
Storm學習記錄(二、分發策略與架構)
阿新 • • 發佈:2019-01-13
一、分發策略
- Shuffle Grouping:隨機分組,隨機派發stream裡面的tuple,保證每個bolt task接收到的tuple數目大致相同。輪詢,平均分配
- Fields Grouping:按欄位分組,比如,按"user-id"這個欄位來分組,那麼具有同樣"user-id"的 tuple 會被分到相同的Bolt裡的一個task, 而不同的"user-id"則可能會被分配到不同的task。
- All Grouping:廣播發送,對於每一個tuple,所有的bolts都會收到
- Global Grouping:全域性分組,把tuple分配給task id最低的task
- None Grouping:不分組,這個分組的意思是說stream不關心到底怎樣分組。目前這種分組和Shuffle grouping是一樣的效果。 有一點不同的是storm會把使用none grouping的這個bolt放到這個bolt的訂閱者同一個執行緒裡面去執行(未來Storm如果可能的話會這樣設計)。
- Direct Grouping:指向型分組, 這是一種比較特別的分組方法,用這種分組意味著訊息(tuple)的傳送者指定由訊息接收者的哪個task處理這個訊息。只有被宣告為 Direct Stream 的訊息流可以宣告這種分組方法。而且這種訊息tuple必須使用 emitDirect 方法來發射。訊息處理者可以通過 TopologyContext 來獲取處理它的訊息的task的id (OutputCollector.emit方法也會返回task的id)
- Local or shuffle grouping:本地或隨機分組。如果目標bolt有一個或者多個task與源bolt的task在同一個工作程序中,tuple將會被隨機發送給這些同進程中的tasks。否則,和普通的Shuffle Grouping行為一致
- customGrouping:自定義,相當於mapreduce那裡自己去實現一個partition一樣。
public class Main {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new MySpout(), 1);
// shuffleGrouping其實就是隨機往下游去發,不自覺的做到了負載均衡
// builder.setBolt("bolt", new MyBolt(), 2).shuffleGrouping("spout");
// fieldsGrouping其實就是MapReduce裡面理解的Shuffle,根據fields求hash來取模
// builder.setBolt("bolt", new MyBolt(), 2).fieldsGrouping("spout", new Fields("session_id"));
// 只往一個裡面發,往taskId小的那個裡面去傳送
// builder.setBolt("bolt", new MyBolt(), 2).globalGrouping("spout");
// 等於shuffleGrouping
// builder.setBolt("bolt", new MyBolt(), 2).noneGrouping("spout");
// 廣播
builder.setBolt("bolt", new MyBolt(), 2).allGrouping("spout");
// Map conf = new HashMap();
// conf.put(Config.TOPOLOGY_WORKERS, 4);
Config conf = new Config();
conf.setDebug(false);
conf.setMessageTimeoutSecs(30);
if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology());
}
}
}public class MyBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
OutputCollector collector = null;
int num = 0;
String valueString = null;
@Override
public void cleanup() {
}
@Override
public void execute(Tuple input) {
try {
valueString = input.getStringByField("log");
if (valueString != null) {
num++;
System.err.println(input.getSourceStreamId() + " " + Thread.currentThread().getName() + "--id="
+ Thread.currentThread().getId() + " lines :" + num + " session_id:"
+ valueString.split("\t")[1]);
}
collector.ack(input);
// Thread.sleep(2000);
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(""));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}public class MySpout implements IRichSpout {
private static final long serialVersionUID = 1L;
/**
* 檔案輸入流
*/
FileInputStream fis;
/**
* 位元組字元輸入流,將一個位元組流轉換為字元流
*/
InputStreamReader isr;
/**
* 緩衝流
*/
BufferedReader br;
SpoutOutputCollector collector = null;
String str = null;
@Override
public void nextTuple() {
try {
while ((str = this.br.readLine()) != null) {
// 過濾動作
collector.emit(new Values(str, str.split("\t")[1]));
}
} catch (Exception e) {
}
}
@Override
public void close() {
try {
br.close();
isr.close();
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
// 讀取檔案中的每一行的資料
try {
this.collector = collector;
this.fis = new FileInputStream("track.log");
this.isr = new InputStreamReader(fis, "UTF-8");
this.br = new BufferedReader(isr);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("log", "session_id"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
@Override
public void ack(Object msgId) {
System.out.println("spout ack:" + msgId.toString());
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void fail(Object msgId) {
System.out.println("spout fail:" + msgId.toString());
}
}二、架構設計
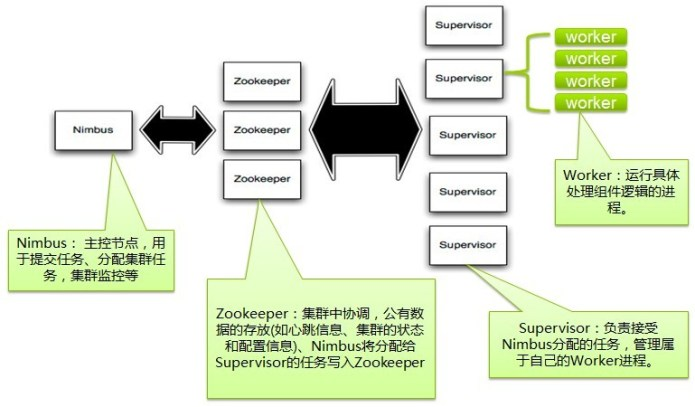
Nimbus
Storm叢集的Master節點,負責分發使用者程式碼,指派給具體的Supervisor節點上的Worker節點,去執行Topology對應的元件(Spout/Bolt)的Task。
Supervisor
Storm叢集的從節點,負責管理執行在Supervisor節點上的每一個Worker程序的啟動和終止。通過Storm的配置檔案中的supervisor.slots.ports配置項,可以指定在一個Supervisor上最大允許多少個Slot,每個Slot通過埠號來唯一標識,一個埠號對應一個Worker程序(如果該Worker程序被啟動)。
Worker
執行具體處理元件邏輯的程序。Worker執行的任務型別只有兩種,一種是Spout任務,一種是Bolt任務。
Task
worker中每一個spout/bolt的執行緒稱為一個task. 在storm0.8之後,task不再與物理執行緒對應,不同spout/bolt的task可能會共享一個物理執行緒,該執行緒稱為executor。
ZooKeeper
用來協調Nimbus和Supervisor,如果Supervisor因故障出現問題而無法執行Topology,Nimbus會第一時間感知到,並重新分配Topology到其它可用的Supervisor上執行