
Deep learning:四十五(maxout簡單理解)
maxout出現在ICML2013上,作者Goodfellow將maxout和dropout結合後,號稱在MNIST, CIFAR-10, CIFAR-100, SVHN這4個數據上都取得了start-of-art的識別率。
從論文中可以看出,maxout其實一種激發函式形式。通常情況下,如果激發函式採用sigmoid函式的話,在前向傳播過程中,隱含層節點的輸出表達式為:
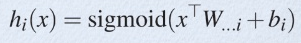
其中W一般是2維的,這裡表示取出的是第i列,下標i前的省略號表示對應第i列中的所有行。但如果是maxout激發函式,則其隱含層節點的輸出表達式為:
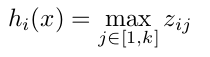
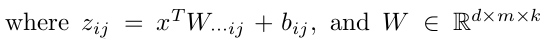
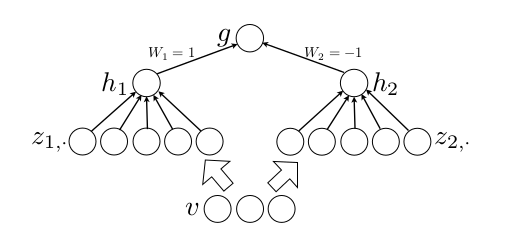
這裡的W是3維的,尺寸為d*m*k,其中d表示輸入層節點的個數,m表示隱含層節點的個數,k表示每個隱含層節點對應了k個”隱隱含層”節點,這k個”隱隱含層”節點都是線性輸出的,而maxout的每個節點就是取這k個”隱隱含層”節點輸出值中最大的那個值。因為激發函式中有了max操作,所以整個maxout網路也是一種非線性的變換。因此當我們看到常規結構的神經網路時,如果它使用了maxout激發,則我們頭腦中應該自動將這個”隱隱含層”節點加入。參考
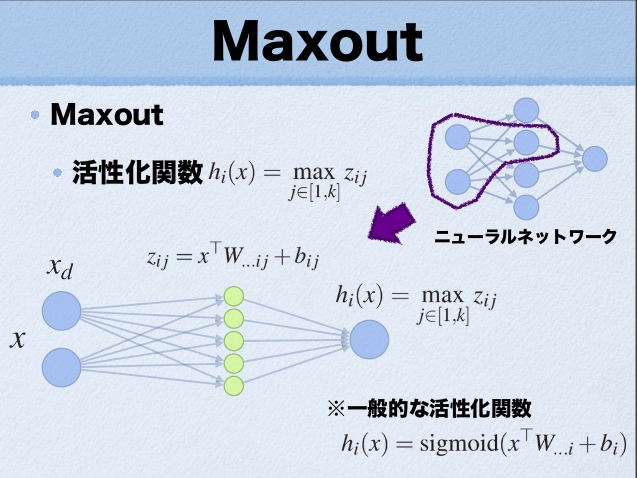
ppt中箭頭前後示意圖大家應該可以明白什麼是maxout激發函數了。
maxout的擬合能力是非常強的,它可以擬合任意的的凸函式。最直觀的解釋就是任意的凸函式都可以由分段線性函式以任意精度擬合(學過高等數學應該能明白),而maxout又是取k個隱隱含層節點的最大值,這些”隱隱含層"節點也是線性的,所以在不同的取值範圍下,最大值也可以看做是分段線性的(分段的個數與k值有關)。論文中的圖1如下(它表達的意思就是可以擬合任意凸函式,當然也包括了ReLU了):
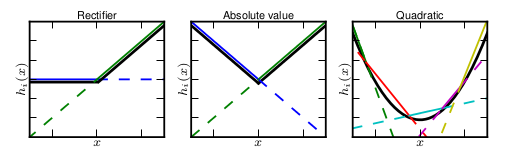
作者從數學的角度上也證明了這個結論,即只需2個maxout節點就可以擬合任意的凸函數了(相減),前提是”隱隱含層”節點的個數可以任意多,如下圖所示:
下面來看下maxout原始碼,看其激發函式表示式是否符合我們的理解。找到庫目錄下的pylearn2/models/maxout.py檔案,選擇不帶卷積的Maxout類,主要是其前向傳播函式fprop():
def fprop(self, state_below): #前向傳播,對linear分組進行max-pooling操作 self.input_space.validate(state_below)if self.requires_reformat: if not isinstance(state_below, tuple): for sb in get_debug_values(state_below): if sb.shape[0] != self.dbm.batch_size: raise ValueError("self.dbm.batch_size is %d but got shape of %d" % (self.dbm.batch_size, sb.shape[0])) assert reduce(lambda x,y: x * y, sb.shape[1:]) == self.input_dim state_below = self.input_space.format_as(state_below, self.desired_space) #統一好輸入資料的格式 z = self.transformer.lmul(state_below) + self.b # lmul()函式返回的是 return T.dot(x, self._W) if not hasattr(self, 'randomize_pools'): self.randomize_pools = False if not hasattr(self, 'pool_stride'): self.pool_stride = self.pool_size #預設情況下是沒有重疊的pooling if self.randomize_pools: z = T.dot(z, self.permute) if not hasattr(self, 'min_zero'): self.min_zero = False if self.min_zero: p = T.zeros_like(z) #返回一個和z同樣大小的矩陣,元素值為0,元素值型別和z的型別一樣 else: p = None last_start = self.detector_layer_dim - self.pool_size for i in xrange(self.pool_size): #xrange和reange的功能類似 cur = z[:,i:last_start+i+1:self.pool_stride] # L[start:end:step]是用來切片的,從[start,end)之間,每隔step取一次 if p is None: p = cur else: p = T.maximum(cur, p) #將p進行迭代比較,因為每次取的是每個group裡的元素,所以進行pool_size次後就可以獲得每個group的最大值 p.name = self.layer_name + '_p_' return p
仔細閱讀上面的原始碼,發現和文章中描述基本是一致的,只是多了很多細節。
由於沒有GPU,所以只用CPU 跑了個mnist的簡單實驗,參考:maxout下的readme檔案。(需先下載mnist dataset到PYLEARN2_DATA_PATA目錄下)。
執行../../train.py minist_pi.yaml
此時的.yaml配置檔案內容如下:
!obj:pylearn2.train.Train { dataset: &train !obj:pylearn2.datasets.mnist.MNIST { which_set: 'train', one_hot: 1, start: 0, stop: 50000 }, model: !obj:pylearn2.models.mlp.MLP { layers: [ !obj:pylearn2.models.maxout.Maxout { layer_name: 'h0', num_units: 240, num_pieces: 5, irange: .005, max_col_norm: 1.9365, }, !obj:pylearn2.models.maxout.Maxout { layer_name: 'h1', num_units: 240, num_pieces: 5, irange: .005, max_col_norm: 1.9365, }, !obj:pylearn2.models.mlp.Softmax { max_col_norm: 1.9365, layer_name: 'y', n_classes: 10, irange: .005 } ], nvis: 784, }, algorithm: !obj:pylearn2.training_algorithms.sgd.SGD { batch_size: 100, learning_rate: .1, learning_rule: !obj:pylearn2.training_algorithms.learning_rule.Momentum { init_momentum: .5, }, monitoring_dataset: { 'train' : *train, 'valid' : !obj:pylearn2.datasets.mnist.MNIST { which_set: 'train', one_hot: 1, start: 50000, stop: 60000 }, 'test' : !obj:pylearn2.datasets.mnist.MNIST { which_set: 'test', one_hot: 1, } }, cost: !obj:pylearn2.costs.mlp.dropout.Dropout { input_include_probs: { 'h0' : .8 }, input_scales: { 'h0': 1. } }, termination_criterion: !obj:pylearn2.termination_criteria.MonitorBased { channel_name: "valid_y_misclass", prop_decrease: 0., N: 100 }, update_callbacks: !obj:pylearn2.training_algorithms.sgd.ExponentialDecay { decay_factor: 1.000004, min_lr: .000001 } }, extensions: [ !obj:pylearn2.train_extensions.best_params.MonitorBasedSaveBest { channel_name: 'valid_y_misclass', save_path: "${PYLEARN2_TRAIN_FILE_FULL_STEM}_best.pkl" }, !obj:pylearn2.training_algorithms.learning_rule.MomentumAdjustor { start: 1, saturate: 250, final_momentum: .7 } ], save_path: "${PYLEARN2_TRAIN_FILE_FULL_STEM}.pkl", save_freq: 1 }
跑了一個晚上才迭代了210次,被我kill掉了(筆記本還得拿到別的地方幹活),這時的誤差率為1.22%。估計繼續跑幾個小時應該會降到作者的0.94%誤差率。
其monitor監控輸出結果如下:
Monitoring step: Epochs seen: 210 Batches seen: 105000 Examples seen: 10500000 learning_rate: 0.0657047371741 momentum: 0.667871485944 monitor_seconds_per_epoch: 121.0 test_h0_col_norms_max: 1.9364999 test_h0_col_norms_mean: 1.09864382902 test_h0_col_norms_min: 0.0935518826938 test_h0_p_max_x.max_u: 3.97355476543 test_h0_p_max_x.mean_u: 2.14463905251 test_h0_p_max_x.min_u: 0.961549570265 test_h0_p_mean_x.max_u: 0.878285389379 test_h0_p_mean_x.mean_u: 0.131020009421 test_h0_p_mean_x.min_u: -0.373017504665 test_h0_p_min_x.max_u: -0.202480633479 test_h0_p_min_x.mean_u: -1.31821964107 test_h0_p_min_x.min_u: -2.52428183099 test_h0_p_range_x.max_u: 5.56309069078 test_h0_p_range_x.mean_u: 3.46285869357 test_h0_p_range_x.min_u: 2.01775637301 test_h0_row_norms_max: 2.67556467 test_h0_row_norms_mean: 1.15743973628 test_h0_row_norms_min: 0.0951322935423 test_h1_col_norms_max: 1.12119975186 test_h1_col_norms_mean: 0.595629304226 test_h1_col_norms_min: 0.183531862659 test_h1_p_max_x.max_u: 6.42944749321 test_h1_p_max_x.mean_u: 3.74599401756 test_h1_p_max_x.min_u: 2.03028191814 test_h1_p_mean_x.max_u: 1.38424650414 test_h1_p_mean_x.mean_u: 0.583690886644 test_h1_p_mean_x.min_u: 0.0253866100292 test_h1_p_min_x.max_u: -0.830110300894 test_h1_p_min_x.mean_u: -1.73539242398 test_h1_p_min_x.min_u: -3.03677525979 test_h1_p_range_x.max_u: 8.63650239768 test_h1_p_range_x.mean_u: 5.48138644154 test_h1_p_range_x.min_u: 3.36428499068 test_h1_row_norms_max: 1.95904749183 test_h1_row_norms_mean: 1.40561339238 test_h1_row_norms_min: 1.16953677471 test_objective: 0.0959691806325 test_y_col_norms_max: 1.93642459019 test_y_col_norms_mean: 1.90996961714 test_y_col_norms_min: 1.88659811751 test_y_max_max_class: 1.0 test_y_mean_max_class: 0.996910632311 test_y_min_max_class: 0.824416386342 test_y_misclass: 0.0114 test_y_nll: 0.0609837733094 test_y_row_norms_max: 0.536167736581 test_y_row_norms_mean: 0.386866656967 test_y_row_norms_min: 0.266996530755 train_h0_col_norms_max: 1.9364999 train_h0_col_norms_mean: 1.09864382902 train_h0_col_norms_min: 0.0935518826938 train_h0_p_max_x.max_u: 3.98463017313 train_h0_p_max_x.mean_u: 2.16546276053 train_h0_p_max_x.min_u: 0.986865505974 train_h0_p_mean_x.max_u: 0.850944629066 train_h0_p_mean_x.mean_u: 0.135825383808 train_h0_p_mean_x.min_u: -0.354841456 train_h0_p_min_x.max_u: -0.20750516843 train_h0_p_min_x.mean_u: -1.32748375925 train_h0_p_min_x.min_u: -2.49716541111 train_h0_p_range_x.max_u: 5.61263186775 train_h0_p_range_x.mean_u: 3.49294651978 train_h0_p_range_x.min_u: 2.07324073262 train_h0_row_norms_max: 2.67556467 train_h0_row_norms_mean: 1.15743973628 train_h0_row_norms_min: 0.0951322935423 train_h1_col_norms_max: 1.12119975186 train_h1_col_norms_mean: 0.595629304226 train_h1_col_norms_min: 0.183531862659 train_h1_p_max_x.max_u: 6.49689754011 train_h1_p_max_x.mean_u: 3.77637040198 train_h1_p_max_x.min_u: 2.03274038543 train_h1_p_mean_x.max_u: 1.34966894021 train_h1_p_mean_x.mean_u: 0.57555584546 train_h1_p_mean_x.min_u: 0.0176827309146 train_h1_p_min_x.max_u: -0.845786992369 train_h1_p_min_x.mean_u: -1.74696425227 train_h1_p_min_x.min_u: -3.05703072635 train_h1_p_range_x.max_u: 8.73556577905 train_h1_p_range_x.mean_u: 5.52333465425 train_h1_p_range_x.min_u: 3.379501944 train_h1_row_norms_max: 1.95904749183 train_h1_row_norms_mean: 1.40561339238 train_h1_row_norms_min: 1.16953677471 train_objective: 0.0119584870103 train_y_col_norms_max: 1.93642459019 train_y_col_norms_mean: 1.90996961714 train_y_col_norms_min: 1.88659811751 train_y_max_max_class: 1.0 train_y_mean_max_class: 0.999958965285 train_y_min_max_class: 0.996295480193 train_y_misclass: 0.0 train_y_nll: 4.22109408992e-05 train_y_row_norms_max: 0.536167736581 train_y_row_norms_mean: 0.386866656967 train_y_row_norms_min: 0.266996530755 valid_h0_col_norms_max: 1.9364999 valid_h0_col_norms_mean: 1.09864382902 valid_h0_col_norms_min: 0.0935518826938 valid_h0_p_max_x.max_u: 3.970333514 valid_h0_p_max_x.mean_u: 2.15548653063 valid_h0_p_max_x.min_u: 0.99228626325 valid_h0_p_mean_x.max_u: 0.84583547397 valid_h0_p_mean_x.mean_u: 0.143554208322 valid_h0_p_mean_x.min_u: -0.349097300524 valid_h0_p_min_x.max_u: -0.218285757389 valid_h0_p_min_x.mean_u: -1.28008164111 valid_h0_p_min_x.min_u: -2.41494612443 valid_h0_p_range_x.max_u: 5.54136030367 valid_h0_p_range_x.mean_u: 3.43556817173 valid_h0_p_range_x.min_u: 2.03580165751 valid_h0_row_norms_max: 2.67556467 valid_h0_row_norms_mean: 1.15743973628 valid_h0_row_norms_min: 0.0951322935423 valid_h1_col_norms_max: 1.12119975186 valid_h1_col_norms_mean: 0.595629304226 valid_h1_col_norms_min: 0.183531862659 valid_h1_p_max_x.max_u: 6.4820340666 valid_h1_p_max_x.mean_u: 3.75160795812 valid_h1_p_max_x.min_u: 2.00587987424 valid_h1_p_mean_x.max_u: 1.38777592924 valid_h1_p_mean_x.mean_u: 0.578550013139 valid_h1_p_mean_x.min_u: 0.0232071426066 valid_h1_p_min_x.max_u: -0.84151110053 valid_h1_p_min_x.mean_u: -1.73734213646 valid_h1_p_min_x.min_u: -3.09680505839 valid_h1_p_range_x.max_u: 8.72732563235 valid_h1_p_range_x.mean_u: 5.48895009458 valid_h1_p_range_x.min_u: 3.32030803638 valid_h1_row_norms_max: 1.95904749183 valid_h1_row_norms_mean: 1.40561339238 valid_h1_row_norms_min: 1.16953677471 valid_objective: 0.104670540623 valid_y_col_norms_max: 1.93642459019 valid_y_col_norms_mean: 1.90996961714 valid_y_col_norms_min: 1.88659811751 valid_y_max_max_class: 1.0 valid_y_mean_max_class: 0.99627268242 valid_y_min_max_class: 0.767024730168 valid_y_misclass: 0.0122 valid_y_nll: 0.0682986195071 valid_y_row_norms_max: 0.536167736581 valid_y_row_norms_mean: 0.38686665696 valid_y_row_norms_min: 0.266996530755 Saving to mnist_pi.pkl... Saving to mnist_pi.pkl done. Time elapsed: 3.000000 seconds Time this epoch: 0:02:08.747395
參考資料:
Maxout Networks. Ian J. Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio
相關推薦
Deep learning:四十五(maxout簡單理解)
maxout出現在ICML2013上,作者Goodfellow將maxout和dropout結合後,號稱在MNIST, CIFAR-10, CIFAR-100, SVHN這4個數據上都取得了start-of-art的識別率。 從論文中可以看出,maxout其實一種激發函式形式。通常情況下,如果激
Deep learning:四十一(Dropout簡單理解)
前言 訓練神經網路模型時,如果訓練樣本較少,為了防止模型過擬合,Dropout可以作為一種trikc供選擇。Dropout是hintion最近2年提出的,源於其文章Improving neural networks by preventing co-adaptation of feature d
Deep learning:四十(龍星計劃2013深度學習課程小總結)
頭腦一熱,坐幾十個小時的硬座北上去天津大學去聽了門4天的深度學習課程,課程預先的計劃內容見:http://cs.tju.edu.cn/web/courseIntro.html。上課老師為微軟研究院的大牛——鄧力,群(qq群介紹見:Deep learning高質量交流群)裡
Deep learning系列(十五)有監督和無監督訓練
1. 前言 在學習深度學習的過程中,主要參考了四份資料: 對比過這幾份資料,突然間產生一個困惑:臺大和Andrew的教程中用了很大的篇幅介紹了無監督的自編碼神經網路,但在Li feifei的教程和caffe的實現中幾乎沒有涉及。當時一直搞不清這種現象的原
Deep learning:五十一(CNN的反向求導及練習)
前言: CNN作為DL中最成功的模型之一,有必要對其更進一步研究它。雖然在前面的博文Stacked CNN簡單介紹中有大概介紹過CNN的使用,不過那是有個前提的:CNN中的引數必須已提前學習好。而本文的主要目的是介紹CNN引數在使用bp演算法時該怎麼訓練,畢竟CNN中有卷積層和下采樣層,雖然
Deep learning:十九(RBM簡單理解)
這篇部落格主要用來簡單介紹下RBM網路,因為deep learning中的一個重要網路結構DBN就可以由RBM網路疊加而成,所以對RBM的理解有利於我們對DBN演算法以及deep learning演算法的進一步理解。Deep learning是從06年開始火得,得益於大牛Hinton的文章,不過這位大牛的
Android項目實戰(四十五):Usb轉串口通訊(CH34xUARTDriver)
spa config 關於 截取 文章 www protect sed bytes 需求為:手機usb接口插入一個硬件,從硬件上獲取數據 例如:手機usb插入硬件A,A通過藍牙通訊獲取設備a、b的數據,作為中轉站(可以做些數據處理)將數據(設備a、b產生的)傳給手機程序。
第四十五篇 入門機器學習——數據加載和簡單的數據探索
com 矩陣 desc ica 花瓣 入門機器學習 data 類別 機器學習 No.1. 導入相關類庫,並加載鳶尾花數據集 No.2. 這個鳶尾花數據集類似於一個字典,可以查看都有哪些鍵 No.3. ‘DESCR‘這個鍵對應的值為鳶尾花數據集的文檔,簡單
Java基礎系列(四十五):集合之Map
簡介 Map是一個介面,代表的是將鍵對映到值的物件。一個對映不能包含重複的鍵,每個鍵最多隻能對映到一個值。 Map 介面提供了三種collection檢視,允許以鍵集、值集或鍵-值對映關係集的形式檢視某個對映的內容。對映順序 定義為迭代器在對映的 collection 檢視上返回
【跟我學oracle18c】第四十五天:2 Day DBA:10.2 Diagnosing Performance Problems Using ADDM
10.2 Diagnosing Performance Problems Using ADDM At times, database performance problems arise that require your diagnosis and correction. Usual
“全棧2019”Java第四十五章:super關鍵字
難度 初級 學習時間 10分鐘 適合人群 零基礎 開發語言 Java 開發環境 JDK v11 IntelliJ IDEA v2018.3 文章原文連結 “全棧2019”Java第四十五章:super關鍵字 下一章 “全
思考(四十五):一種通用郵件服務SDK的實現方法
SDK 製作思路 SDK 不干涉使用方使用什麼網路模組、協議 SDK 不干涉使用方伺服器組內部架構 使用方只需要關注 SDK 介面用法,不需要關注 SDK 內部郵件協議、格式 Client SDK
反轉字元中的母音字母c語言(leetcode簡單篇三百四十五題)
編寫一個函式,以字串作為輸入,反轉該字串中的母音字母。 示例 1: 輸入: “hello” 輸出: “holle” 示例 2: 輸入: “leetcode” 輸出: “leotcede” 使用雙指標遍歷一遍即可 bool checkchar
第四十五章:專案架構的演變歷史
架構演進過程 純單機版架構 Maven依賴分層單機版架構 WebService服務呼叫分散式架構 CXF框架/HttpClient RESTTemplate Dubbo+ZooKeeper
第四十五篇:ReactiveCocoaObjC使用
引導:首先如果要使用 ReactiveCocoaObjC 第三方框架就先需要匯入該框架,我匯入時使用了 cocoapods 匯入的,在 podfile 檔案中輸入以下的內空: use_frameworks! target 'ReactiveCocoaDo
Web前端面試指導(四十五):頁面渲染原理是什麼?
題目點評 這是一道純理論的題目,只要能夠將瀏覽器的渲染過程很專業的表述出來,一定會得到面試官的青睞,作為一枚前端人員確實有必要了解一下瀏覽器的渲染過程是怎樣的,對於頁面效能的提升是有幫助的。 解題思路 渲染引擎是幹什麼的 渲染引擎可以顯示html、xml文件及圖片,它也可以
性能測試四十五:性能測試策略
out 開始 wait 需要 查看數據庫 結束 自己 count eno 1、項目具體需求,及業務場景:關註真實用戶會是怎樣的一個業務場景,確定用戶的用戶習慣。 2、指標:響應時間在多少以內,並發數多少,tps多少,總tps多少,穩定性交易總量多少,事務成功率,交易波動範圍
論文閱讀筆記四十五:Region Proposal by Guided Anchoring(CVPR2019)
分類 cascade 忽略 出了 advance ive 獲得 ams ons 論文原址:https://arxiv.org/abs/1901.03278 github:code will be available 摘要 區域anchor是現階段目標檢
JAVA學習第四十五課 — 其它對象API(一)System、Runtime、Math類
大整數 協調 1.5 tint ava 字符串 垃圾 void lol 一、System類 1. static long currentTimeMillis() 返回以毫秒為單位的當前時間。 實際上:當前時間與協調世界時 1970 年 1 月 1 日午夜之間的時間差(
Android Api Demos登頂之路(四十五)Loader-->Cursor
adapt lists 清空 function icon 創建 nal pat lines 這個demo演示了類載入器的用法。關於類載入器的使用我們在前面的demo中已經介紹過了 在此再小小的復習一下。類載入器的使用步驟: * 1.獲取類載入