資源管理系統之上,這樣可以與其他計算框架,比如MapReduce,公用一個叢集資源,最大的好處是降低運維成本和提高資源利用率(資源按需分配)。
三.安裝scala
1.上傳scala包,解壓縮
2.配置環境變數SCALA_HOME
3.source /etc/profile使得生效
4.驗證scala安裝情況
scala -version
及上scala 安裝完成
[注意]:叢集環境全部分屬於santiago使用者如下圖
四.偽分散式Spark安裝部署
1 解壓spark安裝包,並配置SPARK_HOME環境變數,最後用 source使之生效。
2 更改配置 在/usr/local/spark-2.0.1/conf 下
(1)cp slaves.template slaves
vim hdp(主機名)
(2)cp spark-env.sh.template spark-env.sh
vim spark-env.sh
進行以下配置
export JAVA_HOME=/usr/local/jdk1.8.0
export SCALA_HOME=/usr/local/scala-2.12.1
export SPARK_WORKER_MEMORY=1G
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.137.133
3 啟動spark
(1)先啟動hadoop 環境
/usr/local/hadoop/sbin# start-all.sh
(2)啟動spark環境
/usr/local/spark-2.0.1/sbin# ./start-all.sh
[注] 如果使用start-all.sh時候會重複啟動hadoop配置,需要./在當前工作目錄下執行指令碼檔案。
jps 觀察程序 多出 worker 和 mater 兩個程序
五.Spark測試
1.在HDFS上建立目錄
hadoop fs -mkdir -p /usr/hadoop
hadoop fs -ls /usr/ 可以檢視
hadoop fs -mkdir -p /usr/data/input 建立資料夾input
將本地目錄傳送到HDFS上
hadoop fs -put /home/santiago/data/spark/spark_test.txt /usr/data/input
2測試spark

觀察job網頁
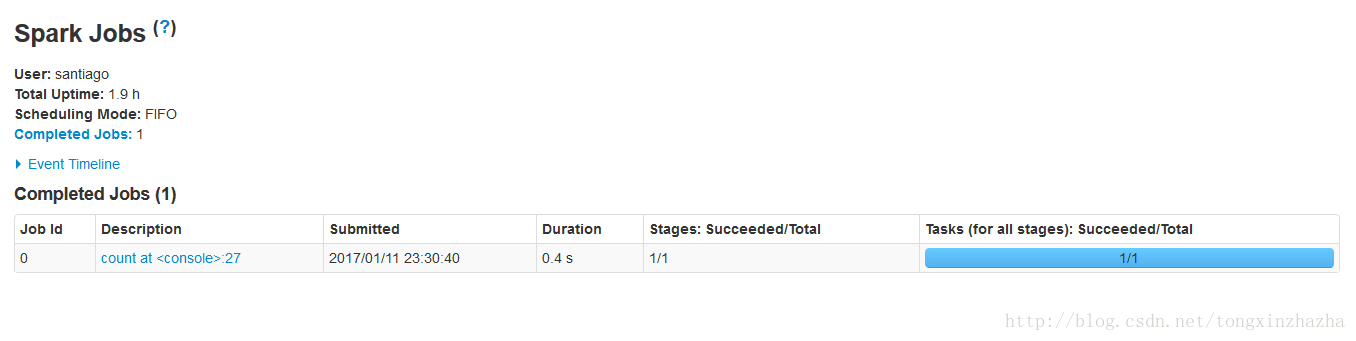
配置成功
[注意]
1. spark處理HDFS的檔案
2.檢視spark的web控制頁面 spark叢集的web埠:8080
http://192.168.137.133:8080/
3.檢視sparl-shell web介面 spark-job監控埠:4040
http://192.168.137.133:4040/jobs/
相關推薦
Spark2.0.1偽分散式安裝配置
前言.Spark簡介和hadoop的區別 Spark 是一種與 Hadoop 相似的開源叢集計算環境,但是兩者之間還存在一些不同之處,Spark 啟用了記憶體分佈資料集,除了能夠提供互動式查詢外,它還可以優化迭代工作負載。 1.架構不同。 Hadoop是對
最新版hadoop2.7.1單機版與偽分散式安裝配置
前提:熟悉Linux系統操作,掌握基本的Linux命令 注意:安裝路徑中不能有任何中文字元和空格! 我安裝的是ubuntu14,使用者名稱是ubuntu,機器名是ubuntu,hadoop的版本是hadoop-2.7.1.tar.gz 一、在Ubuntu下建立hadoop
CentOS7環境下偽分散式安裝配置hadoop
(一) 設定靜態IP地址 cd /etc/sysconfig/network-scripts vim ifcfg-ens33 修改IPADDR,NETMASK,GATEWAY為對應的值 修改BOOTPROTO為none 儲存並退出 重啟網絡卡 servi
Hadoop 2.7 偽分散式安裝配置 Error: JAVA_HOME is not set and could not be found.
問題: 如果你明明安裝配置了 JAVA_HOME 卻還是報錯 如果遇到 Error: JAVA_HOME is not set and could not be found. 的錯誤,而你明
Storm偽分散式安裝配置
storm安裝配置前的準備工作:1.安裝Zookeeper。 2.上傳apache-storm-1.0.3.tar.gz安裝包到linux系統目錄下,我的是/tools(WinScp上傳)一
HBase單機/偽分散式安裝/配置筆記
一、單機模式安裝 在官網下載hbase 解壓到任一目錄下 修改hbase配置檔案 修改conf目錄下hbase-env.sh:設定JAVA_HOME環境變數 修改conf目錄下hbase-
[Hadoop]Hadoop+HBase 偽分散式安裝配置
(一)hadoop偽分散式的配置: 這個也可以參考《hadoop權威指南》上面寫的很全面,這裡再說一遍: 我的機器配置環境: OS:Ubuntu10.10 ,hadoop版本:hadoop-0.20.2(下載網址: http://apache.etoak.com//
hadoop2.6.0-cdh5.7.1偽分散式編譯安裝
環境相關: OS:CentOS release 6.9 IP:192.168.1.10 MEM:10G(推薦4G以上) DISK:50G 1. 主機克隆,基礎環境部署 參照《CentOS6實驗機模板搭建部署》 克隆一臺實驗機,調整記憶體為10G,並
1.7分散式工具配置及安裝(僅供學習Xshell,VMware)
前言 最近因為換工作以及其他的一些瑣事,耽誤了更博時間,再加上分散式的這幾個軟體之前沒擼過....這學習這幾個工具上也花了點時間 本篇部落格為後續分散式的學習提供基礎的安裝和配置。 首先,系統為CentOS。 因為本人是筆記本,沒有屬於自己的伺服器,所以就需要虛擬機器來代勞了。 然後就是遠端訪問的X
PCL-1.8.0 All In One安裝配置
轉自http://blog.csdn.net/u014283958/ 因為要做三維重建,所以想用三維點雲處理庫Point Cloud Library(PCL),找了幾篇博文按照要求裝了一下午的依賴庫,後來發現已經出了PCL 1.8.0的a
Hadoop 3.1.1偽分散式模式安裝
Hadoop 3.1.1偽分散式模式安裝 更多資源 github: https://github.com/opensourceteams/hadoop-java-maven-3.1.1 視訊 Hadoop 3.1.1偽分散式模式安裝(bilibili視訊) : htt
Linux mint偽分散式安裝hadoop3.0.0
首先安裝jdk, 我這裡使用的是linux mint,自帶圖形化介面,下載好linux版的jdk8-161後,放到/development/目錄下,進行解壓 # 將jdk8u_161改名成jdk ~ mv jdk8u_161 jdk # 解壓jdk壓縮包
基於hadoop1.2.1的hive偽分散式安裝
主要參考的這篇blog http://www.kankanews.com/ICkengine/archives/72851.shtml 使用的hive版本是hive-0.11.0-bin.tar.gz 作業系統是 ubuntu12.04 64位 1、下載
hadoop2.2.0上spark偽分散式安裝
1. 從官網上下下載合適的版本: http://spark.apache.org/downloads.html 筆者下載的是for hadoop2.2版本的spark0.9.2 2. 解壓,配置環境: sudo gedit /etc/profile 新增SPARK_HOM
idea(1):安裝配置
idea idea安裝配置 二、配置2.1、激活Help --> Register...2.2、皮膚及字體File-->Settings...-->2.2.1、皮膚 2.2.2、字體 2.3、git在https://github.com/中註冊一個賬號IDEA還需要Git客戶端,官方
ubuntu 16.04.1 LTS postgresql安裝配置
ket ons wget 5.6 int cst multi 啟動 oca postgresql安裝--------------------二進制安裝:wget https://get.enterprisedb.com/postgresql/postgresql-9.5.6
ubuntu 16.04.1 LTS redis安裝配置
star ins redis-cli -s download root per edi down 編譯安裝:apt-get updateapt-get install build-essential tclwget http://download.redis.io/redi
redis4.0.1集群安裝部署
com cal slots server tcl copy trunc 節點 append 安裝環境 序號 項目 值 1 OS版本 Red Hat Enterprise Linux Server release 7.1 (Maipo)
spark2.0.1源碼編譯
ima ive 配置 pan 編譯時間 jdk 內容 進入 dha 一、編譯源碼步驟演示詳解 . 編譯spark環境要求 1、必須在linux系統下編譯(以centos6.4為例) 2、編譯使用的JDK版本必須是1.6以上(以JDK1.8為例) 3、編譯需要使用Ma
MySQL Community Server 8.0.11下載與安裝配置
ucc stop 文件復制 代碼 AMF files tps 需要 fault 一、下載 1、選擇合適的安裝包,我在這裏下載的是目前最新的安裝包,8.0.11,而且我選擇下載的是解壓版的,安裝版的話,安裝會比較麻煩。 MySQL Community Server下載鏈接:h