
hadoop2.2.0上spark偽分散式安裝
阿新 • • 發佈:2019-02-15
1. 從官網上下下載合適的版本:
http://spark.apache.org/downloads.html
筆者下載的是for hadoop2.2版本的spark0.9.2
2. 解壓,配置環境:
sudo gedit /etc/profile新增SPARK_HOME和更新PATH;
3. 安裝Scala
新增Scala_HOME和更新PATH
4. 配置Spark
進入SPARK_HOME/conf目錄,複製一份spark-env.sh.template並更改檔名為spark-env.sh
開啟編輯:
export SCALA_HOME=/home/hadoop/ha/scala-2.10.3 export JAVA_HOME=/usr/lib/jdk/jdk1.7.0_71 export SPARK_MASTER=localhost export SPARK_LOCAL_IP=localhost export HADOOP_HOME=/home/hadoop/ha/hadoop-2.2.0 export SPARK_HOME=/home/hadoop/ha/spark-0.9.2-bin-hadoop2 export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
5. 讓環境生效:
source /etc/profile6. 啟動spark
進入SPARK_HOME/sbin目錄,執行命令:
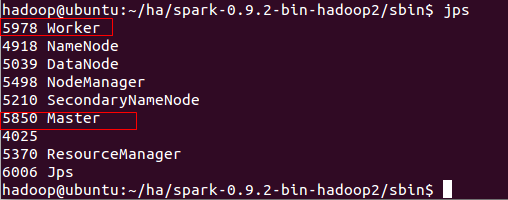
start-all.sh7. 輸入命令jps檢視是否啟動成功:
可以看到有一個Master跟Worker程序 說明啟動成功
可以通過http://localhost:8080/檢視spark叢集狀況
8. 通過瀏覽器訪問http://localhost:8080/ 檢視spark叢集狀況
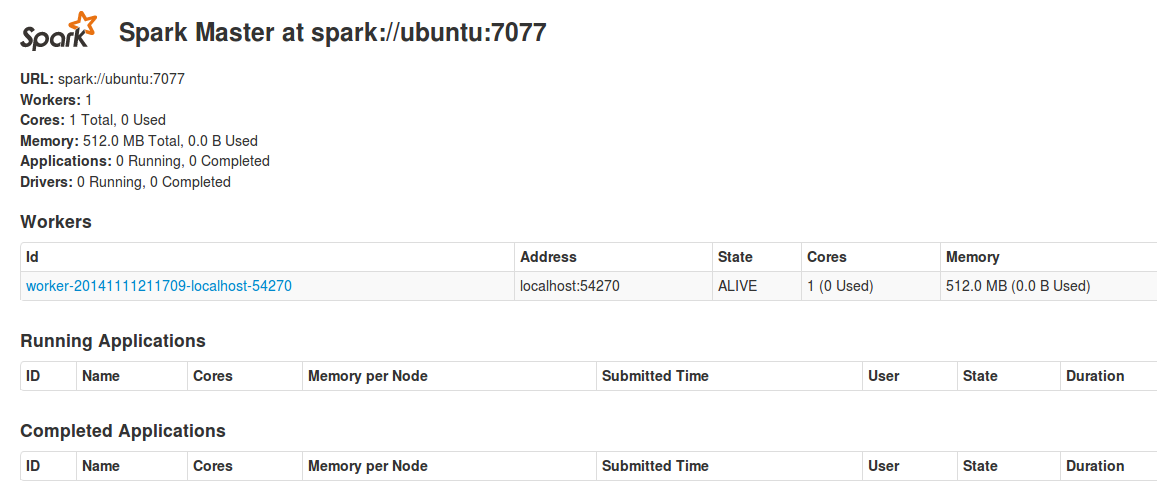
OK!