
Hadoop架構介紹——HDFS的體系結構
設計目標:
-(硬體故障是常態,而非偶然)自動快速檢測應對硬體錯誤
-流式訪問資料(資料批處理)
-轉移計算比移動資料本身更划算(減少資料傳輸)
-簡單的資料一致性模型(一次寫入,多次讀取的檔案訪問模型)
-異構平臺可移植
HDFS體系結構
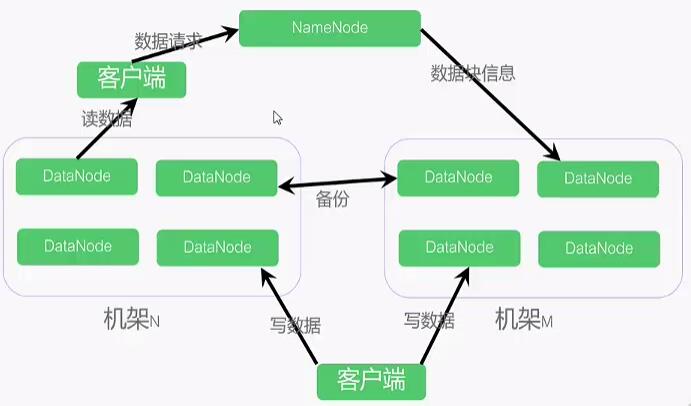
採用Master-Slaver模式:
NameNode中心伺服器(Master):維護檔案系統樹、以及整棵樹內的檔案目錄、負責整個資料叢集的管理。
DataNode分佈在不同的機架上(Slaver):在客戶端或者NameNode的排程下,儲存並檢索資料塊,並且定期向NameNode傳送所儲存的資料塊的列表。
客戶端與NameNode獲取元資料;
與DataNode互動獲取資料。
預設情況下,每個DataNode都儲存了3個副本,其中兩個儲存在同一個機架的兩個不同的節點上。另一個副本放在不同機架上的節點上。
基本概念
機架:HDFS叢集,由分佈在多個機架上的大量DataNode組成,不同機架之間節點通過交換機通訊,HDFS通過機架感知策略,使NameNode能夠確定每個DataNode所屬的機架ID,使用副本存放策略,來改進資料的可靠性、可用性和網路頻寬的利用率。
資料塊(block):HDFS最基本的儲存單元,預設為64M,使用者可以自行設定大小。
元資料:指HDFS檔案系統中,檔案和目錄的屬性資訊。HDFS實現時,採用了 映象檔案(Fsimage) + 日誌檔案(EditLog)的備份機制。檔案的映象檔案中內容包括:修改時間、訪問時間、資料塊大小、組成檔案的資料塊的儲存位置資訊。目錄的映象檔案內容包括:修改時間、訪問控制權限等資訊。日誌檔案記錄的是:HDFS的更新操作。
NameNode啟動的時候,會將映象檔案和日誌檔案的內容在記憶體中合併。把記憶體中的元資料更新到最新狀態。
使用者資料:HDFS儲存的大部分都是使用者資料,以資料塊的形式存放在DataNode上。
在HDFS中,NameNode 和 DataNode之間使用TCP協議進行通訊。DataNode每3s向NameNode傳送一個心跳。每10次心跳後,向NameNode傳送一個數據塊報告自己的資訊,通過這些資訊,NameNode能夠重建元資料,並確保每個資料塊有足夠的副本。
HDFS寫入資料的流程:

HDFS讀取資料的流程:
