
03 二八原則:有針對性地處理好系統的“熱點資料”
假設你的系統中儲存有幾十億上百億的商品,而每天有千萬級的商品被上億的使用者訪問,那麼肯定有一部分被大量使用者訪問的熱賣商品,這就是我們常說的“熱點商品”。
這些熱點商品中最極端的例子就是秒殺商品,它們在很短時間內被大量使用者執行訪問、新增購物車、下單等操作,這些操作我們就稱為“熱點操作”。那麼問題來了:這些熱點對系統有啥影響,我們非要關注這些熱點嗎?
為什麼要關注熱點
我們一定要關注熱點,因為熱點會對系統產生一系列的影響。
首先,熱點請求會大量佔用伺服器處理資源,雖然這個熱點可能只佔請求總量的億分之一,然而卻可能搶佔90%的伺服器資源,如果這個熱點請求還是沒有價值的無效請求,那麼對系統資源來說完全是浪費。
其次,即使這些熱點是有效的請求,我們也要識別出來做針對性的優化,從而用更低的代價來支撐這些熱點請求。
既然熱點對系統來說這麼重要,那麼熱點到底包含哪些內容呢?
什麼是“熱點”
熱點分為熱點操作和熱點資料。
所謂“熱點操作”,例如大量的重新整理頁面、大量的新增購物車、雙十一零點大量的下單等都屬於此類操作。對系統來說,這些操作可以抽象為“讀請求”和“寫請求”,這兩種熱點請求的處理方式大相徑庭,讀請求的優化空間要大一些,而寫請求的瓶頸一般都在儲存層,優化的思路就是根據CAP理論做平衡,這個內容我在“減庫存”一文再詳細介紹。
而“熱點資料”比較好理解,那就是使用者的熱點請求對應的資料。而熱點資料又分為“靜態熱點資料”和“動態熱點資料
所謂“靜態熱點資料”,就是能夠提前預測的熱點資料。例如,我們可以通過賣家報名的方式提前篩選出來,通過報名系統對這些熱點商品進行打標。另外,我們還可以通過大資料分析來提前發現熱點商品,比如我們分析歷史成交記錄、使用者的購物車記錄,來發現哪些商品可能更熱門、更好賣,這些都是可以提前分析出來的熱點。
所謂“動態熱點資料”,就是不能被提前預測到的,系統在執行過程中臨時產生的熱點。例如,賣家在抖音上做了廣告,然後商品一下就火了,導致它在短時間內被大量購買。
由於熱點操作是使用者的行為,我們不好改變,但能做一些限制和保護,所以本文我主要針對熱點資料來介紹如何進行優化。
發現熱點資料
前面,我介紹瞭如何對單個秒殺商品的頁面資料進行動靜分離,以便針對性地對靜態資料做優化處理,那麼另外一個關鍵的問題來了:如何發現這些秒殺商品,或者更準確地說,如何發現熱點商品呢?
你可能會說“參加秒殺的商品就是秒殺商品啊”,沒錯,關鍵是系統怎麼知道哪些商品參加了秒殺活動呢?所以,你要有一個機制提前來區分普通商品和秒殺商品。
我們從發現靜態熱點和發現動態熱點兩個方面來看一下。
發現靜態熱點資料
如前面講的,靜態熱點資料可以通過商業手段,例如強制讓賣家通過報名參加的方式提前把熱點商品篩選出來,實現方式是通過一個運營系統,把參加活動的商品資料進行打標,然後通過一個後臺系統對這些熱點商品進行預處理,如提前進行快取。但是這種通過報名提前篩選的方式也會帶來新的問題,即增加賣家的使用成本,而且實時性較差,也不太靈活。
不過,除了提前報名篩選這種方式,你還可以通過技術手段提前預測,例如對買家每天訪問的商品進行大資料計算,然後統計出TOP N的商品,我們可以認為這些TOP N的商品就是熱點商品。
發現動態熱點資料
我們可以通過賣家報名或者大資料預測這些手段來提前預測靜態熱點資料,但這其中有一個痛點,就是實時性較差,如果我們的系統能在秒級內自動發現熱點商品那就完美了。
能夠動態地實時發現熱點不僅對秒殺商品,對其他熱賣商品也同樣有價值,所以我們需要想辦法實現熱點的動態發現功能。
這裡我給出一個動態熱點發現系統的具體實現。
- 構建一個非同步的系統,它可以收集交易鏈路上各個環節中的中介軟體產品的熱點Key,如Nginx、快取、RPC服務框架等這些中介軟體(一些中介軟體產品本身已經有熱點統計模組)。
- 建立一個熱點上報和可以按照需求訂閱的熱點服務的下發規範,主要目的是通過交易鏈路上各個系統(包括詳情、購物車、交易、優惠、庫存、物流等)訪問的時間差,把上游已經發現的熱點透傳給下游系統,提前做好保護。比如,對於大促高峰期,詳情繫統是最早知道的,在統一接入層上Nginx模組統計的熱點URL。
- 將上游系統收集的熱點資料傳送到熱點服務檯,然後下游系統(如交易系統)就會知道哪些商品會被頻繁呼叫,然後做熱點保護。
這裡我給出了一個圖,其中使用者訪問商品時經過的路徑有很多,我們主要是依賴前面的導購頁面(包括首頁、搜尋頁面、商品詳情、購物車等)提前識別哪些商品的訪問量高,通過這些系統中的中介軟體來收集熱點資料,並記錄到日誌中。
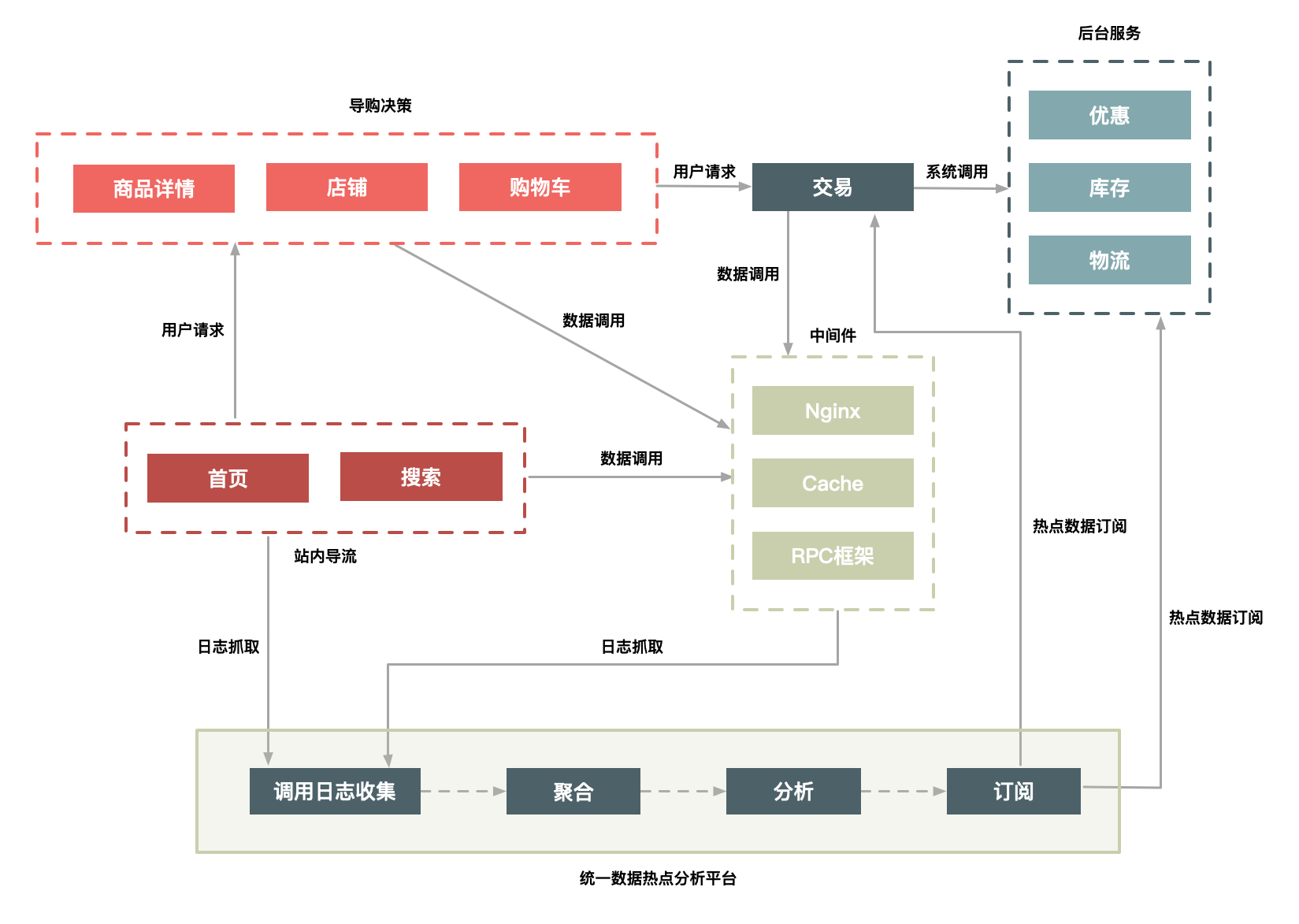
圖1 一個動態熱點發現系統
我們通過部署在每臺機器上的Agent把日誌彙總到聚合和分析叢集中,然後把符合一定規則的熱點資料,通過訂閱分發系統再推送到相應的系統中。你可以是把熱點資料填充到Cache中,或者直接推送到應用伺服器的記憶體中,還可以對這些資料進行攔截,總之下游系統可以訂閱這些資料,然後根據自己的需求決定如何處理這些資料。
打造熱點發現系統時,我根據以往經驗總結了幾點注意事項。
- 這個熱點服務後臺抓取熱點資料日誌最好採用非同步方式,因為“非同步”一方面便於保證通用性,另一方面又不影響業務系統和中介軟體產品的主流程。
- 熱點服務發現和中介軟體自身的熱點保護模組並存,每個中介軟體和應用還需要保護自己。熱點服務檯提供熱點資料的收集和訂閱服務,便於把各個系統的熱點資料透明出來。
- 熱點發現要做到接近實時(3s內完成熱點資料的發現),因為只有做到接近實時,動態發現才有意義,才能實時地對下游系統提供保護。
處理熱點資料
處理熱點資料通常有幾種思路:一是優化,二是限制,三是隔離。
先來說說優化。
優化熱點資料最有效的辦法就是快取熱點資料,如果熱點資料做了動靜分離,那麼可以長期快取靜態資料。但是,快取熱點資料更多的是“臨時”快取,即不管是靜態資料還是動態資料,都用一個佇列短暫地快取數秒鐘,由於佇列長度有限,可以採用LRU淘汰演算法替換。
再來說說限制。限制更多的是一種保護機制,限制的辦法也有很多,例如對被訪問商品的ID做一致性Hash,然後根據Hash做分桶,每個分桶設定一個處理佇列,這樣可以把熱點商品限制在一個請求佇列裡,防止因某些熱點商品佔用太多的伺服器資源,而使其他請求始終得不到伺服器的處理資源。
最後介紹一下隔離。秒殺系統設計的第一個原則就是將這種熱點資料隔離出來,不要讓1%的請求影響到另外的99%,隔離出來後也更方便對這1%的請求做針對性的優化。
具體到“秒殺”業務,我們可以在以下幾個層次實現隔離。
- 業務隔離。把秒殺做成一種營銷活動,賣家要參加秒殺這種營銷活動需要單獨報名,從技術上來說,賣家報名後對我們來說就有了已知熱點,因此可以提前做好預熱。
- 系統隔離。系統隔離更多的是執行時的隔離,可以通過分組部署的方式和另外99%分開。秒殺可以申請單獨的域名,目的也是讓請求落到不同的叢集中。
- 資料隔離。秒殺所呼叫的資料大部分都是熱點資料,比如會啟用單獨的Cache叢集或者MySQL資料庫來放熱點資料,目的也是不想0.01%的資料有機會影響99.99%資料。
當然了,實現隔離有很多種辦法。比如,你可以按照使用者來區分,給不同的使用者分配不同的Cookie,在接入層,路由到不同的服務介面中;
再比如,你還可以在接入層針對URL中的不同Path來設定限流策略。服務層呼叫不同的服務介面,以及資料層通過給資料打標來區分等等這些措施,其目的都是把已經識別出來的熱點請求和普通的請求區分開。
總結一下
本文與資料的動靜分離不一樣,它從另外一個維度對資料進行了區分處理。你要明白,區分的目的主要還是對讀熱點資料加以優化,對照“4要1不要”原則,它可以減少請求量,也可以減少請求的路徑。因為快取的資料都是經過多個請求,或者從多個系統中獲取的資料經過計算後的結果。
熱點的發現和隔離不僅對“秒殺”這個場景有意義,對其他的高效能分散式系統也非常有價值,尤其是熱點的隔離非常重要。我介紹了業務層面的隔離和資料層面的隔離方式,最重要最簡單的方式就是獨立出來一個叢集,單獨處理熱點資料。
但是能夠獨立出來一個叢集的前提還是首先能夠發現熱點,為此我介紹了發現熱點的幾種方式,比如人工標識、大資料統計計算,以及實時熱點發現方案,希望能夠給你啟發。
相關推薦
03 二八原則:有針對性地處理好系統的“熱點資料”
假設你的系統中儲存有幾十億上百億的商品,而每天有千萬級的商品被上億的使用者訪問,那麼肯定有一部分被大量使用者訪問的熱賣商品,這就是我們常說的“熱點商品”。 這些熱點商品中最極端的例子就是秒殺商品,它們在很短時間內被大量使用者執行訪問、新增購物車、下單等操作,這些
七個人生工具:SWOT、PDCA、6W2H、SMART、WBS、時間管理、二八原則
SWOT、PDCA、6W2H、SMART、WBS、時間管理、二八原則…認識這些詞語嘛?是不是感覺很眼熟?可是,它們到底代表什麼呢?是不是有點懵圈?沒關係,藉助以下簡短的介紹,你就可以快速瞭解這七大人生工具了。 1、SWOT分析法
思維邏輯分析相關理論支援:SWOT、PDCA、6W2H、SMART、WBS、時間管理、二八原則
一、SWOT分析法 Strengths:優勢 Weaknesses:劣勢 Opportunities:機會 Threats:威脅 人生工具:SWOT、PDCA、6W2H、SMART、WBS、時間管理、二八原則 意義:幫您清晰地把握全域性,分析自己在資
有針對性地提升技術團隊的技術能力
技術 能力提升 技術團隊 作為一個技術團隊的負責人,公司往往對其有“提升技術團隊技術能力”的期望。不同人對技術能力的評價標準是不一樣的。我們經常看到一些技術團隊的負責人覺得自己團隊的技術挺好的,但公司高層和其他部門對技術團隊的技術能力評價一般。作為技術團隊負責人,有必要了解,其“服務的客戶”(一般
【轉】編寫高質量代碼改善C#程序的157個建議——建議134:有條件地使用前綴
劃線 set 嘗試 開發 amp 保持 規則 bsp ask 建議134:有條件地使用前綴 在.NET的設計規範中,不建議使用前綴。但是,即便是微軟自己依然廣泛的使用這前綴。 最典型的前綴是m_,這種命名一方面是考慮到歷史沿革中的習慣問題,另一方面也許我們確實有必要這
二八原則的演算法
昨天公司老總要求按二八原則把佔公司銷量,收入以及利潤80%的車型統計出來,寫了個程式,原始碼如下: REPORT ZCALRATE .DATA: it_ztkcjg TYPE TABLE OF ztkcjg, wa_ztkcjg TYPE ztkcjg. INITI
效能測試理論之二八原則
企鵝交流群>79642549 在效能測試方法論中,很典型的方法就是二八原則,量化業務需求。 二八原則:指80%的業務量在20%的時間裡完成。 如何理解,下面我們來個例子吧 使用者登入場景:早高峰時段,8:50---9:10,5000坐席上線登陸。 業務
效能測試二八原則,響應時間2/5/8原則
所謂響應時間的“2-5-8原則”,簡單說,就是 當用戶能夠在2秒以內得到響應時,會感覺系統的響應很快; 當用戶在2-5秒之間得到響應時,會感覺系統的響應速度還可以; 當用戶在5-8秒以內得到響應時,會感覺系統的響應速度很慢,但是還可以接受; 而當用戶在超過8秒後仍
(七)二八原則
巴菲特定律:“總結果的80%是由總消耗時間的20%所形成的。” Examples: 80%的銷售額源自於20%的顧客。 80%的電話來自20%的朋友。 80%的總產量來自20%的產品。 80%的財富集中在20%的人手中。 這啟示我們要善於抓住主要矛盾
響應時間2/5/10原則 軟體測試2-8原則(2/8原則,二八原則)
在學習Loadrunner中,接觸到2/5/10原則。 所謂的“2-5-10原則”,就是 當用戶能夠在2秒以內得到響應時,會感覺系統的響應很快; 當用戶在2-5秒之間得到響應時,會感覺系統的響應速度還可以;
多方位全面解析:如何正確地寫好一個介面
寫介面可以說是每位移動應用開發者的基本功,也是一位合格移動應用開發者繞不過去的坎。但就如不是每一位開發者都能夠成為合格的開發者一樣,本人在不同的團隊中發現,甚少有人能夠編寫出合格的UI程式碼;而非常奇怪的是,在很多的開發者論壇上看到我們移動開發者更多關注於某個控制元件或者是動畫
一站式學習Wireshark(八):應用Wireshark過濾條件抓取特定資料流
應用抓包過濾,選擇Capture | Options,擴充套件視窗檢視到Capture Filter欄。雙擊選定的介面,如下圖所示,彈出Edit Interface Settints視窗。 下圖顯示了Edit Interface Settings視窗,這裡可以設定
從CES看PC趨勢:微信房卡二八杠棋牌源碼下載顯示器會更大
不同的 發的 棋牌 華碩 汽車 趨勢 第一次 合作 想要 2017年年末時,微信房卡二八杠棋牌源碼下載( h5.super-mans.com Q:2012035918)微信房卡二八杠棋牌源碼下載,這次合作史無前例。回看歷史,兩家公司爭鋒相對,現在卻握手言和,它們為獨立
資料結構——第三章樹和二叉樹:03樹和森林
1.樹的三種儲存結構: (1)雙親表示法: #define MAX_TREE_SIZE 100 結點結構: typedef struct PTNode { Elem data; int parent; //雙親位置域 } PTNode; (2)孩子雙親連結串列表示法: &nbs
tensorflow學習筆記(二十八):collection tensorflow學習筆記(二十八):collection
tensorflow學習筆記(二十八):collection 2016年12月27日 11:53:06 閱讀數:11346 tensorflow collection tensorflow的collection提供一個
ionic學習(八):問答社群03:註冊實現
1.生成註冊頁面: ionic g page register 2.將頁面新增到app.module.ts中 3.在登入頁面設定跳轉連結 .ts檔案中,先匯入頁面,再實現函式跳轉 4.做前端頁面 register.html程式碼如下: <ion-hea
Java併發(十八):阻塞佇列BlockingQueue BlockingQueue(阻塞佇列)詳解 二叉堆(一)之 圖文解析 和 C語言的實現 多執行緒程式設計:阻塞、併發佇列的使用總結 Java併發程式設計:阻塞佇列 java阻塞佇列 BlockingQueue(阻塞佇列)詳解
阻塞佇列(BlockingQueue)是一個支援兩個附加操作的佇列。 這兩個附加的操作是:在佇列為空時,獲取元素的執行緒會等待佇列變為非空。當佇列滿時,儲存元素的執行緒會等待佇列可用。 阻塞佇列常用於生產者和消費者的場景,生產者是往佇列裡新增元素的執行緒,消費者是從佇列裡拿元素的執行緒。阻塞佇列就是生產者
搭建自己的部落格(二十八):增加繫結郵箱的功能,完善使用者資訊
1、郵箱伺服器使用了騰訊伺服器 具體操作見:python自動發郵件 2、變化的部分 3、上程式碼: {# 引用模板 #} {% extends 'base.html' %} {% load staticfiles %} {% load comment_tags %}
Java併發(二十一):執行緒池實現原理 Java併發(十八):阻塞佇列BlockingQueue Java併發(十八):阻塞佇列BlockingQueue Java併發程式設計:執行緒池的使用
一、總覽 執行緒池類ThreadPoolExecutor的相關類需要先了解: (圖片來自:https://javadoop.com/post/java-thread-pool#%E6%80%BB%E8%A7%88) Executor:位於最頂層,只有一個 execute(Runnab
劍指offer第三十八題:二叉樹的深度
題目描述 輸入一棵二叉樹,求該樹的深度。從根結點到葉結點依次經過的結點(含根、葉結點)形成樹的一條路徑,最長路徑的長度為樹的深度。 思路:用遞迴,左右兩個子樹一直遞迴比較,取最大的值,就是深度。 程式碼: /* struct TreeNode { int val;