
Streamlined Cloud Data Management with Commvault
By Michael Barrow, Technical Alliance Architect, Cloud Providers, Commvault. Commvault is an Advanced APN Technology Partner and AWS Storage Competency Partner.
Cloud data management is an important part of your cloud journey, but it doesn’t have to be overly complicated. When your cloud strategy includes automated, repeatable processes for data migration, data management, and using data in the cloud, you can more quickly realize the benefits of your cloud projects.
Commvault: evolved data protection for a cloud-first world
Commvault, a comprehensive data management platform for both on-premises and cloud data, provides holistic data protection and data management (e.g., archiving, compliance, cataloging, e-Discovery, or identification and classification). Commvault software interoperates with every major operating system, application, and storage platform.
With Commvault, organizations can deftly manage business-critical information living on virtual machines (VMs) or physical servers, whether they are deployed in traditional data centers, the cloud, or both.
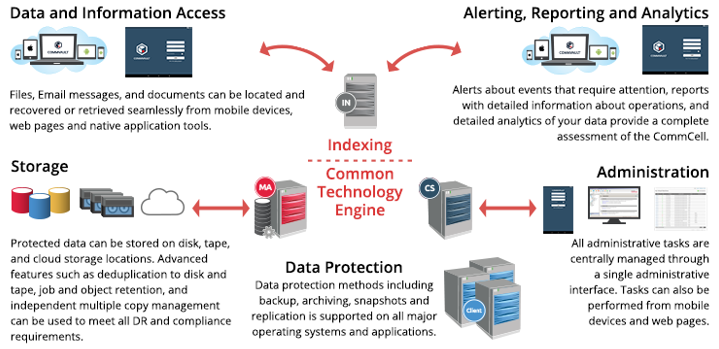
Commvault data protection software drives data protection, data backup, and data management for both on-premises and cloud resources.
In addition to standard applications (Oracle, Exchange, SQL Server, SharePoint, SAP, DB2, Informix, MySQL, and PostgreSQL), Commvault provides protection for leading big data applications, like Greenplum, Hadoop, and MongoDB. Commvault software can also preserve assets stored in Software as a Service (SaaS) platforms, like Microsoft Office 365 (O365), Salesforce, Gmail, or Google Drive.
Finally, Commvault offers both source and target compression and dedupe to minimize load on Amazon EC2 instances during backup and/or archive operations, and greatly reduce network bandwidth and storage consumption.
Joint Use Cases: AWS and Commvault Data Management
With tight integration between AWS and Commvault, joint customers can see significant value in a variety of use cases.
Data backup to the cloud replaces tape storage
We find that replacing complicated and expensive tape operations with cloud-based data backup is one of the quickest and easiest ways to start a transition to the cloud.
Commvault provides native support of both the Amazon S3 and Amazon Glacier APIs, so you don’t need to install and manage complex cloud gateways.
In just minutes, an on-premises Commvault installation can be configured for data backup to Amazon S3 or Amazon Glacier. The whole process consists of a few simple steps: set up an account on AWS, create a bucket, create a cloud library pointing at the bucket, and finally write data to the cloud library.
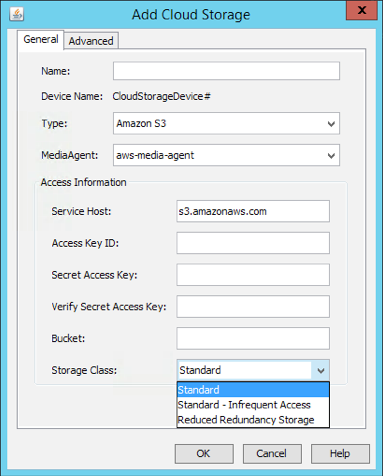
Add cloud storage dialog
See a short video demo of Commvault data backup to Amazon S3: Two clicks to the Cloud with AWS.
Data protection for Amazon EC2-based workloads
Commvault provides two choices for protecting Amazon EC2 workloads. First, the Commvault Virtual Server Agent (VSA) manages AWS-native data protection, for protecting file-based workloads or creating disaster recovery copies of instances. Commvault can create and manage snapshots of Amazon EC2 (and Amazon RDS) instances and manage copying snapshots to other regions. Commvault provides protection without the pain of maintaining complex scripts — saving effort, improving recovery, and reducing costs.
On the other hand, when application-consistency or granular recovery is needed, installing the Commvault agent within the guest OS is the way to go. It provides backups and archiving, and supports more flexible recovery options.
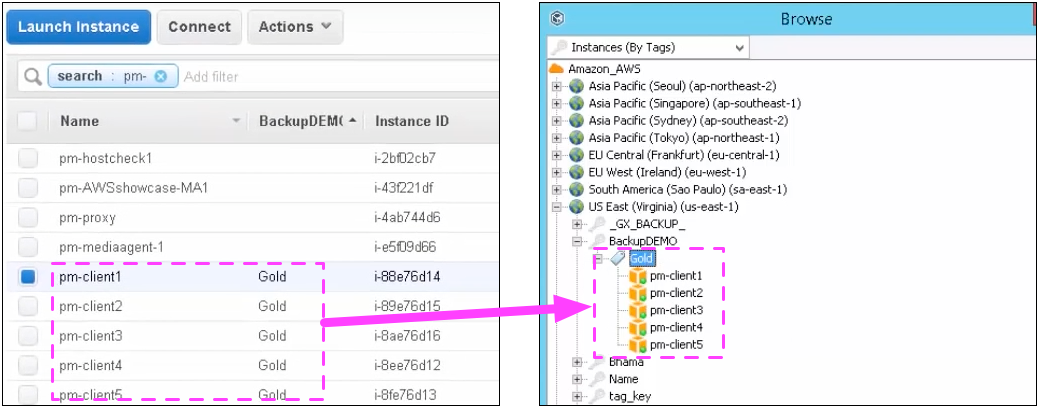
The Commvault rule groups feature even supports custom tags to select Amazon EC2 instances.
Fast, secure data migration to Amazon EC2
Commvault customers also redeploy on-premises VMs to AWS for test, disaster recovery, or permanent migration. With Commvault, you can backup VMs at the hypervisor level (Microsoft Hyper-V or VMware), restore the image onto AWS and convert into an Amazon EC2 instance. As part of the restore and conversion process, you can set the name of the instance, the availability zone, instance type, and network and security group settings.
Even moving hundreds of terabytes to AWS is a cinch with Commvault integration with Snowball. Rather than pointing a Commvault cloud library at Amazon S3, point to a host running the Snowball adapter and Commvault MediaAgent software. Once the data is transferred to AWS, you can reconfigure the cloud library to point at the Amazon S3 endpoint to continue normal backup and/or archive operations.
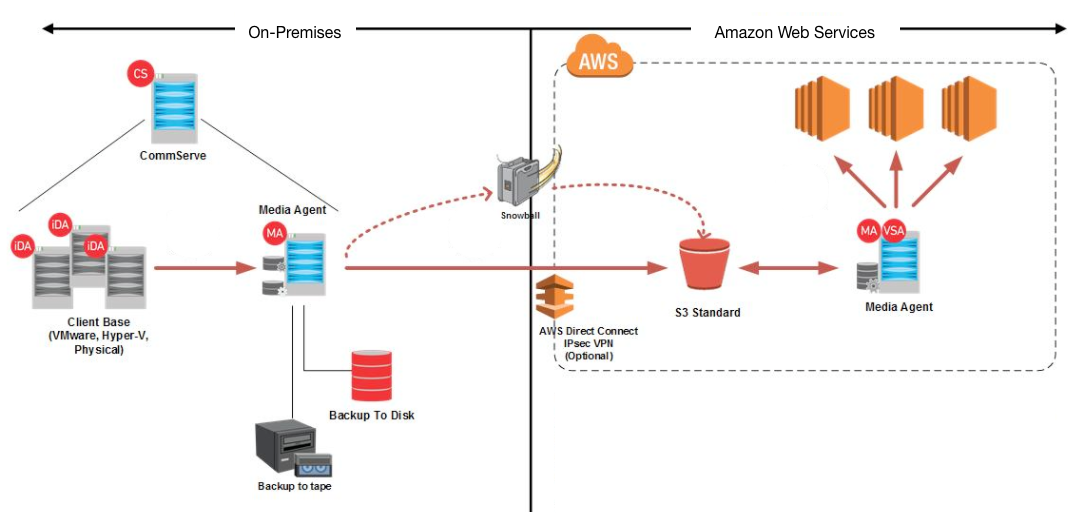
Architecture for VM migration from on-premises to Amazon Web Services
Data protection, compression, and deduplication for Amazon S3 buckets
AWS customers have several choices to preserve critical data written to Amazon S3: bucket versioning, cross-region replication, and MFA delete.
Commvault provides another protection option via the same policy-driven framework used for filesystem and application data. An appropriate storage policy can drive object copies to Commvault and into an Amazon S3 bucket in the same region as the origin or another region, an Amazon Glacier archive, or even an on-premises storage array. Just like any other data written to Commvault, compression and dedupe can significantly reduce the cost of data copies.
Archive SaaS and Office 365 to AWS
SaaS application and data backup is critical, especially as more line of business owners purchase new SaaS offerings and expect IT to support them in the cloud.
O365 is a popular example. Although O365 has offerings for content archival, an organization may want to manage this process on a disparate infrastructure as part of a larger compliance strategy or to add provider diversity to their stack.
Commvault data backup and archive of Exchange data from O365 can be deployed on Amazon EC2 instances with content stored in a compressed and deduped format within Amazon S3 or Amazon Glacier. With the add-in for Outlook installed on desktops, end users can seamlessly access messages and attachments that have been archived.
Additionally, corporate compliance personnel can use Commvault e-Discovery capabilities to search and execute legal holds against data in the AWS-resident archive without needing to interact with the O365 deployment.
The result is a system that provides infrastructure diversity, cost control, and centralized governance of critical business data.
Secure, Flexible Data Management
Commvault provides a single solution for managing data across files, applications, databases, hypervisors, and cloud. Commvault has complete data management capabilities across data backup, recovery, management and e-Discovery, that are tightly integrated with the functionality offered by AWS.
Best of all, Commvault gives you a “single pane of glass” to manage data protection and data management needs across the entire infrastructure and application stack, whether it is on-premises, on AWS, or a combination of the two.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
相關推薦
Streamlined Cloud Data Management with Commvault
By Michael Barrow, Technical Alliance Architect, Cloud Providers, Commvault. Commvault is an Advanced APN Technology Partner and AWS Storage Compe
Data Analysis with Python : Exercise- Titantic Survivor Analysis | packtpub.com
.com pub nal kaggle out conda anti vivo python kaggle-titantic, from: https://www.youtube.com/watch?v=siEPqQsPLKA install matplotlib: con
SDP(0):Streaming-Data-Processor - Data Processing with Akka-Stream
數據庫管理 新的 集成 部分 ont lock 感覺 sharding 數據源 再有兩天就進入2018了,想想還是要準備一下明年的工作方向。回想當初開始學習函數式編程時的主要目的是想設計一套標準API給那些習慣了OOP方式開發商業應用軟件的程序員們,使他們能用一種接近
Building Data Models with PowerPivot_進階篇2
5.1 使用 Userelationship 建立兩表之間的多個關係 USERELATIONSHIP(多端,一端) Measure_送貨數量 = CALCULATE(SUM([數量])),USERELATIONSHIP('銷售記錄'[實際送貨日期],'日曆年'[日期]) 5.2
Building Data Models with PowerPivot_進階篇
Building Data Models with PowerPivot_進階篇 2.3 使用連結回標進行RFM分析 R Recent近度 MIN([近度]); [近度]=TODAY()-[下單日期] 3.1 使用高階DAX函式 高階聚合函式SUMX SUMX函式
Change the default MySQL data directory with SELinux enabled
轉載:https://rmohan.com/?p=4605 Change the default MySQL data directory with SELinux enabled This is a short article that explains how you
Spring Cloud Data flow
Spring Cloud Data Flow 介紹 1.Data flow 是一個用於開發和執行大範圍資料處理其模式包括ETL,批量運算和持續運算的統一程式設計模型和託管服務。 2.對於在現代執行環境中可組合的微服務程式來說,spring cloud data flow是一個原生雲
DataCamp Data Scientist with Python track 學習筆記
Importing Data in Python: Customizing your pandas import: # Import matplotlib.pyplot as plt import matplotlib.pyplot as plt #
Modern Data Lake with Minio : Part 1
轉自:https://blog.minio.io/modern-data-lake-with-minio-part-1-716a49499533 Modern data lakes are now built on cloud storage, helping organizations lever
Modern Data Lake with Minio : Part 2
轉自: https://blog.minio.io/modern-data-lake-with-minio-part-2-f24fb5f82424 In the first part of this series, we saw why object storage systems like Min
Planar data classification with one hidden layer
From Logistic Regression with a Neural Network mindset, we achieved the Neural Network which use Logistic Regression to resolve the linear class
PCD檔案格式(The PCD (Point Cloud Data) file format)
本文件描述PCD(點雲資料)檔案格式,以及它在點雲庫(PCL)中的使用方式。 PCD檔案格式圖示 PCD檔案格式圖示 #為什麼新的檔案格式? PCD檔案格式並不意味著重新發明輪子,而是補充現有檔案格式,由於某種原因,這些格式不支援/不支援PCL為nD點雲處理帶來
從PCD檔案中讀取點雲資料(Reading Point Cloud data from PCD files)
在本教程中,我們將學習如何從PCD檔案中讀取點雲資料。 #程式碼 首先,在你最喜歡的編輯器中建立一個名為pcd_read.cpp的檔案,並在其中放置下面的程式碼: #include <iostream> #include <pcl/io/pcd
Chapter 6: Dimensionality Reduction: Squashing the Data Pancake with PCA
Suggestion it is best not to apply PCA to raw countss (word counts, music play counts, movie viewing counts, etc.)。 The reason for this is that such counts
Spring系列學習之Spring Cloud Data Flow 微服務資料流
英文原文:https://cloud.spring.io/spring-cloud-dataflow/ 目錄 Spring Cloud資料流 概覽 社群實現 快速開始 構建Spring Spring資料流 Sample Projects Related P
source conferences focusing on data management,data science? | Hacker News
Hello! Could you advice some open-source conferences focusing on data management, data science or topic specific, like graph database conferences in the US
Data Cleaning with Python and Pandas: Detecting Missing Values
Data Cleaning with Python and Pandas: Detecting Missing ValuesData cleaningcan be a tedious task.It’s the start of a new project and you’re excited to appl
OneDB: Build Cloud-Enabled Apps with Zero Cost
OneDB: Build Cloud-Enabled Apps with Zero CostI’m excited to announce the alpha release of OneDB, an open source backend-as-a-service. OneDB lets developer
Sized Artificial Intelligence (AI): Coming Soon To A Cloud Data Center Near You | AITopics
Data center-hosted artificial intelligence is rapidly proliferating in both government and commercial markets, and while it's an exciting time for AI, only
Restrict access to your AWS Glue Data Catalog with resource
A data lake provides a centralized repository that you can use to store all your structured and unstructured data at any scale. A data lake can in