
Java8中的Stream API詳解:Stream的背景及使用
摘要:
Stream是Java8的一大亮點,是對容器物件功能的增強,它專注於對容器物件進行各種非常便利、高效的 聚合操作(aggregate operation)或者大批量資料操作。Stream API藉助於同樣新出現的Lambda表示式,極大的提高程式設計效率和程式可讀性。同時,它提供序列和並行兩種模式進行匯聚操作,併發模式能夠充分利用多核處理器的優勢,使用fork/join並行方式來拆分任務和加速處理過程。所以說,Java8中首次出現的 java.util.stream是一個函式式語言+多核時代綜合影響的產物。
本文轉載於陳爭雲,佔宇劍和司磊在developerWorks上發表的
一. 引子
1、為什麼需要Stream ?
Stream作為Java8的一大亮點,它與java.io包裡的InputStream和OutputStream是完全不同的概念。它也不同於StAX對XML解析的Stream,也不是Amazon Kinesis對大資料實時處理的Stream。Java8中的Stream是對容器物件功能的增強,它專注於對容器物件進行各種非常便利、高效的 聚合操作(aggregate operation),或者大批量資料操作 (bulk data operation)。Stream API藉助於同樣新出現的Lambda表示式,極大的提高程式設計效率和程式可讀性。同時,它提供序列和並行兩種模式進行匯聚操作,併發模式能夠充分利用多核處理器的優勢,使用fork/join並行方式來拆分任務和加速處理過程。通常,編寫並行程式碼很難而且容易出錯, 但使用Stream API無需編寫一行多執行緒的程式碼,就可以很方便地寫出高效能的併發程式。所以說,Java8中首次出現的 java.util.stream是一個函式式語言+多核時代綜合影響的產物。
2、什麼是聚合操作
在傳統的J2EE應用中,Java程式碼經常不得不依賴於關係型資料庫的聚合操作來完成諸如:
- 客戶每月平均消費金額
- 最昂貴的在售商品
- 本週完成的有效訂單(排除了無效的)
- 取十個資料樣本作為首頁推薦
這類的操作。但在當今這個資料大爆炸的時代,在資料來源多樣化、資料海量化的今天,很多時候不得不脫離 RDBMS,或者以底層返回的資料為基礎進行更上層的資料統計。而Java的集合API中,僅僅有極少量的輔助型方法,更多的時候是程式設計師需要用Iterator來遍歷集合,完成相關的聚合應用邏輯,這是一種遠不夠高效、笨拙的方法。在Java7中,如果要發現type為grocery的所有交易,然後返回以交易值降序排序好的交易ID集合,我們需要這樣寫:
List<Transaction> groceryTransactions = new Arraylist<>();
for(Transaction t: transactions){
if(t.getType() == Transaction.GROCERY){
groceryTransactions.add(t);
}
}
Collections.sort(groceryTransactions, new Comparator(){
public int compare(Transaction t1, Transaction t2){
return t2.getValue().compareTo(t1.getValue());
}
});
List<Integer> transactionIds = new ArrayList<>();
for(Transaction t: groceryTransactions){
transactionsIds.add(t.getId());
}而在 Java 8 使用 Stream,程式碼更加簡潔易讀;而且使用併發模式,程式執行速度更快。
List<Integer> transactionsIds = transactions.parallelStream()
.filter(t -> t.getType() == Transaction.GROCERY)
.sorted(comparing(Transaction::getValue).reversed())
.map(Transaction::getId).collect(toList());二. Stream總覽
1、什麼是流?
Stream不是集合元素,它不是資料結構並不儲存資料,它是有關演算法和計算的,它更像一個高階版本的Iterator。原始版本的Iterator,使用者只能顯式地一個一個遍歷元素並對其執行某些操作;高階版本的Stream,使用者只要給出需要對其包含的元素執行什麼操作,比如,“過濾掉長度大於 10 的字串”、“獲取每個字串的首字母”等,Stream會隱式地在內部進行遍歷,做出相應的資料轉換。Stream就如同一個迭代器(Iterator),單向,不可往復,資料只能遍歷一次,遍歷過一次後即用盡了,就好比流水從面前流過,一去不復返。
而和迭代器又不同的是,Stream可以並行化操作,迭代器只能命令式地、序列化操作。顧名思義,當使用序列方式去遍歷時,每個item讀完後再讀下一個item。而使用並行去遍歷時,資料會被分成多個段,其中每一個都在不同的執行緒中處理,然後將結果一起輸出。Stream的並行操作依賴於Java7中引入的Fork/Join框架(JSR166y)來拆分任務和加速處理過程。
Stream 的另外一大特點是,資料來源本身可以是無限的。
2、流的構成
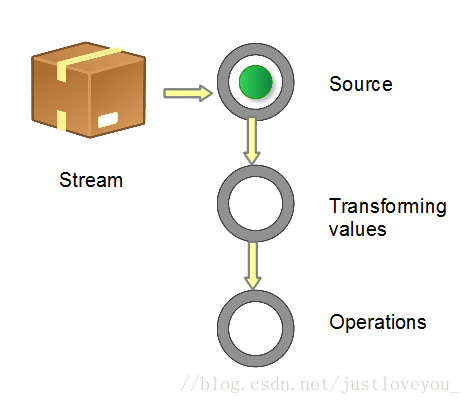
當我們使用一個流的時候,通常包括三個基本步驟:獲取一個數據源(source)→ 資料轉換 → 執行操作獲取想要的結果。每次轉換原有Stream物件不改變,返回一個新的Stream物件(可以有多次轉換),這就允許對其操作可以像鏈條一樣排列,變成一個管道,如下圖所示:
3、Stream的生成方式
(1)從Collection和陣列獲得
- Collection.stream()
- Collection.parallelStream()
- Arrays.stream(T array) or Stream.of()
(2)從BufferedReader獲得
- java.io.BufferedReader.lines()
(3)靜態工廠
- java.util.stream.IntStream.range()
- java.nio.file.Files.walk()
(4)自己構建
- java.util.Spliterator
(5)其他
- Random.ints()
- BitSet.stream()
- Pattern.splitAsStream(java.lang.CharSequence)
- JarFile.stream()
4、流的操作型別
流的操作型別分為兩種:
Intermediate:一個流可以後面跟隨零個或多個intermediate操作。其目的主要是開啟流,做出某種程度的資料對映/過濾,然後返回一個新的流,交給下一個操作使用。這類操作都是惰性化的(lazy),就是說,僅僅呼叫到這類方法,並沒有真正開始流的遍歷。
Terminal:一個流只能有一個terminal操作,當這個操作執行後,流就被使用“光”了,無法再被操作。所以,這必定是流的最後一個操作。Terminal操作的執行,才會真正開始流的遍歷,並且會生成一個結果,或者一個side effect。
在對一個Stream進行多次轉換操作(Intermediate 操作),每次都對Stream的每個元素進行轉換,而且是執行多次,這樣時間複雜度就是N(轉換次數)個for迴圈裡把所有操作都做掉的總和嗎?其實不是這樣的,轉換操作都是lazy的,多個轉換操作只會在Terminal操作的時候融合起來,一次迴圈完成。我們可以這樣簡單的理解,Stream裡有個操作函式的集合,每次轉換操作就是把轉換函式放入這個集合中,在Terminal 操作的時候迴圈Stream對應的集合,然後對每個元素執行所有的函式。
還有一種操作被稱為short-circuiting。用以指:對於一個intermediate操作,如果它接受的是一個無限大(infinite/unbounded)的Stream,但返回一個有限的新Stream;對於一個terminal操作,如果它接受的是一個無限大的Stream,但能在有限的時間計算出結果。
當操作一個無限大的 Stream,而又希望在有限時間內完成操作,則在管道內擁有一個short-circuiting操作是必要非充分條件。
三. 流的使用詳解
簡單說,對Stream的使用就是實現一個filter-map-reduce過程,產生一個最終結果,或者導致一個副作用(side effect)。
1).流的構造與轉換
下面提供最常見的幾種構造Stream的例子:
// 1. Individual values
Stream stream = Stream.of("a", "b", "c");
// 2. Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3. Collections
List<String> list = Arrays.asList(strArray);
stream = list.stream();需要注意的是,對於基本數值型,目前有三種對應的包裝型別Stream:IntStream、LongStream、DoubleStream。當然我們也可以用 Stream<Integer>、Stream<Long>和Stream<Double>,但是boxing/unboxing會很耗時,所以特別為這三種基本數值型提供了對應的Stream。
Java8中還沒有提供其它數值型Stream,因為這將導致擴增的內容較多。而常規的數值型聚合運算可以通過上面三種Stream進行。
IntStream.of(new int[]{1, 2, 3}).forEach(System.out::println);
IntStream.range(1, 3).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);流也可以轉換為其它資料結構,例如:
// 1. Array
String[] strArray1 = stream.toArray(String[]::new);
// 2. Collection
List<String> list1 = stream.collect(Collectors.toList());
List<String> list2 = stream.collect(Collectors.toCollection(ArrayList::new));
Set set1 = stream.collect(Collectors.toSet());
Stack stack1 = stream.collect(Collectors.toCollection(Stack::new));
// 3. String
String str = stream.collect(Collectors.joining()).toString();2).流的操作
接下來,當把一個數據結構包裝成Stream後,就要開始對裡面的元素進行各類操作了。常見的操作可以歸類如下:
Intermediate 操作
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
Terminal 操作
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Short-circuiting 操作
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
我們下面看一下Stream的比較典型用法。
(1).Intermediate 操作
map/flatMap
我們先來看map,它的作用就是把inputStream的每個元素對映成outputStream的另外一個元素,例如:
List<Integer> nums = Arrays.asList(1, 2, 3, 4);
List<Integer> squareNums = nums.stream().map(n -> n * n)
.collect(Collectors.toList());從上面例子可以看出,map生成的是個1:1對映,每個輸入元素都按照規則轉換成為另外一個元素。還有一些場景,是一對多對映關係的,這時需要flatMap,例如:
Stream<List<Integer>> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
Stream<Integer> outputStream = inputStream.
flatMap((childList) -> childList.stream());flatMap把inputStream中的層級結構 扁平化,就是將最底層元素抽出來放到一起,最終output的新Stream裡面已經沒有List了,都是直接的數字。
filter
filter對原始Stream進行某項測試,通過測試的元素被留下來生成一個新Stream。
// 留下偶數
Integer[] sixNums = {1, 2, 3, 4, 5, 6};
Integer[] evens =
Stream.of(sixNums).filter(n -> n%2 == 0).toArray(Integer[]::new);forEach
forEach方法接收一個Lambda表示式,然後在Stream的每一個元素上執行該表示式。
// 對一個人員集合遍歷,找出男性並列印姓名。
roster.stream().filter(p -> p.getGender() == Person.Sex.MALE)
.forEach(p -> System.out.println(p.getName()));可以看出來,forEach是為Lambda而設計的,保持了最緊湊的風格。當需要為多核系統優化時,可以parallelStream().forEach(),只是此時原有元素的次序沒法保證,並行的情況下將改變序列時操作的行為,此時forEach本身的實現不需要調整,而Java8以前的for迴圈程式碼可能需要加入額外的多執行緒邏輯。但一般認為,forEach和常規for迴圈的差異不涉及到效能,它們僅僅是函式式風格與傳統 Java 風格的差別。
另外一點需要注意,forEach是terminal操作。因此,它執行後,Stream 的元素就被“消費”掉了,你無法對一個Stream進行兩次terminal運算。下面的程式碼是錯誤的:
stream.forEach(element -> doOneThing(element));
stream.forEach(element -> doAnotherThing(element));相反,具有相似功能的intermediate操作peek可以達到上述目的。如下是出現在Stream api javadoc上的一個示例:
// peek 對每個元素執行操作並返回一個新的 Stream
Stream.of("one", "two", "three", "four").filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e)).map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e)).collect(Collectors.toList());forEach 不能修改自己包含的本地變數值,也不能用break/return之類的關鍵字提前結束迴圈。
findFirst
這是一個termimal兼short-circuiting操作,它總是返回Stream的第一個元素或者空。這裡比較重點的是它的返回值型別Optional:這也是一個模仿 Scala 語言中的概念,作為一個容器,它可能含有某值,或者不包含,使用它的目的是儘可能避免NullPointerException。
// Optional 的兩個用例:以下兩組示例是等價的
// Java 8
Optional.ofNullable(text).ifPresent(System.out::println);
// Pre-Java 8
if (text != null) {
System.out.println(text);
}
//----------
// Java 8
return Optional.ofNullable(text).map(String::length).orElse(-1);
// Pre-Java 8
return if (text != null) ? text.length() : -1;
};在更復雜的if (xx != null)的情況中,使用Optional程式碼的可讀性更好,而且它提供的是編譯時檢查,能極大的降低NPE這種Runtime Exception 對程式的影響,或者迫使程式設計師更早的在編碼階段處理空值問題,而不是留到執行時再發現和除錯。
Stream中的findAny、max/min、reduce等方法等返回Optional值。還有例如IntStream.average()返回OptionalDouble等等。
reduce
這個方法的主要作用是把Stream元素組合起來。它提供一個起始值(種子),然後依照運算規則(BinaryOperator),和前面Stream的第一個、第二個、第n個元素組合。從這個意義上說,字串拼接、數值的 sum、min、max、average都是特殊的reduce。例如Stream的sum就相當於:
Integer sum = integers.reduce(0, (a, b) -> a+b);或
Integer sum = integers.reduce(0, Integer::sum);也有沒有起始值的情況,這時會把 Stream 的前面兩個元素組合起來,返回的是 Optional。
// reduce 的用例
// 字串連線,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 無起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 過濾,字串連線,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").
filter(x -> x.compareTo("Z") > 0).
reduce("", String::concat);上面程式碼例如第一個示例的reduce(),第一個引數(空白字元)即為起始值,第二個引數(String::concat)為 BinaryOperator。這類有起始值的 reduce() 都返回具體的物件。而對於第四個示例沒有起始值的 reduce(),由於可能沒有足夠的元素,返回的是 Optional,請留意這個區別。
limit/skip
limit返回Stream的前面n個元素;skip則是扔掉前n個元素(它是由一個叫 subStream的方法改名而來)。
//limit 和 skip 對執行次數的影響
public void testLimitAndSkip() {
List<Person> persons = new ArrayList();
for (int i = 1; i <= 10000; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<String> personList2 = persons.stream().
map(Person::getName).limit(10).skip(3).collect(Collectors.toList());
System.out.println(personList2);
}
private class Person {
public int no;
private String name;
public Person (int no, String name) {
this.no = no;
this.name = name;
}
public String getName() {
System.out.println(name);
return name;
}
}
輸出結果為:
name1
name2
name3
name4
name5
name6
name7
name8
name9
name10
[name4, name5, name6, name7, name8, name9, name10]這是一個有10,000個元素的Stream,但在short-circuiting操作limit和skip的作用下,管道中map操作指定的getName()方法的執行次數為 limit 所限定的10次,而最終返回結果在跳過前3個元素後只有後面7個返回。
有一種情況是limit/skip無法達到short-circuiting目的的,就是把它們放在Stream的排序操作後,原因跟sorted這個intermediate操作有關:此時系統並不知道Stream排序後的次序如何,所以sorted中的操作看上去就像完全沒有被limit或者skip一樣。
// limit 和 skip 對 sorted 後的執行次數無影響
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList2 = persons.stream().sorted((p1, p2) ->
p1.getName().compareTo(p2.getName())).limit(2).collect(Collectors.toList());
System.out.println(personList2);
輸出結果為:
name2
name1
name3
name2
name4
name3
name5
name4
[[email protected]816f27d,[email protected]87aac27]即雖然最後的返回元素數量是 2,但整個管道中的 sorted 表示式執行次數沒有像前面例子相應減少。最後有一點需要注意的是,對一個parallel的Stream 管道來說,如果其元素是有序的,那麼limit操作的成本會比較大,因為它的返回物件必須是前n個也有一樣次序的元素。取而代之的策略是取消元素間的次序,或者不要用parallel Stream。
sorted
對Stream的排序通過sorted進行,它比陣列的排序更強之處在於你可以首先對Stream進行各類map、filter、limit、skip甚至distinct來減少元素數量後再排序,這能幫助程式明顯縮短執行時間。例如:
// 優化:排序前進行 limit 和 skip
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList2 = persons.stream().limit(2).sorted((p1, p2) -> p1.getName().compareTo(p2.getName())).collect(Collectors.toList());
System.out.println(personList2);結果會簡單很多:
name2
name1
[[email protected]6ce253f1,[email protected]53d8d10a]當然,這種優化是有business logic上的侷限性的:即不要求排序後再取值。
min/max/distinct
min和max的功能也可以通過對Stream元素先排序,再findFirst來實現,但前者的效能會更好為O(n),而sorted的成本是O(nlogn)。同時它們作為特殊的reduce方法被獨立出來也是因為求最大最小值是很常見的操作。
// 找出最長一行的長度
BufferedReader br = new BufferedReader(new FileReader("c:\\SUService.log"));
int longest = br.lines().mapToInt(String::length).max().getAsInt();
br.close();
System.out.println(longest);distinct
下面的例子則使用distinct來找出不重複的單詞。
// 找出全文的單詞,轉小寫,並排序
List<String> words = br.lines().flatMap(line -> Stream.of(line.split(" "))).
filter(word -> word.length() > 0).map(String::toLowerCase).distinct().sorted()
.collect(Collectors.toList());
br.close();
System.out.println(words);Match
Stream有三個match方法,從語義上說:
(1).allMatch:Stream 中全部元素符合傳入的 predicate,返回 true;
(2).anyMatch:Stream 中只要有一個元素符合傳入的 predicate,返回 true;
(3).noneMatch:Stream 中沒有一個元素符合傳入的 predicate,返回 true.它們都不是要遍歷全部元素才能返回結果。例如allMatch只要一個元素不滿足條件,就skip剩下的所有元素,返回false。對清單13中的Person類稍做修改,加入一個age屬性和getAge方法。
// 使用 Match
List<Person> persons = new ArrayList();
persons.add(new Person(1, "name" + 1, 10));
persons.add(new Person(2, "name" + 2, 21));
persons.add(new Person(3, "name" + 3, 34));
persons.add(new Person(4, "name" + 4, 6));
persons.add(new Person(5, "name" + 5, 55));
boolean isAllAdult = persons.stream().allMatch(p -> p.getAge() > 18);
System.out.println("All are adult? " + isAllAdult);
boolean isThereAnyChild = persons.stream().anyMatch(p -> p.getAge() < 12);
System.out.println("Any child? " + isThereAnyChild);
輸出結果:
All are adult? false
Any child? true四. 小結
總之,Stream 的特性可以歸納為:
不是資料結構;
它沒有內部儲存,它只是用操作管道從source(資料結構、陣列、generator function、IO channel)抓取資料;
它也絕不修改自己所封裝的底層資料結構的資料。例如Stream的filter操作會產生一個不包含被過濾元素的新Stream,而不是從source刪除那些元素;
所有Stream的操作必須以lambda表示式為引數;
不支援索引訪問;
你可以請求第一個元素,但無法請求第二個,第三個,或最後一個;
很容易生成陣列或者List;
惰性化;
很多Stream操作是向後延遲的,一直到它弄清楚了最後需要多少資料才會開始;
Intermediate操作永遠是惰性化的;
並行能力;
當一個 Stream 是並行化的,就不需要再寫多執行緒程式碼,所有對它的操作會自動並行進行的;
可以是無限的。集合有固定大小,Stream 則不必。limit(n)和findFirst()這類的short-circuiting操作可以對無限的Stream進行運算並很快完成。
引用:
相關推薦
Java8中的Stream API詳解:Stream的背景及使用
摘要: Stream是Java8的一大亮點,是對容器物件功能的增強,它專注於對容器物件進行各種非常便利、高效的 聚合操作(aggregate operation)或者大批量資料操作。Stream API藉助於同樣新出現的Lambda表示式,極大的提
Java8學習筆記(五)--Stream API詳解[轉]
有效 編程效率 實時處理 phaser 綜合 files -- bin 並發模式 為什麽要使用StreamStream 作為 Java 8 的一大亮點,它與 java.io 包裏的 InputStream 和 OutputStream 是完全不同的概念。它也不同於 StAX
Quartz.Net系列(十三):DateBuilder中的API詳解
1.DateOf、ToDayAt、TomorrowAt DateOf:指定年月日時分秒 public static DateTimeOffset DateOf(int hour, int minute, int second) { ValidateSe
Java8 Stream語法詳解 不用迴圈
1. Stream初體驗 我們先來看看Java裡面是怎麼定義Stream的: A sequence of elements supporting sequential and parallel aggregate operations. 我們來解讀一下上面的那句話:
Java8初體驗(二)Stream語法詳解
感謝同事【天錦】的投稿。投稿請聯絡 [email protected] 上篇文章Java8初體驗(一)lambda表示式語法比較詳細的介紹了lambda表示式的方方面面,細心的讀者會發現那篇文章的例子中有很多Stream的例子。這些Stream的例子可能讓你產生疑惑,本文將會詳細講解
Java8的Stream流詳解
首先,Stream流有一些特性: Stream流不是一種資料結構,不儲存資料,它只是在原資料集上定義了一組操作。 這些操作是惰性的,即每當訪問到流中的一個元素,才會在此元素上執行這一系列操作。 Stream不儲存資料,故每個Stream流只能使用一次。
D3.js中Stream graph詳解
var n = 20, // number of layers 層的總數 m = 200, // number of samples per layer 每層的樣本數目 k = 10; // number of bumps per layer 每層的顛簸總數 // d3.stack()
Java8-Stream語法詳解
1. Stream初體驗 我們先來看看Java裡面是怎麼定義Stream的: A sequence of elements supporting sequential and parallel aggregate operations.
Java8體驗(二)Stream語法詳解
1. Stream初體驗 我們先來看看Java裡面是怎麼定義Stream的: A sequence of elements supporting sequential and parallel aggregate operations. 我們來解
jdk1.8 java.util.stream.Stream類 詳解
-c 打印 而不是 oid ole 表達 ice java-8 java 8 為什麽需要 Stream Stream 作為 Java 8 的一大亮點,它與 java.io 包裏的 InputStream 和 OutputStream 是完全不同的概念。它也不同於 StAX
Collection中帶有All結尾的常用API詳解
相同 contains 不變 這樣的 添加 重新 lean addall als Collection中帶有All結尾的常用API有四種:addAll(),removeAll(),containsAll() 和 retainAll() 詳解: 假設現有2個List對象,分別
[轉]Java 8 中的 Streams API 詳解
原文連結:https://www.ibm.com/developerworks/cn/java/j-lo-java8streamapi/ 為什麼需要 Stream Stream 作為 Java 8 的一大亮點,它與 java.io 包裡的 InputStream 和 OutputStrea
Java 8 中的 Streams API 詳解
Streams 的背景,以及 Java 8 中的使用詳解 陳 爭雲, 佔 宇劍, 和 司 磊 2014 年 9 月 11 日釋出 49 為什麼需要 Stream Stream 作為 Java 8 的一大亮點,它與 java.io 包裡的 InputStre
NodeJS中的事件(EventEmitter) API詳解(附原始碼)
EventEmitter 簡介 EventEmitter 是 NodeJS 的核心模組 events 中的類,用於對 NodeJS 中的事件進行統一管理,用 events 特定的 API 對事件進行新增、觸發和移除等等,核心方法的模式類似於釋出訂閱。 實現 EventEm
Node中fs模組 API詳解
fs 概述 在 NodeJS 中,所有與檔案操作都是通過 fs 核心模組來實現的,包括檔案目錄的建立、刪除、查詢以及檔案的讀取和寫入,在 fs 模組中,所有的方法都分為同步和非同步兩種實現,具有 sync 字尾的方法為同步方法,不具有 sync 字尾的方法為非同步方法,在瞭
Stream Grouping詳解
Storm裡面有7種型別的stream grouping shuffle Grouping :隨機分組,隨機派發stream裡面的tuple,保證每個bolt接收到的tuple數目大致相同。 Fields Grouping:按欄位分組,比如按userID來分組,具有同樣userI
Java8 Date API 詳解 - LocalDate,LocalDateTime,Instant
轉載來源:https://www.journaldev.com/2800/java-8-date-localdate-localdatetime-instant Java8 Date API 詳解 - LocalDate,LocalDateTime,Instant &nbs
JDK 8 中的 Streams API 詳解
Stream API介紹 Java 8引入了全新的Stream API,此Stream與java I/O包裡的InputStream和OutputStream是完全不同的概念,它不
JDK8新特性詳解-Stream流常用方法(二)
### **Stream流的使用** 流操作是Java8提供一個重要新特性,它允許開發人員以宣告性方式處理集合,其核心類庫主要改進了對集合類的 API和新增Stream操作。Stream類中每一個方法都對應集合上的一種操作。將真正的函數語言程式設計引入到Java中,能 讓程式碼更加簡潔,極大地簡化了集合
C/C++中extern關鍵字詳解
編譯器 fin 生成 接口 bcd 只需要 c++環境 結束 編程 轉自:http://www.cnblogs.com/yc_sunniwell/archive/2010/07/14/1777431.html 1 基本解釋:extern可以置於變量或者函數前,以標示變量或者