
堆排序詳解【java版附流程圖】
堆排序詳解——java版
近期一直再看別人的原始碼,無意中發現了他裡面使用了堆排序演算法,由於以前對於堆的排序問題都只是聽過,而沒有真正的理解過它和實踐過它。於是也借本次機會了解了一下堆排序的演算法。其實堆的排序是通過二叉樹的形式對元素進行排序,它的規律是:ki>=k2i並且ki>=k2i+1或者是ki<=k2i並且ki<=k2i+1,意思就是它的父節點一定大於(小於)它的兩個孩子們他們節點,也可以叫大堆排序(小堆排序)下面給出它們的儲存結構圖:
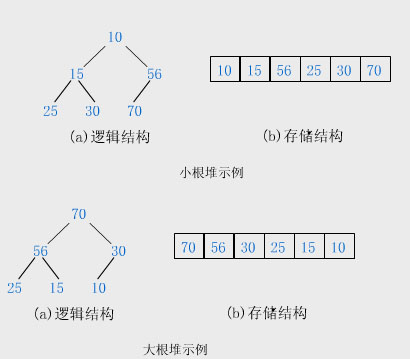
上面的圖是我從百度百科裡面截過來的。堆排序是通過陣列的形式儲存二叉樹的資訊,那麼它就需要計算一個節點的父節點位置,和一個節點的左孩子和右孩子節點的位置,其公式分別為:父=((i+1)/2)-1 左=(2*(i+1))-1 右=2*(i+1)。可以通過以上幾個公式計算節點的父節點和孩子節點儲存在陣列是的位置。所以當向堆中新增元素的時候,將堆的大小新增1,用於儲存新新增進來的元素,新增元素的初始儲存位置是堆尾(注意此時還未將元素新增到堆中,只是表示在當前堆大小加一的位置將要存放新新增進來的元素)。先找到插入元素存放的位置,也就是將插入的元素和當前堆中最後元素的父節點進行比較,如果比該父節點好,則將父節點移動到移動到插入元素初始儲存的位置,而新新增元素此時的儲存位置是剛才父節點的儲存位置,將繼續和父節點的父節點進行比較,重複上面的操作,就是調換新新增的儲存位置和當前比較的父節點的位置,直到遇到一個父節點比它好或者是到了堆的頂部則停止尋找。這樣會導致一個為題,就是假設新新增的元素不是插在堆的尾部,那麼將會導致在插入新元素之後的元素就失去了堆排序的特性,就是父節點比孩子節點大(小),所以此時將還要使用一個heapify(i),方法來進行對插入新元素位置以後的元素進行重新進行堆排序。詳細的思路可見程式碼。以下貼上處我用java實現的堆排序程式碼:
public class HeapSort { private IntArray vertexts;//該陣列是儲存元素資訊 private FloatArray weight;//儲存元素的權重,注意元素的位置和其對應的權重位置要一一對應 private IntIntHashMap vertMap;//這個記錄元素儲存的位置 private boolean Comparemode;//標記比較方式 private float maxWeight;//最大的值 /*public static void main(String[] args) { HeapSort sort = new HeapSort(true, Float.MAX_VALUE); for (int i = 0; i < 100; i++) { sort.addElement(i, (float) Math.random()); } for (int i = 0; i < 100; i++) { System.out.print("cost :" + sort.getBestCost() + "-->"); System.out.println(" Node: " + sort.removeBestElemment()); } }*/ /** * * @param Comparemode 該引數設定該推排序是取大的還是小的,當為true時,這取大,否則取小 * @param maxWeight 設定該堆最差的權重,一般設定為無窮大 */ public HeapSort(boolean Comparemode, float maxWeight) { this.vertexts = new IntArray(); this.weight = new FloatArray(); this.vertMap = new IntIntHashMap(); this.Comparemode = Comparemode; this.maxWeight = maxWeight; } public boolean compared(float w1, float w2) { if (this.Comparemode) { if (w1 > w2) { return true; } else { return false; } } else { if (w1 < w2) { return true; } else { return false; } } } /** * 方法是想堆中新增元素,並將該元素儲存在相應的位置 * * @param v * 元素編號 * @param w * 元素值 */ public void addElement(int v, float w) { int i = this.vertMap.size(); int k; this.vertexts.add(-1); this.weight.add(this.maxWeight); while (i > 0 && this.compared(w, this.weight.get(this.parent(i)))) { k = this.vertexts.get(this.parent(i)); this.vertexts.set(i, k); this.weight.set(i, this.weight.get(this.parent(i))); this.vertMap.add(k, i); i = this.parent(i); } this.vertexts.set(i, v); this.weight.set(i, w); this.vertMap.add(v, i); } public float getBestCost() { return this.weight.get(0); } public int getBestVertex() { return this.vertexts.get(0); } //移出最好的元素並將該最好的發回給使用者 public int removeBestElemment() { if (this.vertexts.size() <= 0) { return -1; } int v = this.vertexts.get(0); this.vertMap.remove(v); this.vertexts.set(0, this.vertexts.get(this.vertexts.size() - 1)); this.weight.set(0, this.weight.get(this.weight.size() - 1)); // 此是因為this.vertexts.get(0)的位置還不確定,所以先付-1表示位置不確定 this.vertMap.add(this.vertexts.get(0), -1); this.vertexts.remove(this.vertexts.size() - 1); this.weight.remove(this.weight.size() - 1); heapify(0); return v; } //移除指定的元素 public boolean removeElement(int v) { if (this.vertexts.size() != 0) { int i = this.vertMap.get(v); if (i == -1) return false; this.vertexts.set(i, this.vertexts.get(this.vertexts.size() - 1)); this.weight.set(i, this.weight.get(this.weight.size() - 1)); this.vertMap.add(this.vertexts.get(i), i); this.vertexts.remove(this.vertexts.size() - 1); this.weight.remove(this.weight.size() - 1); this.vertMap.remove(v); if (i <= this.vertexts.size() - 1) { heapify(i); Propogate(i); } return true; } return false; } //更新你指定的元素資訊,當你更新的元素不存在時,則執行新增操作 public int updateElement(int v, int w) { int i = this.vertMap.get(v); int k; if (i < 0) { this.addElement(v, w); } else { float w1 = this.weight.get(v); if (this.compared(w1, w)) { return 0; } while (i > 0 && this.compared(w1, this.weight.get(this.parent(i)))) { k = this.vertexts.get(this.parent(i)); this.vertexts.set(i, k); this.weight.set(i, this.weight.get(k)); this.vertMap.add(k, i); i = this.parent(i); } this.vertexts.set(i, v); this.weight.set(i, w); this.vertMap.add(v, i); } return 1; } //調整某位置以後的元素,例如上面刪除了指定元素好,將要對元素在堆中的位置進行重新的調整,此時就要呼叫該函式 private void heapify(int i) { int best = 0; int count = this.weight.size() - 1; int left = left(i); int right = right(i); if (left <= count && this.compared(this.weight.get(left), this.weight.get(i))) { best = left; } else { best = i; } if (right <= count && this.compared(this.weight.get(right), this.weight.get(best))) { best = right; } if (best != i) { swap(i, best); heapify(best); } } //上面調整了後面的元素後,那麼該位置上面的父節點也要做相應的調整,此時需呼叫該函式 private boolean Propogate(int v) { int v_parent = parent(v); while (v_parent > 0 && this.compared(this.weight.get(v_parent), this.weight.get(v))) { swap(v, v_parent); v = v_parent; v_parent = parent(v_parent); } return false; } //調換操作,將某一位置的元素和某一位置的元素互換 private void swap(int i, int j) { float wi = this.weight.get(i); int vi = this.vertexts.get(i); this.weight.set(i, this.weight.get(j)); this.vertexts.set(i, this.vertexts.get(j)); this.weight.set(j, wi); this.vertexts.set(j, vi); this.vertMap.add(this.vertexts.get(i), i); this.vertMap.add(this.vertexts.get(j), j); } //得到某個位置節點的父節點位置 private int parent(int i) { return ((i + 1) / 2) - 1; } //得到某個節點左孩子位置 private int left(int i) { return (2 * (i + 1)) - 1; } //獲得右孩子位置 private int right(int i) { return 2 * (i + 1); } }
該演算法實現上我使用了一個包,該包的功能和我們常使用的utils包的功能一樣,至不過,他們裡面的Map物件沒有put和set方法,它們均只有add,在add的時候會判斷集合中是否存在相同的key,如果存在這相當於set方法,如果不存在則相當與put方法,相應的jar包我會上傳到我在我的資源裡面,有興趣的可以下載下來,不需積分。在實現上額外的添加了一些方法如
public boolean removeElement(int v)
是為了使得程式能夠更好的適應各個場合。public boolean compared(float w1, float w2) public int updateElement(int v, int w)
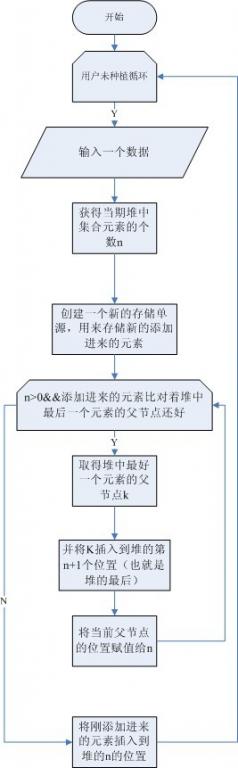
下面貼上處演算法的流程圖(只有新增元素的流程圖,具體的思想參照我上面的程式碼):
到此本文結束!謝謝瀏覽!歡迎評論,指出不足!
相關推薦
堆排序詳解【java版附流程圖】
堆排序詳解——java版 近期一直再看別人的原始碼,無意中發現了他裡面使用了堆排序演算法,由於以前對於堆的排序問題都只是聽過,而沒有真正的理解過它和實踐過它。於是也借本次機會了解了一下堆排序的演算法。其實堆的排序是通過二叉樹的形式對元素進行排序,它的規律是:
歸併排序詳解,Java版描述。
為了簡單起見,使用int型別陣列講述歸併演算法,後面擴充套件到其他型別的排序。 目錄 1.1 用具體例子說明 十人排序問題。 將十人均分為兩隊 五人分為三人,二人兩隊 對於三人的隊伍,再次分成兩人和一人的隊伍 對於兩
【資料結構與演算法】之排序全家桶(十大排序詳解及其Java實現)---第七篇
本篇文章彙總了10種場常見的排序演算法,篇幅較長,可以通過下面的索引目錄進行定位查閱: 7、桶排序 一、排序的基本概念 1、排序的定義 排序:就是使一串記錄,按照其中的某個或者某些關鍵字的大小,遞增或遞減的排列起來
各類排序演算法詳解(java版)
摘要 整理了一些有關於排序演算法的資料,用java手寫了一些,有些博主懶得寫程式碼了就直接copy了網上的程式碼。在文章的最後還給出排序演算法穩定性的定義以及哪些是穩定的排序演算法。 目錄 一、快速排序 二、堆排序 三、插入排序 四、氣泡排序
經典排序之堆排序詳解
堆排序 一、概述 首先我們來看看什麼叫做堆排序? 若在輸出堆頂的最小值之後,使得剩餘的n-1個元素的序列重新又構成一個堆,則得到n個元素中的次小值,如此反覆,便能得到一個有序序列,稱這個過程為堆排序。 再來看看總結一下基本思想: 將無序序列建成一個堆 輸出堆頂的最小(大
基數排序詳解以及java實現
前言 基數排序(radix sort)又稱桶排序(bucket sort),相對於常見的比較排序,基數排序是一種分配式排序,即通過將所有數字分配到應在的位置最後再覆蓋到原陣列完成排序的過程。我在上一篇講到的計數排序也屬於這種排序模式,上一篇結尾處提到了計數排序的穩定性,即排序前和排序後相同的數字相對位置保持
插入排序詳解(Java實現)
一、基本思想 插入排序(Insertion-Sort)的演算法描述是一種簡單直觀的排序演算法。它的工作原理是通過構建有序序列,對於未排序資料,在已排序序列中從後向前掃描,找到相應位置並插入。 二、演算法描述 1.從第一個元素開始,該元素可以認為已經被
Memcached 安裝詳解【送源碼包】
ESS directory var code sco dex fire ref .html Memcached簡介 Memcached 是一個高性能的分布式內存對象緩存系統,用於動態Web應用以減輕數據庫負載。它通過在內存中緩存數據和對象來減少讀取數據庫的次數,從而提高動
SparkStreaming部分:OutPutOperator類,SaveAsHadoopFile運算元(實際上底層呼叫textFileStream讀取的,跟前兩種有一些區別)【Java版純程式碼】
package streamingOperate.output; import java.util.Arrays; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; imp
SparkSQL建立RDD:UDF(UserDataFrame)使用者建立自定義函式(包含動態建立schema,使用者自定義函式,查詢字元的個數)【Java版純程式碼】
Java版程式碼: package com.bjsxt; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import org.apache.spark.Spark
SparkSQL建立RDD:UDAF(UserDefinedAggregatedFunction)使用者自定義聚合函式【Java版純程式碼】
要實現8個方法,8個方法中,最為重要的有3個: initialize:初始化,在給,map端每一個分割槽的每一個key進行初始化,給0 update:在map端聚合 merge: 在reduce端聚合 Java版程式碼: package com.bjsxt; im
SparkStreaming部分:OutPutOperator類,SaveAsTextFile運算元(實際上底層呼叫textFileStream讀取的,呼叫dstream儲存的)【Java版純程式碼】
package streamingOperate.output; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.F
朱、劉演算法:求最小樹形圖權值個人理解+個人詳解【最小樹形圖模板】
什麼是最小樹形圖?相信大家如果會過來看這篇文章,想必也應該對最小生成樹有所瞭解的,最小生成樹求的是無向圖的一顆生成樹的最小權值。我們的最小樹形圖就是來解決一個有向圖的一顆生成樹的最小權值,對於度娘來說,最小樹形圖是這樣定義的:最小樹形圖,就是給有向帶權圖中指定一個特殊的
(dataframe)利用dataframe來操作MySQL資料庫【Java版純程式碼】
package com.bjsxt; import java.util.HashMap; import java.util.Map; import java.util.Properties; import org.apache.commons.collections.ma
Spark部分:Spark中取交集(intersection )和取差集(subtract )【Java版純程式碼】
package com.bjsxt.spark; import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.Spar
SparkStreaming部分:updateStateByKey運算元(包含從Linux端獲取資料,flatmap切分,maptopair分類,寫入到本地建立的資料夾中)【Java版純程式碼】
package com.bjsxt; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction;
Storm部分:程式碼模板【Java版純程式碼】
總結:構成部分: Spout部分:繼承BaseRichSpout類,實現裡邊的三個方法:nextTuple,open,declareOutPutFields.主要的方法在nexttuple中寫,打包成集合的形式,在這個方法中用emit傳送,同時在declareOutPutF
【Flume】【原始碼分析】flumeng的事務控制的原理詳解【記憶體通道memory channel】
一開始我也是以為flume ng的事務控制是在sink端的,因為只看到那裡有事務的使用,但是今天看了一下fluem的整個事務控制,我才後知後覺,特此寫了這篇文章,望各位不吝指教。 先來一張圖吧!!! 從圖中可以看出,flume的事務控制在source端和sink端都有,具
實現最大堆(包括插入和從堆中取出元素)及第一種堆排序【Java版】
/** *實現最大堆 *用陣列儲存 *小優化:將swap用賦值代替,先不急著交換,先複製,再移動,最後賦值 *第一種堆排序,從小到大排序 *時間複雜度為O(nlogn) *空間複雜度O(n) */ public class MaxH
java中Collections.sort排序詳解
比較器 元素 .net 字符 atp style pri com 實現接口 Comparator是個接口,可重寫compare()及equals()這兩個方法,用於比價功能;如果是null的話,就是使用元素的默認順序,如a,b,c,d,e,f,g,就是a,b,c,d,e,f