
深度學習系列(七):自編碼網路與PCA特徵學習的分類對比實驗
上節我們看到自編碼網路額隱含層可以用於原始資料的降維(其實也可以升維,不過把隱含層的單元設定的比輸入維度還要多),換而言之就是特徵學習,那麼學習到的這些特徵就可以用於分類了,本節主要試驗下這些特徵用於分類的效果。
先以最簡單的三層自編碼網路為例,先訓練自編碼網路,在得到編碼權值矩陣後,在後接SVM分類器,抽象出來就是如下兩個步驟:
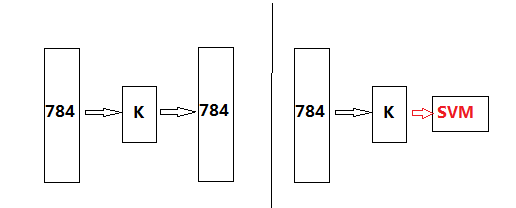
這裡我們不斷調整隱含層單元個數K,並觀察最終的分類準確率。
Ok第一步是自編碼學習,部分程式碼如下:
%--------------添加當前資料夾-------------
%% addpath .\DeepLearnToolbox-master\.
currentFolder = pwd;
addpath(genpath(currentFolder))
% 首先設定好工具箱所有路徑,載入資料,選擇用於自編碼的樣本個數,確定網路結構,然後進行自編碼學習,關於deep_autocoderW函式如下:
function sae = deep_autocoderW(train_x,auto_net)
%% 規定每一層引數--需要修改的引數 在這個函式裡,我們要設定一些網路的引數,尤其是稀疏表示的引數設定、啟用函式的設定,等等,然互直接呼叫自編碼的訓練函式,就可以得到訓練好的網路。
訓練好了我們只是把自編碼網路訓練完了,那麼我們接下來就是要找到輸入經過隱含層的輸出是什麼?比如這裡784維輸入經過隱含層會輸出K=100維的資料(也就是降維資料,也就是特徵提取資料)。很簡單就是將784維資料依次乘以編碼網路的權值引數即可。接著上面的程式碼往下提取這100維特徵資料:
%% 重新選擇分類需要的訓練資料與測試資料
num_train = 5000;
train_x = double(train_x(1:num_train,:))/255;
train_y = double(train_y(1:num_train,:));
num_test= 5000;
test_x = double(test_x(1:choose_num_test,:))/255;
test_y = double(test_y(1:choose_num_test,:));
%% 根據自編碼網路提取特徵
data_train_feature = deep_feature_data(sae,train_x);
data_test_feature = deep_feature_data(sae,test_x);
data_train = data_train_feature{1};
data_test = data_test_feature{1};這裡呼叫了一個函式deep_feature_data,這個函式就是獲得降維的資料的,具體如下:
function data_feature = deep_feature_data(sae,data)
%% 使用自編碼權值計算每一層的特徵
data_feature{1} = data;
for i = 1:(numel(sae.ae))
if i == 1
data_temp = [ones(size(data,1),1),data];%加入常數項到輸入中
data_feature{1} = sigm(data_temp * (sae.ae{1}.W{1})');%2:end 為權值
else
data_feature_temp = [ones(size(data_feature{i-1},1),1),...
data_feature{i-1}];
data_feature{i} = sigm(data_feature_temp * (sae.ae{i}.W{1})');
end
end這裡可以看到某一層的輸出就是其輸入乘以它連線著的權值引數。為什麼是data要變成data_temp呢?因為這個工具箱認為的自編碼網路每一層還有一個b值,如下所示:
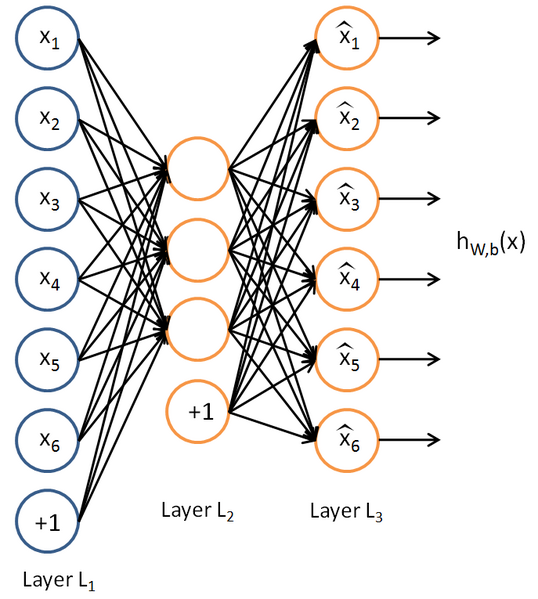
從圖上看我們可能認為這個常數1應該更在784維資料後面構成785維輸入,而我們是加在784維前面的構成785維輸入,這一點的判斷是從這個工具箱自帶的視覺化函式來的:
visualize(sae.ae{1}.W{1}(:,2:end)')%視覺化編碼矩陣的權值從這裡可以看出,出來的785維權值矩陣中2:end的這784維為輸入對應的權值,第一維自然是常數項對應的權值。這個函式後面還有個else,意思是假設這個網路不止三層的時候,每一層我們都計算一下它的特徵輸出,就好比下面這樣,計算經過200的特徵,以及經過K後的特徵,但是我們可能用的是K後的特徵去接SVM分類器,同時還需要注意的是我們需要使用啟用函式去處理一下,並且使用的是訓練網路的啟用函式,比如這裡是sigm,所以得到的特徵都要sigm一下才是我們最終用於輸入到SVM的特徵。
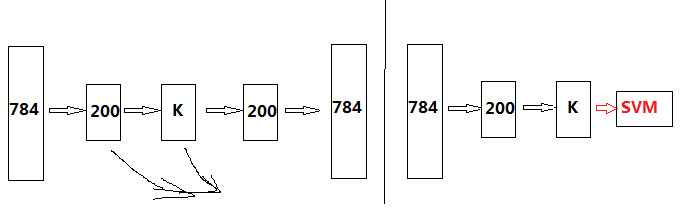
當然在這個三層中我們最終送入到SVM的就只有一個,經過K=100後的特徵,也就是
data_train = data_train_feature{1};
data_test = data_test_feature{1};至此我們可以開始第二步了,用這些特徵去訓練SVM分類器。在這裡再說一點,可能有人注意到,前面訓練自編碼的時候用了20000個訓練樣本,在訓練SVM時又選了5000個樣本訓練,5000個樣本測試,這裡要說的是,訓練自編碼的20000個樣本是用來訓練自編碼網路的,而在網路確定後,又用5000個樣本訓練的是SVM,這兩個訓練是不一樣的,獨立分開的。更多的時候,在深度學習領域裡面你會看到,其實前20000個樣本叫做網路的預訓練,而後5000個樣本可用於網路的微調引數,使得網路更準確。
ok緊接著上面的程式碼,加入SVM分類器,這裡使用的libSVM工具箱,關於該工具箱的使用, 可以看到
訓練svm以及測試的程式碼如下:
%% svm 訓練
[~,train_y] = max(train_y');
model = svmtrain(train_y',data_train,'-t 0');
%% svm 測試
[~,test_y] = max(test_y');
predict1 = svmpredict(ones(numel(test_y),1),data_test,model);
accurary = numel(find(predict1 == test_y'))/numel(test_y)
某一次的執行結果如下:
accurary =
0.9242可以看到5000個訓練樣本下5000個測試樣本的結果,而網路呢是在20000個樣本下自編碼得到的網路,這個網路我們也沒有進行在優化了,其實是可以在優化的,比如我們可以微調網路引數等等。
為了觀察不同的K下試驗的效果如何,這裡我們設定不同的K值,其他不變進行重複的實驗如下:
%--------------添加當前資料夾-------------
%% addpath .\DeepLearnToolbox-master\.
clc
clear
currentFolder = pwd;
addpath(genpath(currentFolder))
K = [10,20,30,40,50,60,70,80,90,100,110,120,130,140,150];
for i = 1:15
%% 選擇樣本
load mnist_uint8;
%% 規定自編碼權值
choose_num_train = 20000;
train = double(train_x(1:choose_num_train,:))/255;
auto_net = [784 K(i)];
sae = deep_autocoderW(train,auto_net);
%%
num_train = 5000;
train_x = double(train_x(1:num_train,:))/255;
train_y = double(train_y(1:num_train,:));
num_test= 5000;
test_x = double(test_x(1:num_test,:))/255;
test_y = double(test_y(1:num_test,:));
%%
data_train_feature = deep_feature_data(sae,train_x);
data_test_feature = deep_feature_data(sae,test_x);
data_train = data_train_feature{1};
data_test = data_test_feature{1};
%% svm 訓練
[~,train_y] = max(train_y');
model = svmtrain(train_y',data_train,'-t 0');
%% svm 測試
[~,test_y] = max(test_y');
predict1 = svmpredict(ones(numel(test_y),1),data_test,model);
accurary(i) = numel(find(predict1 == test_y'))/numel(test_y)
end
plot([0,K],[0,accurary]);
hold on;
plot([0,K],[0,accurary],'*');
str = [];
for i = 1:numel(auto_net)-1
str = [str,'-',num2str(auto_net(i))];
end
xlabel([num2str(numel(auto_net)-1),'層,分別為',str,'-X 層隱含層自編碼-特徵']);
ylabel(['準確率']);
axis([0 150 0 1]);得到的結果如下:
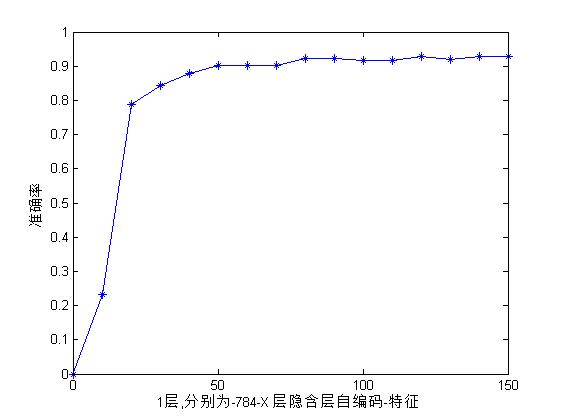
可以看到在K值達到50以後基本上快上升不動了。可見將784維的手寫體降到50多維以後基本上達到飽和了吧。
為了形成對比,下面我們使用PCA來實現降維的過程,和我們的自編碼降維提取的特徵形成對比,同樣以降維K取不同的值進行實驗,主程式碼如下:
%--------------添加當前資料夾-------------
%% addpath .\DeepLearnToolbox-master\.
currentFolder = pwd;
addpath(genpath(currentFolder))
%% 選擇樣本
K = [10,20,30,40,50,60,70,80,90,100,110,120,130,140,150];
for i = 1:15
load mnist_uint8;
choose_num_train = 5000;
train_x = double(train_x(1:choose_num_train,:))/255;
train_y = double(train_y(1:choose_num_train,:));
choose_num_test= 5000;
test_x = double(test_x(1:choose_num_test,:))/255;
test_y = double(test_y(1:choose_num_test,:));
%% 對訓練集於測試集求取PCA,都轉化到PCA資料
k = K(i); %降維數
[train_pca,train_mean,V] = PCA(train_x,k);
num_test = size(test_x,1);
img_mean_all = repmat(train_mean,num_test,1);%複製m行平均值至整個矩陣
test_x = double(test_x) - img_mean_all;
test_pca = test_x*V;
%% svm 訓練
[~,train_y] = max(train_y');
model = svmtrain(train_y',train_pca,'-t 0');
%% svm 測試
[~,test_y] = max(test_y');
predict1 = svmpredict(ones(numel(test_y),1),test_pca,model);
accurary(i) = numel(find(predict1 == test_y'))/numel(test_y)
end
plot([0,K],[0,accurary])
hold on;
plot([0,K],[0,accurary],'*')
xlabel(['PCA降維數']);
ylabel(['準確率'])
axis([0 150 0 1]);其中關於PCA函式可以在我以前人臉識別的部落格中找到,這裡再貼一下吧:
%--------------函式說明-------------
%-----簡單主成分分析演算法
%-----輸入:樣本集合矩陣:img
% 降維的維數 :k
%-----輸出:img_new,img_mean,V
%-----------------------------------
function [img_new,img_mean,V] = PCA(img,k)
%用法: [img_new,img_mean,V] = PCA(train_face,k);
%reshape函式:改變句矩陣的大小,矩陣的總元素個數不能變
img = double(img);
[m,n] = size(img); %取大小
img_mean = mean(img); %求每列平均值
img_mean_all = repmat(img_mean,m,1);%複製m行平均值至整個矩陣
Z = img - img_mean_all;
T=Z*Z'; %協方差矩陣(非原始所求矩陣的協方差)
[V,D] = eigs(T,k);%計算T中最大的前k個特徵值與特徵向量
V=Z'*V; %協方差矩陣的特徵向量
for i=1:k %特徵向量單位化
l=norm(V(:,i));
V(:,i)=V(:,i)/l;
end
img_new = Z*V; %低維度下的各個臉的資料想詳細瞭解PCA的可以翻我前面的部落格。
好了我們來看看在訓練集合測試集也都是5000的情況下一個實驗結果:
accurary =
Columns 1 through 8
0.8408 0.8954 0.9062 0.9088 0.9076 0.9134 0.9130 0.9142
Columns 9 through 15
0.9188 0.9150 0.9148 0.9172 0.9162 0.9142 0.9162把結果畫出來是這樣的:
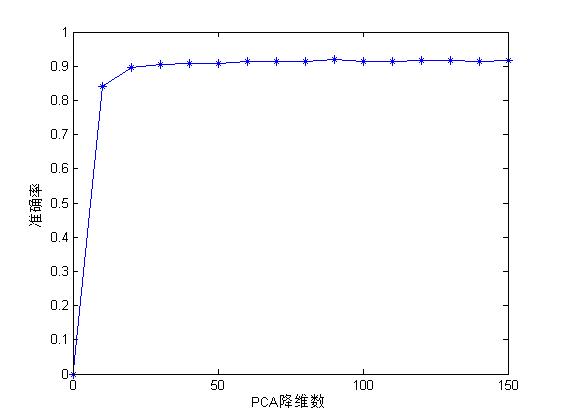
從資料上看最大準確率為0.9188,而在前面的自編碼提取特徵並用SVM實驗中,最大準確率可以達到0.9288,整整0.01的差別,也就是多0.01*5000=50個樣本分類正確。
好了,到了這裡我們已經可以看出通過機器自己找特徵與人工找特徵(其實PCA還不能算純人工找特徵)的差別了吧,可見自編碼的特徵尋找能力是要強於PCA的,我們知道PCA這種降維方式其實也很強了,至今在多數地方依然首要用到。那麼,這還是沒有怎麼優化的自編碼找特徵,當我們在優化優化,將會得到更好的結果。並且這還只是三層網路的自編碼,那麼真正的深度學習可是很多層的,當很多層來了以後,其結果又會改善多少呢?下回繼續介紹。
相關推薦
深度學習系列(七):自編碼網路與PCA特徵學習的分類對比實驗
上節我們看到自編碼網路額隱含層可以用於原始資料的降維(其實也可以升維,不過把隱含層的單元設定的比輸入維度還要多),換而言之就是特徵學習,那麼學習到的這些特徵就可以用於分類了,本節主要試驗下這些特徵用於分類的效果。 先以最簡單的三層自編碼網路為例,先訓練自編碼網
深度學習框架Keras學習系列(一):線性代數基礎與numpy使用(Linear Algebra Basis and Numpy)
又開一個新坑~~ 因為確實很有必要好好地趁著這個熱潮來研究一下深度學習,畢竟現在深度學習因為其效果突出,熱潮保持高漲不退,上面的政策方面現在也在向人工智慧領域傾斜,但是也有無數一知半解的人跟風吹捧,於是希望藉此教程,讓自己和讀者一起藉助keras,從上到下逐漸
機器學習總結(七):基本神經網路、BP演算法、常用啟用函式對比
1. 神經網路 (1)為什麼要用神經網路? 對於非線性分類問題,如果用多元線性迴歸進行分類,需要構造許多高次項,導致特徵特多學習引數過多,從而複雜度太高。 (2)常用的啟用函式及其優缺點 階
深度學習系列(三):簡單網路的自編碼學習
本節將研究深度學習網路權值設計的重要思想之一:自編碼思想,在正式介紹之前先以一個簡單的介紹一篇,一層隱含層網路的自編碼學習問題。 什麼是自編碼?所謂自編碼就是自己給自己編碼,再簡單點就是令輸出等於輸入自己。以一個簡單三層網路為例如下: 這裡我們假設輸出等
各種音視訊編解碼學習詳解之 編解碼學習筆記(七):微軟Windows Media系列
最近在研究音視訊編解碼這一塊兒,看到@bitbit大神寫的【各種音視訊編解碼學習詳解】這篇文章,非常感謝,佩服的五體投地。奈何大神這邊文章太長,在這裡我把它分解成很多小的篇幅,方便閱讀。大神部落格傳送門:https://www.cnblogs.com/skyofbitbi
深度學習方法(七):最新SqueezeNet 模型詳解,CNN模型引數降低50倍,壓縮461倍!
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術感興趣的同學加入。 本文講一下最新由UC Berkeley和Stanford研究人員一起完成的Sque
深度學習系列(五):一個簡單深度學習工具箱
本節主要介紹一個深度學習的matlab版工具箱, 該工具箱中的程式碼很簡單,感覺比較適合用來學習演算法。裡面有常見的網路結構,包括深度網路(NN),稀疏自編碼網路(SAE),CAE,深度信念網路(DBN)(基於玻爾茲曼RBM實現),卷積神經網路(CNN
編解碼學習筆記(七):微軟Windows Media系列
Microsoft 公司主導的音訊視訊編碼系列,它的出現主要是為了進行網路視訊傳輸,現在已經向HDTV 方面進軍,開發了 WMV HD 應用。WMV(Windows Media Video)是微軟公司開發的一組數字視訊編 解碼格式的通稱,它是Windows Media架
周志華《機器學習》課後習題解答系列(七):Ch6
本章概要 本章講述支援向量機(Support Vector Machine,SVM),相關內容包括: 支援向量分類器(SVM classifier) 支援向量(support vector)、間隔(margin)、最大間隔(maximum
JAVA學習(七):方法重載與方法重寫、thiskeyword和superkeyword
格式 hello new 初始 per 而且 方法重寫 學習 方式 方法重載與方法重寫、thiskeyword和superkeyword 1、方法重載 重載可以使具有同樣名稱但不同數目和類型參數的類傳遞給方法。 註: 一是重載方法的參數列表必須與被重載的方法不同
【開源】OSharp框架學習系列(1):總體設計及系列導航
正是 html 組織 內聚性 權限 是什麽 enc 3-0 分發 OSharp是什麽? OSharp是個快速開發框架,但不是一個大而全的包羅萬象的框架,嚴格的說,OSharp中什麽都沒有實現。與其他大而全的框架最大的不同點,就是OSharp只做抽象封裝,不做實現。依賴註
EF學習筆記(七):讀取關聯數據
取數據 microsoft image zha 手動 模型 取數 foreach ret 總目錄:ASP.NET MVC5 及 EF6 學習筆記 - (目錄整理) 本篇參考原文鏈接:Reading Related Data 本章主要講述加載顯示關聯數據; 數據加載分為以下三
JavaScript學習日誌(七):表單腳本
prev 調用 don 表單 rip 如果 html image 集合 一,基礎知識 1,取得<form>元素引用的方式,常用的是通過id,其次可以通過document.forms可以取得頁面中所有的表單,在這個集合中,可以通過數值索引或name值來取得特定的表
Docker學習系列(一):windows下安裝docker
阻止 statistic pro nta 雙擊 copyright ner notebook 現在 本文目錄如下: windows按照docker的基本要求 具體安裝步驟 開始使用 安裝遠程連接工具連接docker 安裝中遇到的問題 Docker的更新 Dock
hadoop學習筆記(七):Java HDFS API
on() apr name pin package 目錄 except 讀取 play 一、使用HDFS FileSystem詳解 HDFS依賴的第三方包: hadoop 1.x版本: commons-configuration-1.6.jar comm
Druid.io系列(七):架構剖析
apache off 系統資源 單元 生命周期 dir 創建 主從 數據 1. 前言 Druid 的目標是提供一個能夠在大數據集上做實時數據攝入與查詢的平臺,然而對於大多數系統而言,提供數據的快速攝入與提供快速查詢是難以同時實現的兩個指標。例如對於普通的RDBMS,如果想
Mybatis學習系列(七)緩存機制
emca value 不存在 memcach except input jedis 寫入 on() Mybatis緩存介紹 MyBatis提供一級緩存和二級緩存機制。 一級緩存是Sqlsession級別的緩存,Sqlsession類的實例對象中有一個hashmap用於緩
eShopOnContainers學習系列(二):數據庫連接健康檢查
技術分享 負載 star bsp 方法 containe 需要 正常 連接 項目裏使用數據庫的時候,我們有時候需要知道數據庫當前的健康狀態,特別是當數據庫連接不上的時候能夠立馬獲悉。eShopOnContainers裏存在著大量的服務健康、連接健康的檢查,數據庫連接是其中之
Windows Service 學習系列(二):C# windows服務:安裝、解除安裝、啟動和停止Windows Service
一、通過CMD安裝、解除安裝、啟動、停止Windows Service 方法一 1.以管理員身份執行cmd 2.安裝windows服務 切換cd C:\Windows\Microsoft.NET\Framework\v4.0.30319(InstallUtil.e
java基礎學習總結(七):Cloneable介面和Object的clone()方法
為什麼要克隆 為什麼要使用克隆,這其實反映的是一個很現實的問題,假如我們有一個物件: public class SimpleObject implements Cloneable { private String str; public SimpleObject()