
TensorFlow基礎4:四種類型資料的讀取流程及API講解和程式碼實現
在上篇文章中梳理了資料讀取的三種方式,但是在實際專案當中,由於資料量一般會比較大,所以更多的會使用第三種方法(即直接從檔案中讀取)。但是對於不同的檔案型別,需要不同的檔案處理API,有時候比較容易弄混淆,接下來就來梳理一下。
一.檔案讀取流程
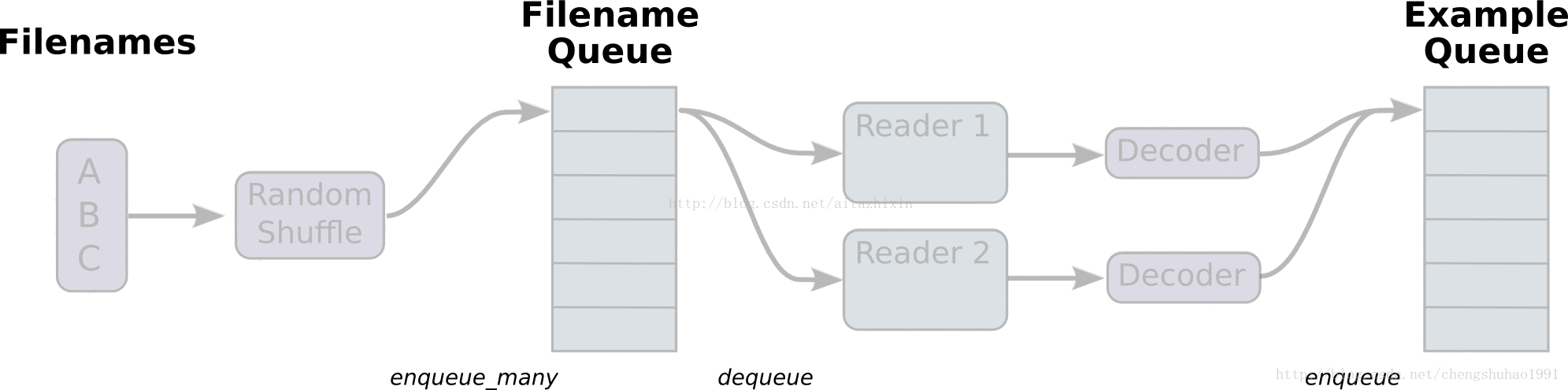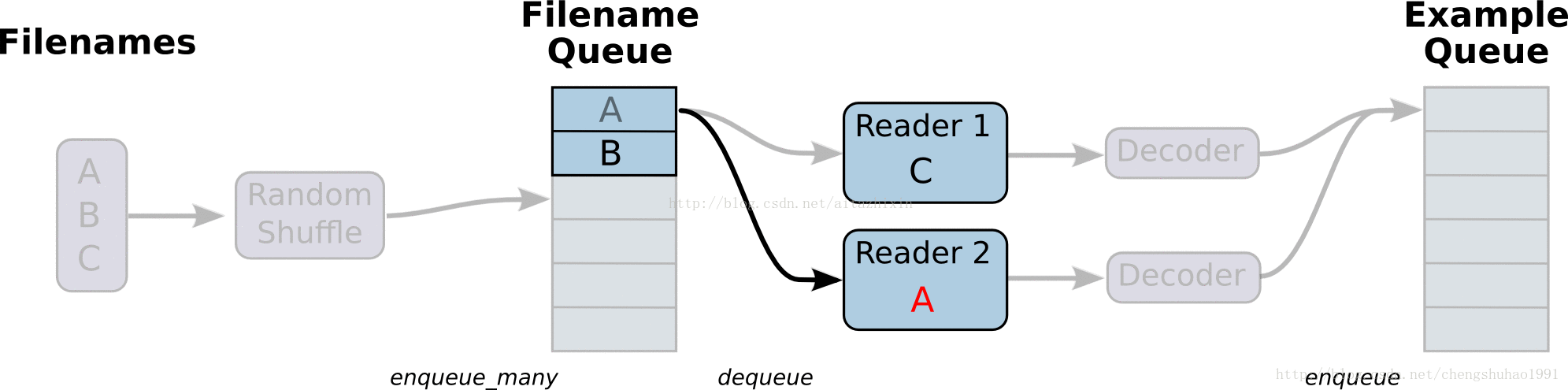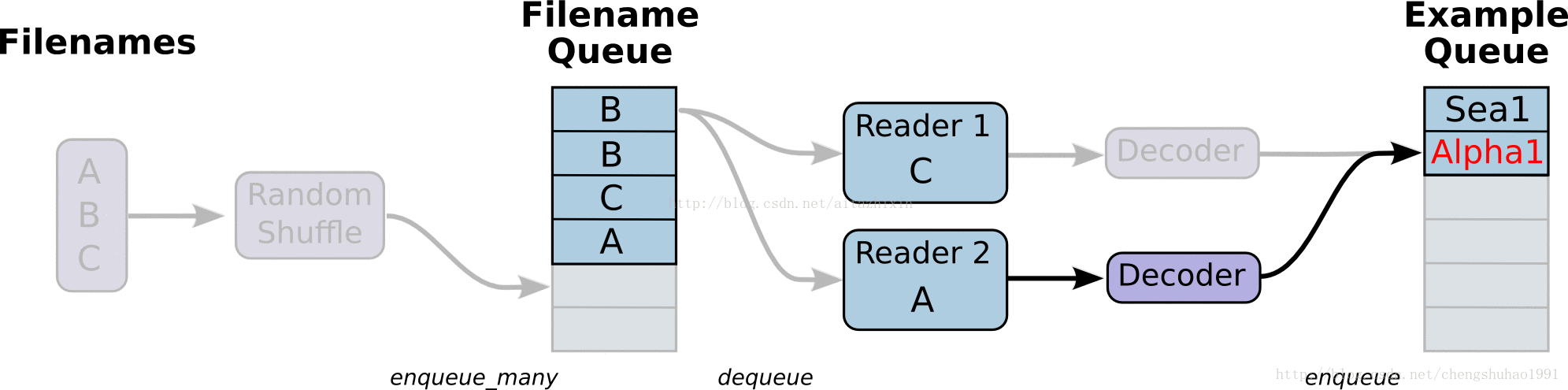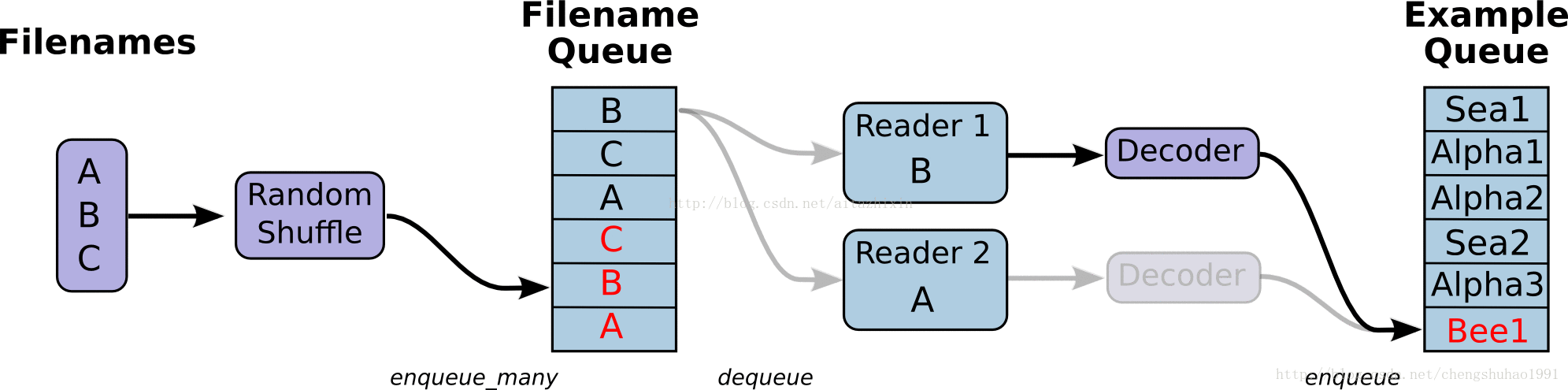
如上圖所示,展示了檔案讀取的大致流程。
最左邊的A、B、C是儲存於磁碟中檔案,經過打亂檔案之後(這裡是預設的亂序讀取,只是檔案的順序亂,但是檔案內容不受影響),進入到檔案佇列中(Filename Queue)。檔案隊列當中的檔案經過閱讀器(Reader)處理,儲存到記憶體當中。接下來對檔案進行解碼(Decode),解碼之後進入樣本隊列當中進行批處理,此時經過批處理之後就可以用於模型訓練了。
現在舉例,對於讀取CSV檔案,大致要經歷一下幾步:
1. 找到檔案,並構造檔案的列表(一階張量)
2. 構造檔案佇列
3. 讀取檔案內容
4. 解碼CSV並讀取內容
5. 開啟會話執行,得出訓練結果
二.檔案讀取的API
1.檔案佇列構造
tf.train.string_inout_producer(string_tensor,num_epochs,shuffle=True)
- 將輸出字串(例如檔名)輸入到管道佇列
string_tensor:含有檔名的一階張量,需要指定檔案路徑num_epochs:將全部資料迴圈的次數return:具有輸出字串的佇列
2.檔案閱讀器
此時需要根據檔案的格式,選擇對應的檔案閱讀器
(1) 文字檔案:tf.TextLineReader()
- 讀取文字檔案,逗號分隔值(CSV)格式,預設按行讀取
- return:讀取器例項
(2)二進位制檔案:tf.FixedLengthRecordReader(record_bytes)
- 讀取每個記錄是固定數量位元組的二進位制檔案
- record_bytes:整型,指定每次讀取的位元組數
- return:讀取器例項
(3)圖片檔案:tf.WholeReader()
- 將檔案的全部內容作為值輸出,即一次讀取一整個檔案
- return:讀取器例項
(4)TFRecords檔案:
tf.TFRecordReader()
- 讀取 TFRecords檔案
- return:讀取器例項
注:這幾種檔案格式都有一個共同的讀取方法:read(file_queue)
- 從佇列中指定內容數量
- file_name : 檔案佇列
- ruturn : 返回一個Tensor元組(key,value)
- key : 檔名
- value : 每次讀取的值(一行文字、一張圖片或指定位元組的值)
3.檔案內容解碼器
由於從檔案中讀取的是字串,需要函式去解析這些字串,最後變換成張量
(1)CSV檔案:
tf.decode_csv(records,record_defaults=None,field_delim=None,name=None)
- 將CSV檔案轉換成張量,需要
tf.TextLineReader()搭配使用 - records : tensor型字串,每個字串是CSV中的記錄行(即value值)
- record_defaults : 此引數決定了所得張量的型別,並設定一個值,如果在輸入字串中缺少則使用預設值,如[[1],[1]] 或者[[“None”],[“None”]]
- field_dim : 預設分隔符“ ,”
(2)二進位制檔案:
tf.decode_raw(bytes,out_type,little_endian=None,name=None)
- 將位元組轉換為一個數字向量表示,位元組為以字串型別的張量
- 與函式tf.FixedLengthRecordReader搭配使用
- 將二進位制轉換為uint8格式
(3)影象檔案:
1)
tf.image.decode_jpeg(contens)- 將JPEG編碼的影象解碼為uint8張量
- return : uint8張量,3-D形狀[height,width,channels]
2)
tf.image.decode_png(contents)- 將PNG編碼的影象解碼為uint8或者uint16編碼
- return : 張量型別,3-D形狀[height,width,channels]
(4)TFRecords檔案:
TFRecords檔案是TensorFlow中的統一格式,它的儲存和讀取方式較為複雜,我會在下篇文章中單獨來梳理這部分的內容。
4.批處理資料
對資料進行批處理需要在會話開啟之前進行
(1)tf.train.batch(tensors,batch_size,num_threads=1,capacity=32,name=None)
- 讀取指定大小(個數)的張量
- tensor : 包含張量的列表
- batch_size : 從佇列中讀取的批處理資料大小
- num_threads : 進入佇列的執行緒數
- capacity : 整數,批處理佇列中元素的最大數量
- teturn : tensors
(2)tf.train.shuffle_batch(tensors,batch_size,capacity,min_after_dequeue,num_threads=1,capacity=32,name=None)
- 亂序讀取指定大小(數量)的張量
- min_after_dequeue : 留下佇列裡的張量個數,能夠保持隨機打亂
三.示例程式碼
1.CSV檔案讀取案例
def csvread(filelist):
"""
CSV檔案讀取
:param filelist: 檔案的列表(1階張量)
:return:None
"""
#2.構造檔案的佇列
file_queue = tf.train.string_input_producer(filelist)
#3.讀取檔案內容tf.decode_csv()
#構造閱讀器
reader = tf.TextLineReader()
#讀佇列檔案內容,一行
key,value = reader.read(file_queue)
#4、解碼csv檔案
#指定每一行格式的預設值,型別,[[1],[2.0],[1]]
records = [["None"],["None"]]
example,label = tf.decode_csv(value,record_defaults=records)
#批處理讀取資料
example_batch,label_batch = tf.train.batch([example,label],batch_size=20,num_threads=1,capacity=100)
#5、會話執行結果
with tf.Session() as sess:
#開啟執行緒協調器
coord = tf.train.Coordinator()
#建立子執行緒去進行操作,返回執行緒列表
threads = tf.train.start_queue_runners(sess,coord = coord)
#列印
print(sess.run([example_batch,label_batch]))
#回收
coord.request_stop() #強制請求執行緒停止
coord.join(threads) #等待執行緒終止回收
return None
if __name__ == '__main__':
#列出檔案目錄,構造路徑+檔名的列表,"A.csv"...
# os.listdir() 方法用於返回指定的資料夾包含的檔案或資料夾的名字的列表
filename = os.listdir('./data/csvdata')
#加上路徑
file_list = [os.path.join('./data/csvdata', file) for file in filename]
csvread(file_list)2.圖片檔案讀取案例
./data/dog檔案中儲存了100張 *.jpg格式的狗的圖片
def picread(file_list):
"""
讀取狗圖片並轉換成張量
:param file_list:
:return:
"""
#1、構造檔案的佇列
file_queue = tf.train.string_input_producer(file_list)
#2、生成圖片讀取器,讀取佇列內容
reader = tf.WholeFileReader() #返回讀取器例項
key ,value = reader.read(file_queue)
print(key,value)
#3.進行圖片的解碼
image = tf.image.decode_jpeg(value)
print(image)
#4.處理圖片的大小
image_resize = tf.image.resize_images(image,[256,256])
print(image_resize)
#設定靜態形狀 ,動態形狀也可以
image_resize.set_shape([256,256,3])
print(image_resize)
#5.進行批處理 #此處image_siez必須指定形狀,而且要為列表
image_batch = tf.train.batch([image_resize],batch_size=100,num_threads=1,capacity=100)
print(image_batch)
return image_batch
if __name__ == '__main__':
# 找到檔案路徑,名字,構造路徑+檔名的列表,"A.csv"...
# os.listdir() 方法用於返回指定的資料夾包含的檔案或資料夾的名字的列表
filename = os.listdir('./data/dog')
#加上路徑
file_list = [os.path.join('./data/dog', file) for file in filename]
image_batch = picread(file_list)
with tf.Session() as sess:
#定義執行緒協調器
coord = tf.train.Coordinator()
#開啟執行緒
threads = tf.train.start_queue_runners(sess,coord=coord)
print(sess.run(image_batch))
#回收執行緒
coord.request_stop()
coord.join(threads)3.二進位制檔案讀取案例
此案例中資料是使用的下載好的二進位制的cifar10資料
#讀取二進位制轉換檔案
class CifarRead(object):
"""
讀取二進位制檔案轉換成張量,寫進TFRecords,同時讀取TFRcords
"""
def __init__(self,file_list):
"""
初始化圖片引數
:param file_list:圖片的路徑名稱列表
"""
#檔案列表
self.file_list = file_list
#圖片大小,二進位制檔案位元組數
self.height = 32
self.width = 32
self.channel = 3
self.label_bytes = 1
self.image_bytes = self.height * self.width * self.channel
self.bytes = self.label_bytes + self.image_bytes
def read_and_decode(self):
"""
解析二進位制檔案到張量
:return: 批處理的image,label張量
"""
#1.構造檔案佇列
file_queue = tf.train.string_input_producer(self.file_list)
#2.閱讀器讀取內容
reader = tf.FixedLengthRecordReader(self.bytes)
key ,value = reader.read(file_queue) #key為檔名,value為元組
print(value)
#3.進行解碼,處理格式
label_image = tf.decode_raw(value,tf.uint8)
print(label_image)
#處理格式,image,label
#進行切片處理,標籤值
#tf.cast()函式是轉換資料格式,此處是將label二進位制資料轉換成int32格式
label = tf.cast(tf.slice(label_image,[0],[self.label_bytes]),tf.int32)
#處理圖片資料
image = tf.slice(label_image,[self.label_bytes],[self.image_bytes])
print(image)
#處理圖片的形狀,提供給批處理
#因為image的形狀已經固定,此處形狀用動態形狀來改變
image_tensor = tf.reshape(image,[self.height,self.width,self.channel])
print(image_tensor)
#批處理圖片資料
image_batch,label_batch = tf.train.batch([image_tensor,label],batch_size=10,num_threads=1,capacity=10)
return image_batch,label_batch
if __name__ == '__main__':
# 找到檔案路徑,名字,構造路徑+檔名的列表,"A.csv"...
# os.listdir() 方法用於返回指定的資料夾包含的檔案或資料夾的名字的列表
filename = os.listdir('./data/cifar10/cifar-10-batches-bin/')
#加上路徑
file_list = [os.path.join('./data/cifar10/cifar-10-batches-bin/', file) for file in filename if file[-3:] == "bin"]
#初始化引數
cr = CifarRead(file_list)
image_batch,label_batch = cr.read_and_decode()
with tf.Session() as sess:
#執行緒協調器
coord = tf.train.Coordinator()
#開啟執行緒
threads = tf.train.start_queue_runners(sess,coord=coord)
print(sess.run([image_batch,label_batch]))
#回收執行緒
coord.request_stop()
coord.join(threads)
TFRecords檔案是TensorFlow中的統一格式,它的儲存和讀取方式較上面三種格式要稍微複雜一些,我會在下篇文章中單獨來梳理這部分的內容。
相關推薦
TensorFlow基礎4:四種類型資料的讀取流程及API講解和程式碼實現
在上篇文章中梳理了資料讀取的三種方式,但是在實際專案當中,由於資料量一般會比較大,所以更多的會使用第三種方法(即直接從檔案中讀取)。但是對於不同的檔案型別,需要不同的檔案處理API,有時候比較容易弄混淆,接下來就來梳理一下。 一.檔案讀取流程 如上圖
ml課程:最大熵與EM演算法及應用(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹最大熵模型與EM演算法相關內容及相關程式碼案例。 關於熵之前的文章中已經學習過,具體可以檢視:ml課程:決策樹、隨機森林、GBDT、XGBoost相關(含程式碼實現),補充一些 基本概念: 資訊量:資訊的度量,即
Postman的Post請求方式的四種類型的資料
1. form-data 就是http請求中的multipart/form-data,它會將表單的資料處理為一條訊息,以標籤為單元,用分隔符分開。既可以上傳鍵值對,也可以上傳檔案。當上傳的欄位是檔案時,會有content-type來說明檔案型別;con
TensorFlow基礎3:資料讀取的三種方式
‘在講述在TensorFlow上的資料讀取方式之前,有必要了解一下TensorFlow的系統架構,如下圖所示: TensorFlow的系統架構分為兩個部分: 前端系統:提供程式設計模型,負責構造計算圖; 後端系統:提供執行時環境,負責執行計算圖。
sensor輸出的四種類型:YUV,RGB,RAW RGB,JPEG。
簡單來說, YUV: luma (Y) + chroma (UV) 格式, 一般情況下sensor支援YUV422格式,即資料格式是按Y-U-Y-V次序輸出的 RGB: 傳統的紅綠藍格式,比如RGB565,其16-bit資料格式為5-bit R + 6-bit G + 5-bit B。G多一位,原因是人眼對
[c++基礎] 四種類型轉換和隱式型別轉換
static_cast<type-id >( expression ) 用於數值型別之間的轉換,也可以用於指標之間的轉換,編譯時已經確定好,效率高,但須要自己保證其安全性。 (1)用於數值之間的轉化, 可以在相關指標在void* 之間轉換 (2)在
php表單提交 圖片、音樂、視頻、文字,四種類型共同提交到數據庫
class 文件 loaded 頁面 ins 需要 ech video 文件是否存在 這個問題一直困擾了我好幾天,終於在今天讓我給解決了,難以掩飾的激動。 其實在之前沒有接觸到這種問題,只是表單提交數據而已,再就是圖片,四種類型同時提交還真是沒遇到過,做了一個系統,其中有
SQL語言的四種類型和ORACLE運算符
字段 oracle not 我們 邏輯運算符 point 從數據 更新 size sql語句四種類型: 數據定義語言(DDL) 數據操作語言(DML) 數據控制語言(DCL) 事務控制語言(TCL) Data Definition Language(DDL) DDL使
在CSS3中,可以利用transform功能來實現文字或圖像的旋轉、縮放、傾斜、移動這四種類型的變形處理
for skew 文字 values alt 實例 垂直 -o 移動 CSS3中的變形處理(transform)屬 transform的功能分類 1.旋轉 transform:rotate(45deg); 該語句使div元素順時針旋轉45度。deg是CSS 3的“V
C++四種類型轉換
bin ++ 信息 {} pre 使用 屬性 四種 const 轉載:http://blog.csdn.net/bian_qing_quan11/article/details/70788312 1、 static_cast: 功能:完成編譯器認可的隱式類型轉換。 格式
在防火墻(ASA)上配置四種類型的NAT
豁免 nat 楊書凡 前面已經介紹了網絡地址轉換(NAT)的原理和基於路由器的配置,ASA上的NAT配置相對於路由器來說要復制一些,ASA上的NAT有動態NAT、動態PAT、靜態NAT、靜態PAT。下面的鏈接是我以前寫的NAT原理,在路由器上配置NAT的命令http://yangshufa
JS的四種類型識別方式
object 基本 null 引用 內置 cto 過程 regexp 不能 前言 JS中包含豐富的類型系統,在使用過程中,類型識別是重要的一環。JS提供了4種通用的類型檢測的方法 【typeof】【instanceof】【constructor】【Object.prot
Python之旅-Python基礎4-數據類型
都是 指定 hello double 裏的 移除 空間 class 字符數組 1. 數字 2是一個整數的例子。長整數不過是大一些的整數,3.23和52.3E-4是浮點數的例子。E標記表示10的冪。在這裏,52.3E-4表示52.3 * 10-4. (-5+4j)和(2.3-
遠離“精神乞丐”(IBM的前CEO郭士納把員工分為四種類型)
jpeg 當我 國企員工 習慣性 企業 str 狀態 帶來 src 語音丨吳伯凡 乞丐與其說是一種身份, 不如說是一種精神狀態, 習慣性索取且心安理得, 習慣性尋求安慰,習慣性抱怨, 與之截然對立的, 是“操之在我”(Proactive)
QAtomicInt支持四種類型的操作,Relaxed、Acquired、Release、Ordered
life esp 出現 mic 發現 CP div 讀寫操作 執行 Background 很久很久很久以前,CPU忠厚老實,一條一條指令的執行我們給它的程序,規規矩矩的進行計算和內存的存取。 很久很久以前, CPU學會了Out-Of-Order,CPU有了
SpringCloud微服務基礎4:Feign
Spring Cloud Feign是一套基於Netflix Feign實現的宣告式服務呼叫客戶端。它使得編寫Web服務客戶端變得更加簡單。我們只需要通過建立介面並用註解來配置它既可完成對Web服務介面的繫結。它具備可插拔的註解支援,包括Fei
tensorflow基礎學習:字元數字驗證碼寫入tfrecord檔案封裝成類
今天分享一下我寫的一個小小程式,基本可以滿足數字+字元型別字串寫入tfrecord檔案。還請多多指教! 簡單說明:這個是數字+字元4位驗證碼的tfrecord生成程式碼,5位,6位的可以自行修改一下,也就一點程式碼。我因為有點晚了就先不改了,大家加油啦。 先做些準備工作。
中介軟體系列三 RabbitMQ之交換機的四種類型和屬性
<div class="markdown_views prism-atom-one-dark"> &
static_cast,const_cat,reinterpret_cast,dynamic_cast四種類型的轉換的區別
1.static_cast 一般的內建型別轉換或者具有繼承關係的物件之間的轉換 #include <iostream> using namespace std; class animal
Tensorflow基礎4-(epoch, iteration和batchsize)
batchsize:批大小。在深度學習中,一般採用SGD訓練, 即每次訓練在訓練集中取batchsize個樣本訓練; iteration:1個iteration等於使用batchsize個樣本訓練一次; epoch:1個epoch等於使用訓練集中的全部樣本訓練一次; 舉