
NLP論文筆記1:Neural Architectures for Named Entity Recognition
看這一篇論文的主要目的是看BILSTM-CRF模型,對於實際應用,CRF看分詞、BILSTM-CRF做NER,接下來通過BILSTM-CNN-CRF做序列標註,NLP幾個基本的應用也差不多了,句法分析貌似比較複雜,留作以後吧。
********************開始論文吧****************
一.敘述
命名實體識別一直是更具挑戰性的NLP應用,為什麼更具挑戰呢?原因有兩方面,一方面,可用的已標註的命名實體資料集很少,量也小;另一方面,命名詞的規律性不強,約束很少,組織名稱、地名,隨意性還是很強的,還有一方面是新加入的命名詞、新加入的領域也很多,想從小批量的資料集中提取出完整的特徵,比較難。
這篇論文將命名實體分為兩種:1.多個片語成的命名實體,2.單個片語成的命名實體。對於第一種,實體中的每個詞都很重要,且詞與詞之間的關係也要關注,作者用了兩種模型來對比這種命名的識別效果——BILSTM-CRF和棧式LSTM。
第二種命名有兩個重點:什麼樣的詞更像是實體?一個詞在什麼樣的語境下更容易成為實體。作者採用了字向量來解決第一個問題,採用詞向量來解決第二個問題。
訓練時使用dropout提高泛化。
二. LSTM-CRF模型
1.LSTM輸出到CRF tagging
LSTM和CRF模型都不陌生,之前都單獨看過原理和程式,這裡,笨妞更關心的是BILSTM後的結果如何與CRF結合起來。
作者認為,使用LSTM處理NLP問題最簡單的方式是將輸出LSTM層的輸出作為特徵直接用於tagging決策,這種方式在POS標註上很有效,但是在對外部的標籤依賴性很強的分類問題上侷限性很大,而NER正好是這樣的問題。因為在NER的序列標註“語法”中的那些規則很難用獨立的假設建立模型。
作者將LSTM的輸出作為打分矩陣(稱作P),
對於一個輸入句子
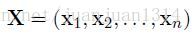
P是一個n*k的矩陣,k是輸出標註Y的取值個數,
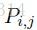
這個句子的預測標註序列表示為
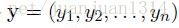
定義y矩陣的打分函式為
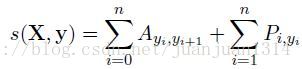
其中,A是轉移打分矩陣,
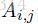 代表從標註i轉移到標註j的得分。
代表從標註i轉移到標註j的得分。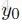 和
和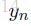 分別是新增的start和end結點,所以,標註矩陣實際的size是k+2。
分別是新增的start和end結點,所以,標註矩陣實際的size是k+2。 然後,然後一個softmax計算所有可能的標註的概率:
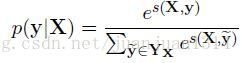
訓練時採用極大似然估計作為損失函式,對數似然函式如下:
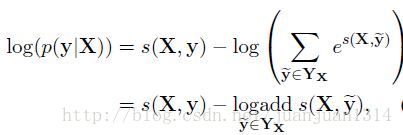
其中,
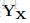 表示句子X所有可能的標註序列(實際就是規範化因子Z)。
表示句子X所有可能的標註序列(實際就是規範化因子Z)。 預測輸出序列時通過以下公式的最大得分得到:
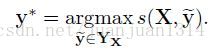
2.引數和訓練
最後的打分是BILSTM的輸出(每個詞的向量)和類似於二元語法的轉移分數結合計算出來的,整個網路的結構如下:
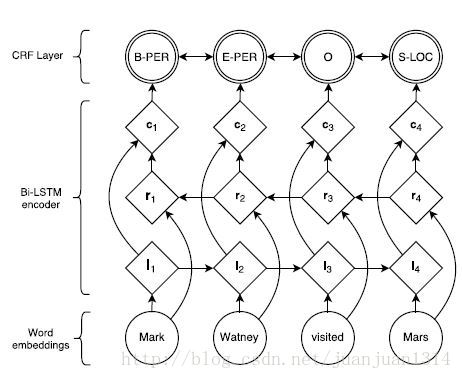
圖1
整個模型的引數是二元轉移打分矩陣A中的各分數和BILSTM中用於計算矩陣P的引數和BILSTM的輸入詞向量。
為了改善結果,作者還在ci層和CRF層添加了一個隱層。以上所有的引數優化的目標都是最大化對數似然函式。
3.Tagging Schemes
作者提到了兩種tagging scheme,一種是IOB標註形式的,這種形式標註集為{B、I、O},B表示命名實體的開頭詞,I表示命名實體非開始的詞,O表示非命名實體詞。另一箇中是IOBES標註形式,標註集合為{B、I、E、O、S},新增的E表示命名實體結尾詞,S表示單個詞的命名實體。
三.Stack-LSTM
stack-LSTM在transition-based 依存句法分析被用到,這個模型可以直接構建多詞的命名實體。
模型通過一個堆疊資料結構來構建輸入的分塊。在stack-LSTM中,LSTM通過一個堆疊指標擴充套件。序列化的LSTM是從左到右的,而stack-LSTM確保embedding記錄既可以增加,也可以移除,他的工作原理如同堆疊資料結構。
這個模型的原論文是《Transition-based dependency parsing with stack long-short-term memory》
1.chunking演算法
模型包含兩個元件:transition inventory、存已經處理過的詞的buffer。transition inventory如下圖

圖2
如圖所示,transition的動作包含3個:SHIFT、REDUCE、OUT。SHIFT transition將從buffer搬到stack;OUT transition將詞從buffer直接搬到輸出stack;REDUCE transition從stack的top層將所有詞推出來,組成 “chunking”,並將這個chunking的representation壓入到output stack中。當stack和output stack全部為空,這個演算法要做的事情就完了。
模型通過定義每一時刻下的動作的概率分佈來使模型引數化,LSTM的輸出用於計算每一時刻採取的action的個概率分佈,通過最大化整個序列的標準標註的條件概率而使模型得到訓練。
預測過程中,尋找輸入序列每一步概率最大的action。對於對於輸入序列中的每個詞將經歷從buffer直接到輸出,或者從buffer到stack,再從stack到輸出這兩步。對於長度為n的序列,最多了2n個action。
(這個模型真心沒怎麼看懂,後面看看原論文再說吧)
四.輸入Word Embeeding
這一部分主要看基於字母的詞模型,詞向量之前已經看過了。
1.模型
下圖是通過字母生成詞的embedding的結構:
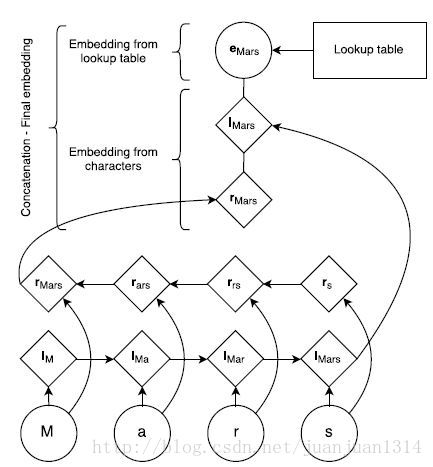
圖3
首先,生成一份字母的向量查詢表,每個字母的向量隨機生成,同時還有一份詞自身的向量查詢表。根據LSTM的前向和後向詞順序查詢子母向量表得到基於字母的正序向量和逆序向量,再和詞lookup向量一起組成完整的詞向量輸入到BILSTM。
如圖3所示,詞”Mars”的詞向量生成過程。首先,從Lookup table中查詢出字母”M”,”a”,”r”,”s”這4個字母的向量,然後根據正序和逆序分別組成“M->a->r->s”的向量和“s->r->a->M”的向量,最後詞word的lookup table向量、基於字母的正序向量、基於字母的逆序向量共同組成”Mars”的向量。
2.預訓練
上一部分提到基於字母的lookup向量和詞lookup向量表是隨機生成的,但這樣的效果沒有預訓練的效果好。
作者用word2vec的skip-n-gram訓練詞的lookup向量,然後在模型訓練時只做fine-tuned。
3.dropout
作者發現,用隨機初始化的字母lookup向量也預訓練的詞向量結合,效果並不理想,於是在組合兩方面向量的最後一層加入了一個dropout後,再輸入到BILSTM,這樣效果顯著。
五.實驗
1.模型超引數配置
訓練通過BP演算法更新引數。用SGD以0.01的學習率優化引數,以5.0作為梯度的閾值。
LSTM-CRF模型用前向和後向LSTM各一個獨立層,維度為100,並加入了0.5的dropout。
Stack-LSTM每一個stack用了2個100維的網路層,用16維的向量表示actoion,輸出向量為20維。這個模型也加入了dropout,dropout rate通過除錯,採用最好的那一個(不固定),採用貪婪模型,獲取區域性最優。
2.實驗結果
作者對比了各參考論文的結果和自己的4種模型的結果,結果如下:
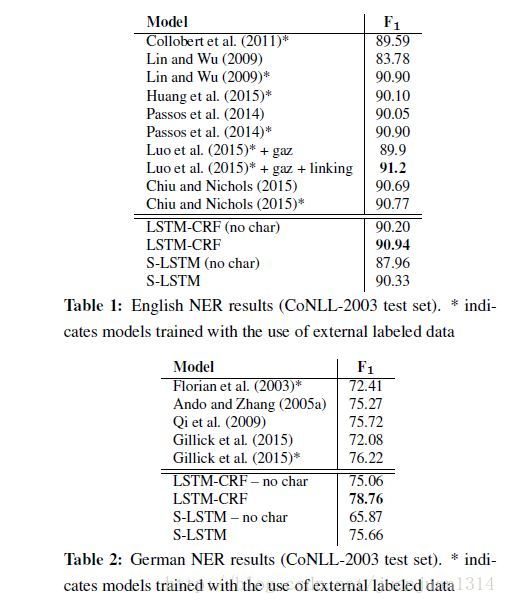
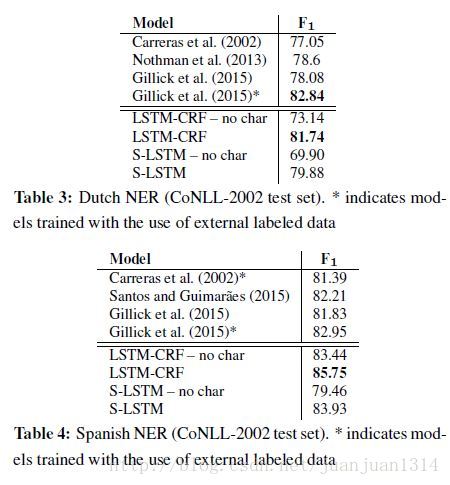
總體來說帶基於字母的詞向量表示的BILSTM-CRF模型的準確率在4種語言的NER工作準確性最好。
*************************論文看完啦****************
看起來很不錯的樣子,接下來就是跑BILSTM-CRF的時刻啦。程式自帶的程式碼是通過Theano實現的,對於只會用tensorflow的笨妞來說,默默的找一個tensorflow版本的改一改算了。
相關推薦
NLP論文筆記1:Neural Architectures for Named Entity Recognition
看這一篇論文的主要目的是看BILSTM-CRF模型,對於實際應用,CRF看分詞、BILSTM-CRF做NER,接下來通過BILSTM-CNN-CRF做序列標註,NLP幾個基本的應用也差不多了,句法分析貌似比較複雜,留作以後吧。 ****************
【深度學習NLP論文筆記】《Adversarial Example For Natural Language Classification Problems》
一、介紹 圖一:三個在文字分類任務中使用對抗樣本的例子。分別是垃圾郵件分類、情感分析、虛假新聞檢測。全是依靠同義詞替換實現的。 二、背景 分類問題的目標是從輸入和標籤中學習一種對映。其中標籤可能來自K個類,如。 分類器f可能是個深度神經網路或者線性模型,它會為輸入x
【深度學習論文筆記】Deep Neural Networks for Object Detection
論文:<<Deep Neural Networks for Object Detection>> 作者:Christian Szegedy Al
論文筆記之:Collaborative Deep Reinforcement Learning for Joint Object Search
region format es2017 join sid col str bottom respond Collaborative Deep Reinforcement Learning for Joint Object Search CVPR 2017 Motiva
論文筆記10:ITSEGO: An Ontology for Game-based Intelligent Tutoring Systems
參考論文:ITSEGO: An Ontology for Game-based Intelligent Tutoring Systems Abstract 這項工作提出了一個方法,發展學生解決問題的能力和數字能力,實現從幼兒園到小學的過渡。通過一種基於本體的方法,該方法將一個智慧的輔導系統(
論文筆記6:Increasing the Action Gap: New Operators for Reinforcement Learning
參考文獻:New Operators for Reinforcement Learning 同名知乎:uuummmmiiii 這篇文章實在是式子多,整個看懵,網上目前沒啥人看過這篇,論文有兩部分,我掙扎了一下看了第一部分,所以第二部分具體作者創新了什麼,做了什麼相關推導我也不知道,哭泣。 如有
【論文筆記1】RNN在影象壓縮領域的運用——Variable Rate Image Compression with Recurrent Neural Networks
一、引言 隨著網際網路的發展,網路圖片的數量越來越多,而使用者對網頁載入的速度要求越來越高。為了滿足使用者對網頁載入快速性、舒適性的服務需求,如何將影象以更低的位元組數儲存(儲存空間的節省意味著更快的傳輸速度)並給使用者一個低解析度的thumbnails(縮圖)的previ
【深度學習:目標檢測】RCNN學習筆記(1):Rich feature hierarchies for accurate object detection and semantic segmentat
轉載:http://blog.csdn.net/u011534057/article/details/51218218 rcnn主要作用就是用於物體檢測,就是首先通過selective search 選擇2000個候選區域,這些區域中有我們需要的所對應的物體的bound
計算機視覺論文筆記五:Maximal Linear Embedding for Dimensionality Reduction
版權論文作者所有,本筆記僅用作學術交流,主要是做個筆記。這篇論文寫的很友好,很清楚,你腦子裡出現了什麼疑問,下一句就是答案。而且是工科思維,很多實現細節作者也會提到,整篇論文幾乎就是有不能更詳細註釋的程式碼!!我的鴿,被校友的論文圈粉了。我也要向著這種方向思考,寫作。IEEE
Neural Network Toolbox使用筆記1:資料擬合
Neural Network Toolbox為各種複雜的非線性系統的建模提供多種函式和應用程式。該工具箱提供各種監督學習模型:前向反饋,徑向基核函式和動態網路等模型。同時也提供自組織圖和競爭層結構(competitive layers)的非監督學習模型。該工具箱具有設計、訓
【ucosii】筆記1:移植
err color border 工作 mrc pro read cfg mut 前言 ucosii的代碼,可以分為兩部分:與cpu無關的代碼,與cpu有關。移植的主要工作就是修改與cpu有關的部分代碼。 ucosii的代碼結構 與cpu無關的代碼
設計模式筆記1:簡單工廠模式
1.3 簡單 修改 作用 面向對象 對象 面向 tro 計算 如果想成為一名更優秀的軟件設計師,了解優秀軟件設計的演變過程比學習優秀設計本身更有價值。 1.1 面向對象的好處 通過封裝、繼承多態把程序的耦合度降低,使用設計模式使得程序更加靈活,容易修改,易於復用
Effictive Java學習筆記1:創建和銷毀對象
安全 需要 () 函數 調用 bsp nbsp bean 成了 建議1:考慮用靜態工廠方法代替構造器 理由:1)靜態方法有名字啊,更容易懂和理解。構造方法重載容易讓人混淆,並不是好主意 2)靜態工廠方法可以不必每次調用時都創建一個新對象,而公共構造函數每次調用都會
論文筆記-Wide & Deep Learning for Recommender Systems
wiki body pos ear recommend sys con 損失函數 wrapper 本文提出的W&D是針對rank環節的模型。 網絡結構: 本文提出的W&D是針對rank環節的模型。 網絡結構: wide是簡單的線性模型,但
golang學習筆記(1):安裝&helloworld
golang安裝:golang編譯器安裝過程比較簡單,也比較快,不同平臺下(win/linux/macos)都比較相似;https://dl.gocn.io/golang/1.9.2/go1.9.2.src.tar.gz 下載對應的系統版本的編譯器go的版本號由"." 分為3部分如當前的
《黑客攻防技術寶典Web實戰篇@第2版》讀書筆記1:了解Web應用程序
金融 主機 border ket 邊界 輕量 在線 讀書 目的 讀書筆記第一部分對應原書的第一章,主要介紹了Web應用程序的發展,功能,安全狀況。 Web應用程序的發展歷程 早期的萬維網僅由Web站點構成,只是包含靜態文檔的信息庫,隨後人們發明了Web瀏覽器用來檢索和
寒假學習筆記1:結構化程序設計
控制流程 ram 循環 只有一個 嚴格 學習筆記 程序編寫 ont 部分 結構化程序設計(structured programming)是進行以模塊功能和處理過程設計為主的詳細設計的基本原則。 - 內容 主張使用順序、選擇、循環三種基本結構來嵌套連結成具有復雜層次的“結構
hibernate框架學習筆記1:搭建與測試
for this ble action 1.7 turn yiq targe cts hibernate框架屬於dao層,類似dbutils的作用,是一款ORM(對象關系映射)操作 使用hibernate框架好處是:操作數據庫不需要寫SQL語句,使用面向對象的方式完成
struts2框架學習筆記1:搭建測試
method lang app org char 示例 重要 type img Servlet是線程不安全的,Struts1是基於Servlet的框架 而Struts2是基於Filter的框架,解決了線程安全問題 因此Struts1和Struts2基本沒有關系,只是創造者取
Python學習筆記1:用戶登錄
\n win col lines %s courier class for ID 1 import getpass,sys 2 u=0 3 while u< 3: 4 user_name = input(‘Please input you