
HADOOP docker(十):hdfs 結構體系
2.namenode和datanode
3.The File System Namespace 文件系統命名空間
4.Data Replication 數據復制
5.Replica Placement: The First Baby Steps 復制塊放置:初步的想法
6.Replica Selection 復制塊的選擇
7.Safemode 安全模式
8.The Persistence of File System Metadata 文件系統元數據的一致性
9.The Communication Protocols 通訊協議
10.Robustness 健壯性
10.1 Data Disk Failure, Heartbeats and Re-Replication 數據磁盤故障、心跳和再復制
10.2 Cluster Rebalancing 集群再平衡
10.3 Data Integrity 數據完整性
10.4 Metadata Disk Failure 元數據磁盤故障
10.5 Snapshots 快照
11. Data Organization 數據組織
11.1 Data Blocks 數據塊
11.2 Staging
11.3 Replication Pipelining 復制管道
12. Accessibility 可訪問性
12.1 FS Shell
12.2 DFSAdmin
12.3 Browser Interface 瀏覽器接口
13. Space Reclamation 空間回收
13.1 File Deletes and Undeletes 文件刪除與恢復
13.2 Decrease Replication Factor 減少復制因子
官方文檔:
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
大神的翻譯:
http://blog.csdn.net/guxch/article/details/18356215
我菜就抄抄補補就行了~
以下引用 http://blog.csdn.net/guxch/article/details/18356215,總結部分是自己寫的~
1.簡介
hdfs是一個分布式的文件系統,是為存儲支持海量而生。特點:
- 高容錯性
hdfs由多個節點來存儲數據,每個節點只存儲文件的一部分數據,少量的節點宕機不影響hdfs使用。另外,hdfs提供了數據自檢、數據修復功能。 - 流式數據訪問
運行在HDFS之上的應用需要以流式方式訪問它們的數據集,它們不是運行在通常文件系統之上的通常意義的應用。HDFS被設計成更適合批處理,而不是采用與用戶相互交互的方式。HDFS強調數據高吞吐性而非低延遲性,POSIX設置了許多嚴格的要求,以至以HDFS作為運行目標的應用不需要。為提高數據吞吐率,在一些關鍵方面的POSIX的語義已被改變。運行在HDFS之上的應用需要以流式方式訪問它們的數據集,它們不是運行在通常文件系統之上的通常意義的應用。HDFS被設計成更適合批處理,而不是采用與用戶相互交互的方式。HDFS強調數據高吞吐性而非低延遲性,POSIX設置了許多嚴格的要求,以至以HDFS作為運行目標的應用不需要。為提高數據吞吐率,在一些關鍵方面的POSIX的語義已被改變。
這一段扯了一堆犢子卻沒說清楚什麽是流式數據訪問
海量數據存儲
運行在HDFS之上的應用有大數據集。HDFS上一個典型文件的大小為數個GB到數個TB,因而,HDFS已為大數據文件做了優化,它應該聚合數據傳輸帶寬,並能在單一集群部署數百個節點。在單一實例下,它應該支持數百萬文件。運行在HDFS之上的應用有大數據集。HDFS上一個典型文件的大小為數個GB到數個TB,因而,HDFS已為大數據文件做了優化,它應該聚合數據傳輸帶寬,並能在單一集群部署數百個節點。在單一實例下,它應該支持數百萬文件。簡單耦合模型
HDFS應用需要“一次寫多次讀”這樣一個訪問文件模式。一個文件一旦被創建,寫入和關閉,都不需要修改。這個假設簡化了數據的一致性,使數據可以大容量吞吐。一個Map/Reduce應用和一個web爬蟲應用特別適合於這種場合。移動計算比移動數據動“便宜”
如果應用程序所操作的數據就在附近,那麽這種應用的計算效能要高得多,特別是當數據集很大的時刻。這減少了網絡擁塞,增加了系統的整體效率。這要求將計算放置到數據存儲的附近,而不是將數據移動到計算程序處。HDFS為應用程序提供了將它們移動到數據存儲位置的接口Portability Across Heterogeneous Hardware and Software Platforms 異構硬件和軟件平臺的可移植性
HDFS被設計成很容易地從一個平臺遷移到另一個平臺,這個特性有利於將HDFS作為一個可選擇的,大規模應用的平臺而被廣泛應用。
總結,說了這麽多,只需要計算hdfs是分布式的文件系統就行了。
2.namenode和datanode
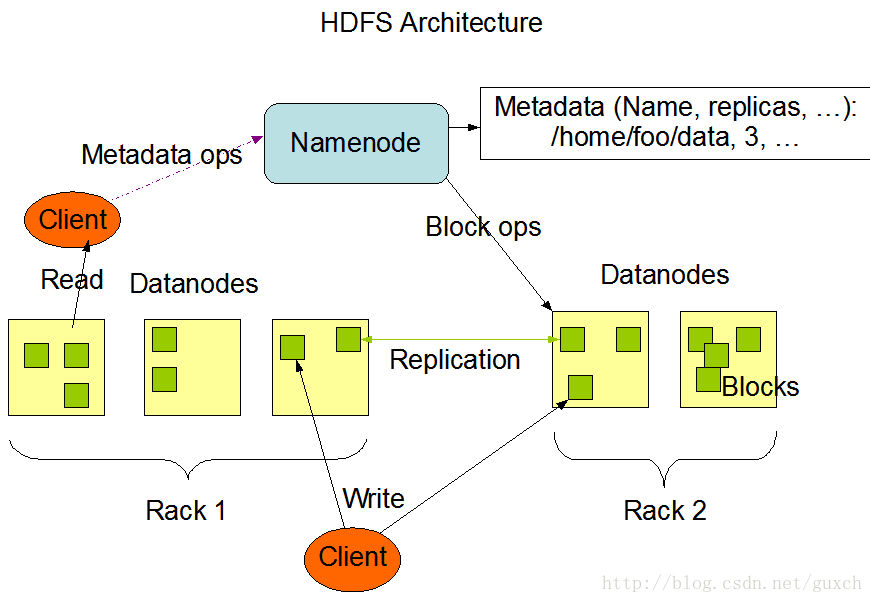
HDFS有一個master/slave(主/從)架構。一個HDFS集群有一個單一的NameNode,這是一個管理文件系統命名空間和規定客戶端如何訪問文件的主服務器。另外,集群由若幹DataNode,通常每個節點一個,管理這個節點上的存儲。HDFS暴露出一個文件系統命名空間,允許用戶數據存儲在其中。在內部,一個文件被分割成一個或多個塊,這些塊被存儲到若幹DataNode上。NameNode維護文件系統命名空間,例如打開、關閉、重命名文件和目錄,它也決定著數據塊到DataNode的映射。客戶端對文件系統的請求(讀/寫)由DataNode負責處理。在NameNode的指令下,DataNode也負責數據塊的創建、刪除和復制。HDFS有一個master/slave(主/從)架構。一個HDFS集群有一個單一的NameNode,這是一個管理文件系統命名空間和規定客戶端如何訪問文件的主服務器。另外,集群由若幹DataNode,通常每個節點一個,管理這個節點上的存儲。HDFS暴露出一個文件系統命名空間,允許用戶數據存儲在其中。在內部,一個文件被分割成一個或多個塊,這些塊被存儲到若幹DataNode上。NameNode維護文件系統命名空間,例如打開、關閉、重命名文件和目錄,它也決定著數據塊到DataNode的映射。客戶端對文件系統的請求(讀/寫)由DataNode負責處理。在NameNode的指令下,DataNode也負責數據塊的創建、刪除和復制。
NamaNode和DataNode被設計成可以運行在日常通用的機器上,這些機器通常運行GNU/Linux操作系統。HDFS用Java編寫,任何支持Java的機器都能運行NameNode或DataNode。采用高可移植Java語言意味著HDFS可以部署到各種類型的機器。一個典型的部署中,有一臺特別的機器,上面僅運行NameNode,集群中其他的機器,每一臺運行一個DataNode的實例。這個架構不排除在一臺機器上運行多個DataNode,但現實中很少見。
集群中僅有一個NameNode極大地簡化了系統的架構。NameNode是所有HDFS元數據的存儲者和管理者,而用戶數據決不會流入到NameNode上。NamaNode和DataNode被設計成可以運行在日常通用的機器上,這些機器通常運行GNU/Linux操作系統。HDFS用Java編寫,任何支持Java的機器都能運行NameNode或DataNode。采用高可移植Java語言意味著HDFS可以部署到各種類型的機器。一個典型的部署中,有一臺特別的機器,上面僅運行NameNode,集群中其他的機器,每一臺運行一個DataNode的實例。這個架構不排除在一臺機器上運行多個DataNode,但現實中很少見。
集群中僅有一個NameNode極大地簡化了系統的架構。NameNode是所有HDFS元數據的存儲者和管理者,而用戶數據決不會流入到NameNode上。
[========]
以上也是引用大神的翻譯,簡單總結一下:
1.namenode是負責HDFS中元數據與集群管理的。包括:文件的創建、重命名、刪除、位置移動、與客戶端交互、文件與數據塊映射、指定文件存儲位置、監控集群數據塊缺失、管理datanode數據塊復制與恢復等,但不負責文件的讀寫、存儲。namenode與datanode通過心跳來交流信息。
2.datanode 負責實際的數據塊的讀寫、塊狀態檢測等
3.namenode中的元數據分為兩塊,一塊是hdfs文件系統,即文件的相關信息(位置、對應的數據塊等),另一塊是blockmap,即datanode上數據塊信息
3.The File System Namespace 文件系統命名空間
HDFS支持傳統的層次結構文件組織方式。用戶或應用程序可以在目錄中創建目錄和存儲文件。文件系統命名空間的層次結構類似於其他文件系統,可以創建和刪除文件,將文件從一個目錄移動到另一個目錄,或者重命名文件。HDFS不支持硬鏈接或軟鏈接。但是,HDFS架構並不排除實現這些特性。
NameNode維護文件系統命名空間。任何對文件系統命名空間或者它的屬性的修改都被NameNode所記錄。應用程序可以指定一個文件的復制份數,一個文件擁有的拷貝數叫做該文件的復制因數,此信息由NameNode保存。
[========]
總結:當成linux文件系統來用就好!不支持鏈接而已
4.Data Replication 數據復制
HDFS被設計用來可靠地在一個大集群中跨機器地存儲巨大文件,它將每個文件保存為連續的塊,除最後一個塊之外,一個文件中所有塊的大小相同,為容錯性,文件塊被復制。文件塊大小與復制因數是每個文件的配置參數。應用程序可以為每個文件指定復制份數,這個復制因數可以在文件創建時指定,也可以在以後改變。HDFS中的文件都是“寫一次”的方式,並且在任何時刻,嚴格只有一個寫入者。
NameNode決定如何復制文件塊。它周期性地從集群中每一個DataNode接收心跳和塊報告。接收到心跳表示這個DataNode還在正常工作,而塊報告則包含著這個DataNode上所有文件塊的列表。
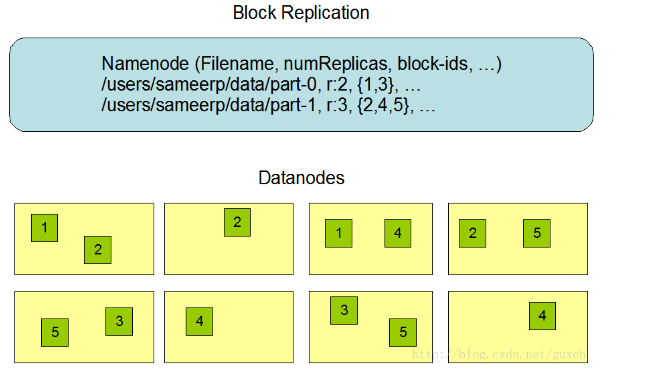
5.Replica Placement: The First Baby Steps 復制塊放置:初步的想法
復制塊的放置對HDFS的性能和可靠性至關重要。優化的復制塊放置方法是HDFS不同於其他分布式文件系統的地方,這個特性需要大量的經驗與調試。復制塊的機架自適應策略就是為了提高數據的可靠性、可用性和節省網絡帶寬。目前復制塊放置的實現策略僅是這個方向上的一個初步努力的結果。這個策略的短期目標是驗證它在實際生產系統的情況,了解它更多的狀況,為測試和研究更復雜的策略建立基礎。
集群上運行的大容量HDFS實例通常有許多機架。不同機架上的兩個節點之間的通信需要通過通信設備,大部分情況下,同一機架上兩臺機器之間的網絡帶寬大於不同機架上兩臺機器之間的帶寬。
NameNode決定著每個DataNode所屬的機架id,這個過程在“Hadoop Rack Awareness”中有一個描述。一個簡單但不太優化的方法是將復制塊放置到不同的機架上,當某個機架故障時,數據也不會丟失,並且讀數據時可以利用多個機架的帶寬,這種將復制塊均勻分布到不同機架的策略在發生部件故障時很容易做到負荷平衡,但是這個策略增加了寫成本,因為寫時,數據塊需要在不同機架之間傳輸數據。
通常情況下,當復制因數是3時,HDFS的放置策略是一個數據塊放置到本地機架的一個節點,另一份數據塊放置到本地機架的另一個節點,最後一份數據塊放置到不同機架的一個節點。這個策略減少了機架之間的通信而極大提高了寫性能。機架發生故障的可能性遠小於節點,這個策略並不影響數據的可靠性和可用性,但是,在讀數據時,它確實降低了整體帶寬,因為數據塊僅放置在兩個而不是三個機架上,這種策略下,一個文件的復制塊沒有在機架之間均勻分布,三分之一的復制塊在一個節點上;三分之二的復制塊在一個機架上,另三分之一的復制塊均勻分布在另外的機架上。這個策略提高了寫性能,沒有降低數據可靠性或讀性能。
這兒描述的目前缺省的復制塊放置策略還在不斷改進中。
[========]
總結:
1.hdfs上的數據塊保存多個副本,一般是三個,這樣可以提高文件的可用性,不容易因為機器故障導致文件不可用。
2.塊的放置策略是,在客戶端所在節點上先放一個塊,在同機架不同節點上再放一個塊,然後在不同機架上的節點上再放一個。這樣可以優化寫入和網絡開銷。
3.通過為datanode配置機架,那麽namenode可以實現2中的功能。默認只有一個default機架。
6.Replica Selection 復制塊的選擇
為減少全局的帶寬和讀延遲,HDFS嘗試從離要求讀的客戶端最近的地方讀取復制塊,如果讀者節點與復制塊節點在同一機架上,則這個復制塊優先用來滿足讀請求,如果HDFS集群有多個數據中心,則優先使用本地數據中心中的復制塊,而不是遠方的數據塊。
7.Safemode 安全模式
啟動時,NameNode進入一個特別的狀態,叫做“安全模式”。在安全模式下,不會發生數據塊的復制。NameNode接收各DataNode的心跳和數據塊信息。數據塊信息包含了DataNode上所有的數據塊列表。每個數據塊都有一個特定的最小的復制份數,如果數據塊的復制份數滿足這個最小值要求,NameNode就認為這個數據塊已被安全復制。當NameNode檢查了某一百分比(可配置)的復制塊,再加額外的30秒之後,NameNode就退出安全模式,它接著看看是否還有復制塊的份數少於規定值,然後將這些塊復制到其他DataNode上。
8.The Persistence of File System Metadata 文件系統元數據的一致性
HDFS命名空間存儲在NameNode上。NameNode采用一個叫EditLog的事務日誌來持久性記錄每一個發生在文件系統metadata上的變化。例如,在HDFS上創建一個新文件會使NameNode向EditLog插入一條記錄,同樣,改變一個文件的復制因數也將在EditLog中插入一條記錄。NameNode采用宿主操作系統的一個本地文件來保存EditLog。整個文件系統命名空間,包括數據塊與文件的對應,文件系統的屬性,存儲在一個叫fsimage的文件中,這個文件也保存在NameNode的本地文件系統中。
NameNode將整個文件系統命名空間和文件塊映射表保持在內存中,它們被設計成緊湊形式,因此,即使NameNode有4GB的RAM,也能支持很大數量的文件和目錄。當NameNode啟動時,它從磁盤上讀取FsImage和EditLog,將EditLog中的事務應用於內存中的FsImage,然後更新磁盤上的FsImage,形成一個新版本。舊版本的EditLog就可以被截斷了,因為事務應用到FsImage中,並且被保存了。這個過程叫做一個檢查點。在目前的實現中,只有在NameNode啟動後才能產生檢查點。在不久的將來,會支持周期性檢查點,這個工作目前正在進行中。
DataNode將HDFS的數據存儲在本地文件系統中,DataNode並不知道HDFS文件,它只是將HDFS不連續的文件數據塊存儲在本地文件系統。DataNode不會將所有文件都創建在一個目錄中,相反,它采用啟發式方面來決定每個目錄下最佳的文件數目,在合適的時候創建子目錄。將所有文件創建在同一目錄下不是最佳的方法,這是因為本地文件系統可能不高效地支持單一目錄下有巨大的文件數目。當DataNode啟動後,它掃描本地文件系統,產生一個所有HDFS數據塊與本地文件對應的列表,然後將其發給NameNode,這個列表叫做Blockreport。
[========]
總結:
1.hdfs的元數據被持久化成兩部分:fsimage 和 editlog。 fsimage相當於數據庫的增量備份,editlog相當於數據庫事務日誌,將fsimage和editlog合起來就是完全的數據。
2.namenode啟動後,將editlog和fsimage合並成完整的元數據並加載到內存中,並將合並後的寫入新的fsimage中,這叫做一個checkpoint。然後,hdfs上的修改被寫入新的editlog然後修改內存的hdfs映像。註意:內在中的映像是完整的hdfs元數據。
3.backupnode會定時(默認1小時)從namenode拿editlog,然後合並本地的fsimage,然後將合並後的fsimage發送到namenode上。
3.為了保證元數據的安全,一般使用HA技術或者,將fsimage和editlog寫入到多個不同的驅動器上。
9.The Communication Protocols 通訊協議
所有HDFS的通訊協議建立在TCP/IP協議之上,客戶端與NameNode通過一個配置的TCP端口建立連接,它們之間的協議叫ClientProtocol,DataNode與NameNode之間采用DataNodeProtocol通訊。一個RPC抽象層包裹了ClientProtocol和DataNodeProtocol。從設計上講,NameNode從不發起RPC,而只應答由客戶端或DataNode發起的RPC請求。
10.Robustness 健壯性
即使發生故障時,HDFS也能存儲數據,這是HDFS的基本目標。有三種常見的故障類型:NameNode故障、DataNode故障和網絡故障。
10.1 Data Disk Failure, Heartbeats and Re-Replication 數據磁盤故障、心跳和再復制
每個DataNode周期性地向NameNode發送心跳。網絡故障可能使一部分DataNode失去與NameNode的聯系。NameNode通過心跳丟失來發現這種情況,它將最近沒有發送心跳的DataNode標記為“dead”,並且不再向其發送新的IO指令。任何註冊在“dead”DataNode上的數據都不在可用。DataNode的“dead”狀態可以使一些數據塊的復制因數低於設定值,NameNode就不斷地檢查哪些數據塊需要復制,並在需要時發起復制過程。再復制可能因為如下原因而發生:一個DataNode不可用,一個復制塊損壞,DataNode上一個磁盤發生損壞,或者文件的復制因數增加了。
10.2 Cluster Rebalancing 集群再平衡
HDFS的架構與數據再平衡的方案是適應的。如果一個DataNode的磁盤空間低於某個閾值,一種再平衡方案要將數據從這個DataNode自動地移動到另一個。當對某一文件的請求突然有巨大增加時,一種再平衡方案要動態地創建額外的復制塊並再分配其他數據塊。這些類型的數據再平衡方案目前還沒用實現。
10.3 Data Integrity 數據完整性
從DataNode中獲取的數據塊在到達時損壞了,這是有可能發生的,因為存在存儲設備瑕疵、網絡故障或軟件bug。HDFS客戶端軟件實現驗證HDFS文件的校驗和。當客戶端創建了一個HDFS文件,它計算文件每個數據塊的校驗和,並將校驗和存儲在HDFS同一命名空間下的另一個隱藏文件中。當客戶端軟件接收到文件內容,通過與此文件相關聯的校驗和文件,它驗證數據塊的校驗和。如果不匹配,客戶端軟件可以選擇從另一個DataNode接收相同的數據塊。
10.4 Metadata Disk Failure 元數據磁盤故障
FsImage和EditLog是HDFS的中心數據結構,它們的損壞將使HDFS實例不能工作,因此,NameNode可以被配置支持多個FsImage和EditLog拷貝,任何對FsImage或EditLog的更新都將同步到每一個拷貝中。這種同步地更新FsImage和EditLog的多個拷貝可能會降低NameNode每秒可處理的事務數目,但是,這種降低是可接受的,因為即使對數據十分敏感的HDFS應用,它們對元數據不會敏感。當NameNode啟動時,它選擇最新的具有一致性的FsImage和EditLog拷貝來使用。
10.5 Snapshots 快照
快照支持保存某一特定時刻的數據。快照的一個使用場合是將損壞的HDFS實例回滾到以前已知好的時間點。
註:可以對文件或者目錄做快照
11. Data Organization 數據組織
11.1 Data Blocks 數據塊
HDFS被設計成支持非常大的文件。適合於HDFS的應用程序就是那些使用大數據集的應用,這些應用一次寫入數據,一次或多次讀取數據,並且滿足流式讀取的速度。HDFS支持這種文件一次寫多次讀的特性。HDFS中一個典型的數據塊是64MB,因此,HDFS中的文件被分割成64MB的塊,如果可能,每一塊放在不同的DataNode上。
11.2 Staging
用戶創建一個文件的請求並不會立刻傳遞給NameNode,實際上,開始時,HDFS客戶端會將文件數據緩存在本地臨時文件中。應用程序的寫操作會透明地再定向到這個臨時文件,當這個本地臨時文件積累到足夠HDFS塊大小時,客戶端與NameNode通訊,NameNode將文件名插入到文件系統層次目錄中,並分配一個數據塊給它,NameNode於是回應客戶端,給出DataNode和目的數據塊的標識,接著客戶端將臨時文件中的數據更新到指定的DataNode,當文件被關閉時,本地臨時文件中剩下的、沒有更新的數據被傳遞到DataNode,客戶端告訴NameNode說這個文件關閉了,在這個時候,NameNode才將文件創建的操作持久化保存(提交事務)。如果文件關閉之前NameNode失效了,文件就丟失了。
以上的方案是經過仔細考慮HDFS上的應用程序而得出的,這些應用程序需要流式寫文件,如果用戶不經過客戶端緩存而直接寫一個遠程文件,網絡速度和擁塞情況將極大地影響吞吐量,這個方案不是沒有先例,早期的分布式文件系統,例如AFS,就利用客戶端緩存來提高性能。POSIX已放松了對數據上傳更高性能的要求。
11.3 Replication Pipelining 復制管道
當用戶向一個HDFS文件寫數據時,數據先被寫入本地的臨時文件中,這已在上面解釋過了。假設HDFS文件的復制因數為3,當本地文件積累滿一個數據塊時,客戶端從NameNode得到一個DataNode的列表,這個列表就是放置該數據塊的DataNode。於是,客戶端將數據更新到第一個DataNode,第一個DataNode開始接收數據,接收到後(以較小的數據塊,4KB),將這個小數據塊保存到本地,然後將其傳輸給列表中的第二個DataNode,第二個DataNode也以相同的方式操作,將其傳遞給第三個DataNode,最後,第三個NataNode將數據寫入本地存儲位置。這樣,類似於管道,一個DataNode一邊從前一個DataNode接收數據,一邊將其傳遞給後一個DataNode。
12. Accessibility 可訪問性
從應用程序可以有多種辦法訪問HDFS。HDFS原生地提供了一個JAVA API來訪問文件系統,還有一個對這個JAVA API的C包裝。另外,也可以用一個HTTP瀏覽器來瀏覽HDFS中的文件。目前,通過WebDAV協議來瀏覽HDFS的工作正在進行中。
12.1 FS Shell
HDFS將用戶數據組織成文件和目錄這樣一種形式。它提供了一個叫“FSshell”的命令行接口,允許用戶與HDFS數據交換。這個命令行的句法類似於用戶已經熟悉的其他命令行工具(例如bash,csh),以下是一些命令行和與之對應動作的例子。
| Action | Command |
|---|---|
| Create a directory named /foodir | bin/hadoop dfs -mkdir /foodir |
| Remove a directory named /foodir | bin/hadoop dfs -rmr /foodir |
| View the contents of a file named /foodir/myfile.txt | bin/hadoop dfs -cat /foodir/myfile.txt |
FS shell的目標是給需要腳本語言與存儲數據交互的應用程序。
12.2 DFSAdmin
DFSAdmin命令集是用來管理HDFS集群的,這些命令僅被HDFS管理員使用。下面是是一些命令和與之對應動作的例子。
| Action | Command |
|---|---|
| Put the cluster in Safemode | bin/hadoop dfsadmin -safemode enter |
| Generate a list of DataNodes | bin/hadoop dfsadmin -report |
| Recommission or decommission DataNode(s) | bin/hadoop dfsadmin -refreshNodes |
12.3 Browser Interface 瀏覽器接口
典型的HDFS安裝配置了一個web服務器,采用配置的TCP端口來瀏覽HDFS命名空間。這個功能允許用戶可以用web瀏覽器來瀏覽HDFS命名空間並查看文件的內容。
(以下是自己翻譯~)
13. Space Reclamation 空間回收
13.1 File Deletes and Undeletes 文件刪除與恢復
如果開啟了回收站功能,那麽通過fs shell刪除的文件先被放到回收站中(不知道通過API刪除的會不會這樣),只在文件在回收站中就可以被恢復。回收站的默認位置是(/user/
$ hadoop fs -mkdir -p delete/test1
$ hadoop fs -mkdir -p delete/test2
$ hadoop fs -ls delete/
Found 2 items
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 delete/test1
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:40 delete/test2
刪除到回收站
$ hadoop fs -rm -r delete/test1
Moved: hdfs://localhost:8020/user/hadoop/delete/test1 to trash at: hdfs://localhost:8020/user/hadoop/.Trash/Current
刪除時不進入回收站
$ hadoop fs -rm -r -skipTrash delete/test2
Deleted delete/test2
查看回收站
$ hadoop fs -ls .Trash/Current/user/hadoop/delete/
Found 1 itemsdrwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 .Trash/Current/user/hadoop/delete/test113.2 Decrease Replication Factor 減少復制因子
當一個文件的復制因數變小時,NameNode選擇能被刪除的過量的復制塊。這個信息隨下一次的DataNode的心跳而傳遞給DataNode,DataNode接著刪除對應的塊和釋放對應的空間,再一次說明,調用setReplication完成的時刻與集群中出現對應的剩余空間的時刻之間相比,可能有一個滯後。
註:對於已經存在於hdfs上的文件,修改dfs.replication後不會降低或者增加復制因子。必須通過fs shell hadoop dfs -setrep來修改已經存在的文件的復本數。如
hadoop dfs -setrep -w 3 -R /user/hadoop/dir1將復制因子修改為3.
本節的東西實在太多,所以十分感覺感謝http://blog.csdn.net/guxch/article/details/18356215!
來自為知筆記(Wiz)
HADOOP docker(十):hdfs 結構體系