
doc2vec原理及實踐
1.“句向量”簡介
word2vec提供了高質量的詞向量,並在一些任務中表現良好。
關於word2vec的原理可以參考這幾篇論文:
關於如何使用第三方庫gensim訓練word2vec可以參考這篇部落格:
儘管word2vec提供了高質量的詞彙向量,仍然沒有有效的方法將它們結合成一個高質量的文件向量。對於一個句子、文件或者說一個段落,怎麼把這些資料投影到向量空間中,並具有豐富的語義表達呢?過去人們常常使用以下幾種方法:
- bag of words
- LDA
- average word vectors
- tfidf-weighting word vectors
就bag of words而言,有如下缺點:1.沒有考慮到單詞的順序
average word vectors就是簡單的對句子中的所有詞向量取平均。是一種簡單有效的方法,但缺點也是沒有考慮到單詞的順序
tfidf-weighting word vectors是指對句子中的所有詞向量根據tfidf權重加權求和,是常用的一種計算sentence embedding的方法,在某些問題上表現很好,相比於簡單的對所有詞向量求平均,考慮到了tfidf權重,因此句子中更重要的詞佔得比重就更大。但缺點也是沒有考慮到單詞的順序
LDA模型當然就是計算出一片文件或者句子的主題分佈
2. doc2vec原理
Doc2Vec 或者叫做 paragraph2vec, sentence embeddings,是一種非監督式演算法,可以獲得 sentences/paragraphs/documents 的向量表達,是 word2vec 的拓展。學出來的向量可以通過計算距離來找 sentences/paragraphs/documents 之間的相似性,可以用於文字聚類,對於有標籤的資料,還可以用監督學習的方法進行文字分類,例如經典的情感分析問題。
在介紹doc2vec原理之前,先簡單回顧下word2vec的原理
word2vec基本原理
熟悉word2vec的同學都知道,下圖是學習詞向量表達最經典的一幅圖。在下圖中,任務就是給定上下文,預測上下文的其他單詞。

其中,每個單詞都被對映到向量空間中,將上下文的詞向量級聯或者求和作為特徵,預測句子中的下一個單詞。一般地:給定如下訓練單詞序列w1,w2,w3,...,wT, 目標函式是
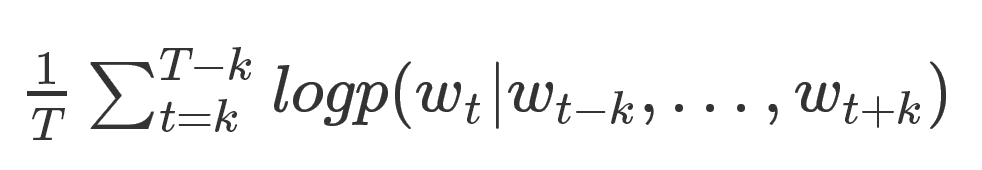
當然,預測的任務是一個多分類問題,分類器最後一層使用softmax,計算公式如下:
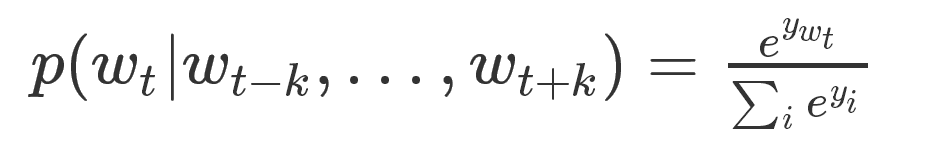
這裡的每一個yi可以理解為預測出每個word的概率。因為在該任務中,每個詞就可以看成一個類別。計算yi的公式如下:
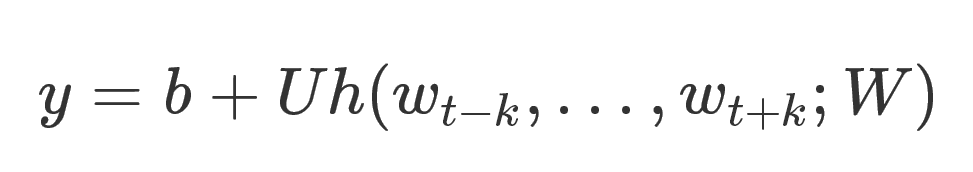
這裡U和b都是引數,h是將
因為每個單詞都是一類,所以類別眾多,在計算softmax歸一化的時候,效率很低。因此使用hierarical softmax加快計算速度,其實就是huffman樹,這個不再贅述,有興趣的同學可以看word2vec的paper。
doc2vec基本原理
1. A distributed memory model
訓練句向量的方法和詞向量的方法非常類似。訓練詞向量的核心思想就是說可以根據每個單詞wi的上下文預測wi,也就是說上下文的單詞對wi是有影響的。那麼同理,可以用同樣的方法訓練doc2vec。例如對於一個句子s:i want to drink water,如果要去預測句子中的單詞want,那麼不僅可以根據其他單詞生成feature, 也可以根據其他單詞和句子s來生成feature進行預測。因此doc2vec的框架如下所示:
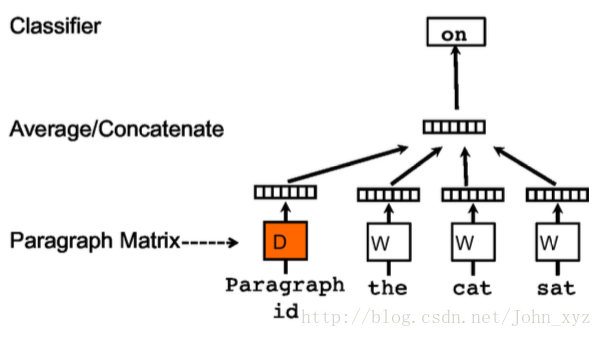
每個段落/句子都被對映到向量空間中,可以用矩陣D的一列來表示。每個單詞同樣被對映到向量空間,可以用矩陣W的一列來表示。然後將段落向量和詞向量級聯或者求平均得到特徵,預測句子中的下一個單詞。
這個段落向量/句向量也可以認為是一個單詞,它的作用相當於是上下文的記憶單元或者是這個段落的主題,所以我們一般叫這種訓練方法為Distributed Memory Model of Paragraph Vectors(PV-DM)
在訓練的時候我們固定上下文的長度,用滑動視窗的方法產生訓練集。段落向量/句向量 在該上下文中共享。
總結doc2vec的過程, 主要有兩步:
- 訓練模型,在已知的訓練資料中得到詞向量W, softmax的引數U和b,以及段落向量/句向量D
- 推斷過程(inference stage),對於新的段落,得到其向量表達。具體地,在矩陣DD中新增更多的列,在固定W,U,b的情況下,利用上述方法進行訓練,使用梯度下降的方法得到新的D,從而得到新段落的向量表達
2. Paragraph Vector without word ordering: Distributed bag of words
還有一種訓練方法是忽略輸入的上下文,讓模型去預測段落中的隨機一個單詞。就是在每次迭代的時候,從文字中取樣得到一個視窗,再從這個視窗中隨機取樣一個單詞作為預測任務,讓模型去預測,輸入就是段落向量。如下所示:
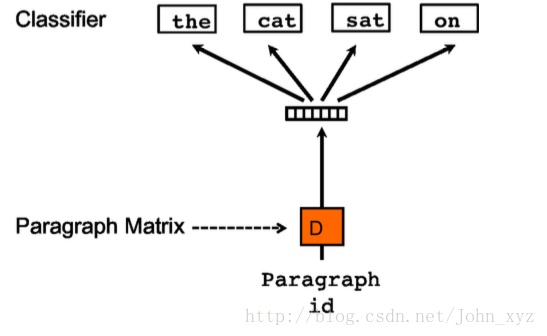
我們稱這種模型為 Distributed Bag of Words version of Paragraph Vector(PV-DBOW)
在上述兩種方法中,我們可以使用PV-DM或者PV-DBOW得到段落向量/句向量。對於大多數任務,PV-DM的方法表現很好,但我們也強烈推薦兩種方法相結合。
3. 基於gensim的doc2vec實踐
我們使用第三方庫gensim進行doc2vec模型的訓練
# -*- coding: utf-8 -*-
import sys
import logging
import os
import gensim
# 引入doc2vec
from gensim.models import Doc2Vec
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(curPath)[0]
sys.path.append(rootPath)
from utilties import ko_title2words
# 引入日誌配置
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 載入資料
documents = []
# 使用count當做每個句子的“標籤”,標籤和每個句子是一一對應的
count = 0
with open('../data/titles/ko.video.corpus','r') as f:
for line in f:
title = unicode(line, 'utf-8')
# 切詞,返回的結果是列表型別
words = ko_title2words(title)
# 這裡documents裡的每個元素是二元組,具體可以檢視函式文件
documents.append(gensim.models.doc2vec.TaggedDocument(words, [str(count)]))
count += 1
if count % 10000 == 0:
logging.info('{} has loaded...'.format(count))
# 模型訓練
model = Doc2Vec(documents, dm=1, size=100, window=8, min_count=5, workers=4)
# 儲存模型
model.save('models/ko_d2v.model')接下來看看訓練好的模型可以做什麼
def test_doc2vec():
# 載入模型
model = doc2vec.Doc2Vec.load('models/ko_d2v.model')
# 與標籤‘0’最相似的
print(model.docvecs.most_similar('0'))
# 進行相關性比較
print(model.docvecs.similarity('0','1'))
# 輸出標籤為‘10’句子的向量
print(model.docvecs['10'])
# 也可以推斷一個句向量(未出現在語料中)
words = u"여기 나오는 팀 다 가슴"
print(model.infer_vector(words.split()))
# 也可以輸出詞向量
print(model[u'가슴'])相關推薦
doc2vec原理及實踐
1.“句向量”簡介word2vec提供了高質量的詞向量,並在一些任務中表現良好。 關於word2vec的原理可以參考這幾篇論文:關於如何使用第三方庫gensim訓練word2vec可以參考這篇部落格:儘管word2vec提供了高質量的詞彙向量,仍然沒有有效的方法將它們結合成一
TensorFlow conv2d原理及實踐
滿足 一個 htm batch padding data xxx pad overflow tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name
學一點 mysql 雙機異地熱備份----快速理解mysql主從,主主備份原理及實踐
server counter ror 位置 正在 大型 主循環 備份 配置詳解 雙機熱備的概念簡單說一下,就是要保持兩個數據庫的狀態自動同步。對任何一個數據庫的操作都自動應用到另外一個數據庫,始終保持兩個數據庫數據一致。 這樣做的好處多。 1. 可以做災備,其中一個壞了可
https原理及實踐
ron 普通 erl key 配置 獲取 blog 種類型 uil 轉自 https://www.cnblogs.com/lyq863987322/p/8424253.html 作者 酷酷的二連長 目錄 網絡安全問題 數據機密性 數據完整性 身份驗證 網絡
MySQL主從復制原理及實踐
MySQL 主從復制 原理 實踐 第1章 MySQL的主從復制介紹MySQL的主從復制方案,和上述文件及文件系統級別同步是類似的,都是數據的傳輸。只不過MySQL無需借助第三方工具,而是其自帶的同步復制功能。另外一點,MySQL的主從復制並不是磁盤上文件直接同步,而是邏輯的binlog日誌同步
單臂路由原理及實踐
實驗 sha conf term 劃分 dot per 單臂路由 shu 單臂路由單臂路由(router-on-a-stick)是指在路由器的一個接口上通過配置子接口(或“邏輯接口”,並不存在真正物理接口)的方式,實現原來相互隔離的不同VLAN(虛擬局域網)之間的互聯互通。
0day安全:軟體漏洞分析技術 第二章 棧溢位原理及實踐
_stdcall呼叫約定下,函式呼叫時用到的指令序列大致如下:push 引數3push 引數2push 引數1call 函式地址;a)向棧中壓入當前指令在記憶體中的位置,即儲存儲存返回地址。b)跳轉到所呼叫函式的入口push ebp 儲存舊棧幀的底部mov ebp,esp 設定新棧幀的底部(棧幀切換)sub
(一)因式分解機(Factorization Machine,FM)原理及實踐
因子分解機(Factorization Machine),是由Konstanz大學(德國康斯坦茨大學)Steffen Rendle(現任職於Google)於2010年最早提出的,旨在解決大規模稀疏資料下的特徵組合問題。原論文見此。 不久後,FM的升級版模型場感知分解機(Field-awa
深入學習Redis高可用架構:哨兵原理及實踐
在進入正文之前,順便在此給大家推薦一個Java架構方面的交流學習群:698581634,裡面會分享一些資深架構師錄製的視訊錄影:有Spring,MyBatis,Netty原始碼分析,高併發、高效能、分散式、微服務架構的原理,JVM效能優化這些成為架構師必備的知識體系,
達觀資料王江:fastText原理及實踐
fastText是Facebook於2016年開源的一個詞向量計算和文字分類工具,在學術上並沒有太大創新。但是它的優點也非常明顯,在文字分類任務中,fastText(淺層網路)往往能取得和深度網路相媲美的精度,卻在訓練時間上比深度網路快許多數量級。在標準的多核CPU上, 能夠訓練10億詞級
編譯原理及實踐-----詞法分析
詞法分析 【實驗目的】 通過設計編制除錯一個具體的詞法分析程式,加深對詞法分析原理的理解。並掌握在對程式設計語言源程式進行掃描過程中將其分解為各類單詞的詞法分析方法。掌握對字元進行靈活處理的方法。 程式開始變得複雜起來,可能是大家目前編過的程式中最複雜
IM開發基礎知識補課(三):快速理解服務端資料庫讀寫分離原理及實踐建議
1、前言 IM應用從服務端資料的角度來看,它是一種很特殊的應用場景,拋開基礎資料、增值業務和附屬功能不談,單從IM聊天工具的立身之本——聊天資料來說,理論上是不需要在服務端儲存的(或者說只需要短暫儲存——比如離線訊息,上線即拉走),這也是為什麼微信在前段時間號稱絕不儲存使用
Spark基本原理概念 以及 spark streaming 核心原理及實踐
導語 spark 已經成為廣告、報表以及推薦系統等大資料計算場景中首選系統,因效率高,易用以及通用性越來越得到大家的青睞,我自己最近半年在接觸spark以及spark streaming之後,對spark技術的使用有一些自己的經驗積累以及心得體會,在此分享給大家。 本文依次從spark生態,
深入解析SQL Server並行執行原理及實踐(上)
在成熟領先的企業級資料庫系統中,並行查詢可以說是一大利器,在某些場景下它可以顯著地提升查詢的相應時間,提升使用者體驗。如SQL Server、Oracle等, MySQL目前還未實現,而PostgreSQL在2015實現了並行掃描,相信他們也在朝著更健壯的企業級資料庫邁進。RDBMS中並行執行的實現
K-mean原理及實踐(K值確定)
kmeans一般在資料分析前期使用,選取適當的k,將資料聚類後,然後研究不同聚類下資料的特點。 演算法原理: (1) 隨機選取k箇中心點; (2) 在第j次迭代中,對於每個樣本點,選取最近的中心點,歸為該類; (3) 更新中心點為每類的均值; (4) j<
機器學習筆記(七)Boost演算法(GDBT,AdaBoost,XGBoost)原理及實踐
在上一篇部落格裡,我們討論了關於Bagging的內容,其原理是從現有資料中有放回抽取若干個樣本構建分類器,重複若干次建立若干個分類器進行投票,今天我們來討論另一種演算法:提升(Boost)。 簡單地來
C#資料庫事務原理及實踐
什麼是資料庫事務 資料庫事務是指作為單個邏輯工作單元執行的一系列操作。設想網上購物的一次交易,其付款過程至少包括以下幾步資料庫操作:· 更新客戶所購商品的庫存資訊· 儲存客戶付款資訊--可能包括與銀行系統的互動· 生成訂單並且儲存到資料庫中· 更新使用者相關資訊,例如購物數量等等正常的情況下,這些操
C#資料庫事務原理及實踐(下)
另一個走向極端的錯誤 滿懷信心的新手們可能為自己所掌握的部分知識陶醉不已,剛接觸資料庫庫事務處理的準開發者們也一樣,躊躇滿志地準備將事務機制應用到他的資料處理程式的每一個模組每一條語句中去。的確,事務機制看起來是如此的誘人——簡潔、美妙而又實用,我當然想用它來避免一切可能
MySQL資料複製原理及實踐
1.資料複製概述 1.1資料複製定義 資料複製使一個服務上的資料與另一個服務上資料保持同步 1.2複製用途 資料分佈 負載均衡 備份 高可用和故障切換 MySQL升級測試 2.資料複製工作原理 2.1複製工作流程介紹(以主從架構為例) MySQL複製原理比較
mysql 雙機異地熱備份----快速理解mysql主從,主主備份原理及實踐
雙機熱備的概念簡單說一下,就是要保持兩個資料庫的狀態自動同步。對任何一個數據庫的操作都自動應用到另外一個數據庫,始終保持兩個資料庫資料一致。 這樣做的好處多。 1. 可以做災備,其中一個壞了可以切換到另一個。 2. 可以做負載均衡,可以將請求分攤到其中任何一臺上,提高網站