
Power from wind: Open data on AWS
 Data that describe processes in a spatial context are everywhere in our day-to-day lives and they dominate big data problems. Map data, for instance, whether describing networks of roads or remote sensing data from satellites, get us where we need to go. Atmospheric data from simulations and sensors underlie our weather forecasts and climate models. Devices and sensors with GPS can provide a spatial context to nearly all mobile data.
Data that describe processes in a spatial context are everywhere in our day-to-day lives and they dominate big data problems. Map data, for instance, whether describing networks of roads or remote sensing data from satellites, get us where we need to go. Atmospheric data from simulations and sensors underlie our weather forecasts and climate models. Devices and sensors with GPS can provide a spatial context to nearly all mobile data.
In this post, we introduce the WIND toolkit, a huge (500 TB), open weather model dataset that’s available to the world on Amazon’s cloud services. We walk through how to access this data and some of the open-source software developed to make it easily accessible. Our solution considers a subset of geospatial data that exist on a grid (raster) and explores ways to provide access to large-scale raster data from weather models. The solution uses foundational AWS services and the Hierarchical Data Format (HDF), a well adopted format for scientific data.
The approach developed here can be extended to any data that fit in an HDF5 file, which can describe sparse and dense vectors and matrices of arbitrary dimensions. This format is already popular within the physical sciences for both experimental and simulation data. We discuss solutions to gridded data storage for a massive dataset of public weather model outputs called the
Wind Integration National Dataset
As variable renewable power penetration levels increase in power systems worldwide, the importance of renewable integration studies to ensure continued economic and reliable operation of the power grid is also increasing. The WIND toolkit is the largest freely available grid integration dataset to date.
The WIND toolkit was developed by 3TIER by Vaisala. They were under a subcontract to the National Renewable Energy Laboratory (NREL) to support studies on integration of wind energy into the existing US grid. NREL is a part of a network of national laboratories for the US Department of Energy and has a mission to advance the science and engineering of energy efficiency, sustainable transportation, and renewable power technologies.
The toolkit has been used by consultants, research groups, and universities worldwide to support grid integration studies. Less traditional uses also include resource assessments for wind plants (such as those powering Amazon data centers), and studying the effects of weather on California condor migrations in the Baja peninsula.
 The diversity of applications highlights the value of accessible, open public data. Yet, there’s a catch: the dataset is huge. The WIND toolkit provides simulated atmospheric (weather) data at a two-km spatial resolution and five-minute temporal resolution at multiple heights for seven years. The entire dataset is half a petabyte (500 TB) in size and is stored in the NREL High Performance Computing data center in Golden, Colorado. Making this dataset publicly available easily and in a cost-effective manner is a major challenge.
The diversity of applications highlights the value of accessible, open public data. Yet, there’s a catch: the dataset is huge. The WIND toolkit provides simulated atmospheric (weather) data at a two-km spatial resolution and five-minute temporal resolution at multiple heights for seven years. The entire dataset is half a petabyte (500 TB) in size and is stored in the NREL High Performance Computing data center in Golden, Colorado. Making this dataset publicly available easily and in a cost-effective manner is a major challenge.
As other laboratories and public institutions work to release their data to the world, they may face similar challenges to those that we experienced. Some prior, well-intentioned efforts to release huge datasets as-is have resulted in data resources that are technically available but fundamentally unusable. They may be stored in an unintuitive format or indexed and organized to support only a subset of potential uses. Downloading hundreds of terabytes of data is often impractical. Most users don’t have access to a big data cluster (or super computer) to slice and dice the data as they need after it’s downloaded.
We aim to provide a large amount of data (50 terabytes) to the public in a way that is efficient, scalable, and easy to use. In many cases, researchers can access these huge cloud-located datasets using the same software and algorithms they have developed for smaller datasets stored locally. Only the pieces of data they need for their individual analysis must be downloaded. To make this work in practice, we worked with the HDF Group and have built upon their forthcoming Highly Scalable Data Service.
In the rest of this post, we discuss how the HSDS software was developed to use Amazon EC2 and Amazon S3 resources to provide convenient and scalable access to these huge geospatial datasets. We describe how the HSDS service has been put to work for the WIND Toolkit dataset and demonstrate how to access it using the h5pyd Python library and the REST API. We conclude with information about our ongoing work to release more ‘open’ datasets to the public using AWS services, and ways to improve and extend the HSDS with newer Amazon services like Amazon ECS and AWS Lambda.
Developing a scalable service for big geospatial data
The HDF5 file format and API have been used for many years and is an effective means of storing large scientific datasets. For example, NASA’s Earth Observing System (EOS) satellites collect more than 16 TBs of data per day using HDF5.
With the rise of the cloud, there are new challenges and opportunities to rethink how HDF5 can be enhanced to work effectively as a component in a cloud-native architecture. For the HDF Group, working with NREL has been a great opportunity to put ideas into practice with a production-size dataset.
An HDF5 file consists of a directed graph of group and dataset objects. Datasets can be thought of as a multidimensional array with support for user-defined metadata tags and compression. Typical operations on datasets would be reading or writing data to a regular subregion (a hyperslab) or reading and writing individual elements (a point selection). Also, group and dataset objects may each contain an arbitrary number of the user-defined metadata elements known as attributes.
Many people have used the HDF library in applications developed or ported to run on EC2 instances, but there are a number of constraints that often prove problematic:
- The HDF5 library can’t read directly from HDF5 files stored as S3 objects. The entire file (often many GB in size) would need to be copied to local storage before the first byte can be read. Also, the instance must be configured with the appropriately sized EBS volume)
- The HDF library only has access to the computational resources of the instance itself (as opposed to a cluster of instances), so many operations are bottlenecked by the library.
- Any modifications to the HDF5 file would somehow have to be synchronized with changes that other instances have made to same file before writing back to S3.
Using a pattern common to many offerings from AWS, the solution to these constraints is to develop a service framework around the HDF data model. Using this model, the HDF Group has created the Highly Scalable Data Service (HSDS) that provides all the functionality that traditionally was provided by the HDF5 library. By using the service, you don’t need to manage your own file volumes, but can just read and write whatever data that you need.
Because the service manages the actual data persistence to a durable medium (S3, in this case), you don’t need to worry about disk management. Simply stream the data you need from the service as you need it. Secondly, putting the functionality behind a service allows some tricks to increase performance (described in more detail later). And lastly, HSDS allows any number of clients to access the data at the same time, enabling HDF5 to be used as a coordination mechanism for multiple readers and writers.
In designing the HSDS architecture, we gave much thought to how to achieve scalability of the HSDS service. For accessing HDF5 data, there are two different types of scaling to consider:
- Multiple clients making many requests to the service
- Single requests that require a significant amount of data processing
To deal with the first scaling challenge, as with most services, we considered how the service responds as the request rate increases. AWS provides some great tools that help in this regard:
- Auto Scaling groups
- Elastic Load Balancing load balancers
- The ability of S3 to handle large aggregate throughput rates
By using a cluster of EC2 instances behind a load balancer, you can handle different client loads in a cost-effective manner.
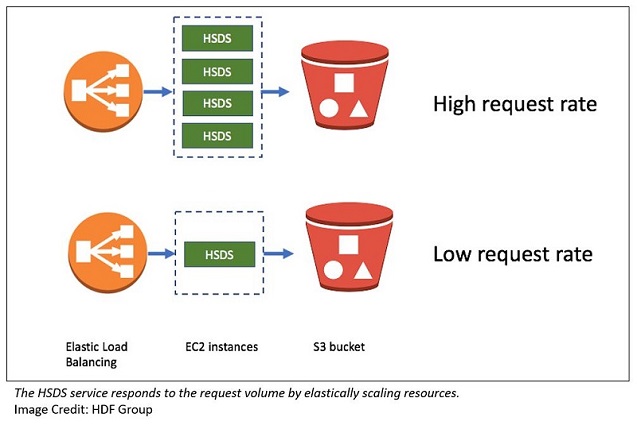
The second scaling challenge concerns single requests that would take significant processing time with just one compute node. One example of this from the WIND toolkit would be extracting all the values in the seven-year time span for a given geographic point and dataset.
In HDF5, large datasets are typically stored as “chunks”; that is, a regular partition of the array. In HSDS, each chunk is stored as a binary object in S3. The sequential approach to retrieving the time series values would be for the service to read each chunk needed from S3, extract the needed elements, and go on to the next chunk. In this case, that would involve processing 2557 chunks, and would be quite slow.
Fortunately, with HSDS, you can speed this up quite a bit by exploiting the compute and I/O capabilities of the cluster. Upon receiving the request, the receiving node can use other nodes in the cluster to read different portions of the selection. With multiple nodes reading from S3 in parallel, performance improves as the cluster size increases.
The diagram below illustrates how this works in simplified case of four chunks and four nodes.
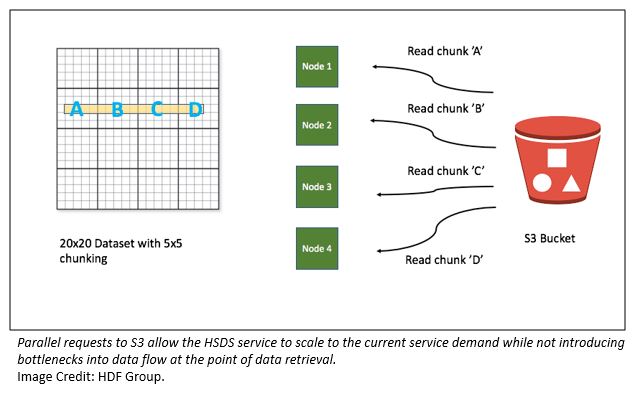
This architecture has worked in well in practice. In testing with the WIND toolkit and time series extraction, we observed a request latency of ~60 seconds using four nodes vs. ~5 seconds with 40 nodes. Performance roughly scales with the size of the cluster.
A planned enhancement to this is to use AWS Lambda for the worker processing. This enables 1000-way parallel reads at a reasonable cost, as you only pay for the milliseconds of CPU time used with AWS Lambda.
Public access to atmospheric data using HSDS and AWS
An early challenge in releasing the WIND toolkit data was in deciding how to subset the data for different use cases. In general, few researchers need access to the entire 0.5 PB of data and a great deal of efficiency and cost reduction can be gained by making directed constituent datasets.

NREL grid integration researchers initially extracted a 2-TB subset by selecting 120,000 points where the wind resource seemed appropriate for development. They also chose only those data important for wind applications (100-m wind speed, converted to power), the most interesting locations for those performing grid studies. To support the remaining users who needed more data resolution, we down-sampled the data to a 60-minute temporal resolution, keeping all the other variables and spatial resolution intact. This reduced dataset is 50 TB of data describing 30+ atmospheric variables of data for 7 years at a 60-minute temporal resolution.
 The WindViz browser-based Gridded Wind Toolkit Visualizer was created as an example implementation of the HSDS REST API in JavaScript. The visualizer is written in the style of ECMAScript 2016 using a modern development toolchain that includes webpack and Babel. The source code is available through our GitHub repository. The demo page is hosted via GitHub pages, and we use a cross-origin AJAX request to fetch data from the HSDS service running on the EC2 infrastructure. The visualizer can be used to explore the gridded wind toolkit data on a map. Achieve full spatial resolution by zooming in to a specific region.
The WindViz browser-based Gridded Wind Toolkit Visualizer was created as an example implementation of the HSDS REST API in JavaScript. The visualizer is written in the style of ECMAScript 2016 using a modern development toolchain that includes webpack and Babel. The source code is available through our GitHub repository. The demo page is hosted via GitHub pages, and we use a cross-origin AJAX request to fetch data from the HSDS service running on the EC2 infrastructure. The visualizer can be used to explore the gridded wind toolkit data on a map. Achieve full spatial resolution by zooming in to a specific region.
Programmatic access is possible using the h5pyd Python library, a distributed analog to the widely used h5py library. Users interact with the datasets (variables) and slice the data from its (time x longitude x latitude) cube form as they see fit.
Examples and use cases are described in a set of Jupyter notebooks and available on GitHub:
To run these notebooks on an EC2 instance in the Oregon Region, run the following commands:
$ sudo yum install git gcc
$ sudo pip install –user jupyter
$ pip install --user git+http://github.com/HDFGroup/h5pyd.git
$ git clone https://github.com/NREL/hsds-examples.git
$ cd hsds-examples
$ jupyter notebookNow you have a Jupyter notebook server running on your EC2 server.
From your laptop, create an SSH tunnel:
$ ssh –L 8888:localhost:8888 (IP address of the EC2 server)Now, you can browse to localhost:8888 using the correct token, and interact with the notebooks as if they were local. Within the directory, there are examples for accessing the HSDS API and plotting wind and weather data using matplotlib.
Controlling access and defraying costs
A final concern is rate limiting and access control. Although the HSDS service is scalable and relatively robust, we had a few practical concerns:
- How can we protect from malicious or accidental use that may lead to high egress fees (for example, someone who attempts to repeatedly download the entire dataset from S3)?
- How can we keep track of who is using the data both to document the value of the data resource and to justify the costs?
- If costs become too high, can we charge for some or all API use to help cover the costs?
To approach these problems, we investigated using Amazon API Gateway and its simplified integration with the AWS Marketplace for SaaS monetization as well as third-party API proxies.
In the end, we chose to use API Umbrella due to its close involvement with http://data.gov. While AWS Marketplace is a compelling option for future datasets, the decision was made to keep this dataset entirely open, at least for now. As community use and associated costs grow, we’ll likely revisit Marketplace. Meanwhile, API Umbrella provides controls for rate limiting and API key registration out of the box and was simple to implement as a front-end proxy to HSDS. Those applications that may want to charge for API use can accomplish a similar strategy using Amazon API Gateway and AWS Marketplace.
Ongoing work and other resources
As NREL and other government research labs, municipalities, and organizations try to share data with the public, we expect many of you will face similar challenges to those we have tried to approach with the architecture described in this post. Providing large datasets is one challenge. Doing so in a way that is affordable and convenient for users is an entirely more difficult goal. Using AWS cloud-native services and the existing foundation of the HDF file format has allowed us to tackle that challenge in a meaningful way.
Additional Reading
About the Authors
 Dr. Caleb Phillips is a senior scientist with the Data Analysis and Visualization Group within the Computational Sciences Center at the National Renewable Energy Laboratory. Caleb comes from a background in computer science systems, applied statistics, computational modeling, and optimization. His work at NREL spans the breadth of renewable energy technologies and focuses on applying modern data science techniques to data problems at scale.
Dr. Caleb Phillips is a senior scientist with the Data Analysis and Visualization Group within the Computational Sciences Center at the National Renewable Energy Laboratory. Caleb comes from a background in computer science systems, applied statistics, computational modeling, and optimization. His work at NREL spans the breadth of renewable energy technologies and focuses on applying modern data science techniques to data problems at scale.
 Dr. Caroline Draxl is a senior scientist at NREL. She supports the research and modeling activities of the US Department of Energy from mesoscale to wind plant scale. Caroline uses mesoscale models to research wind resources in various countries, and participates in on- and offshore boundary layer research and in the coupling of the mesoscale flow features (kilometer scale) to the microscale (tens of meters). She holds a M.S. degree in Meteorology and Geophysics from the University of Innsbruck, Austria, and a PhD in Meteorology from the Technical University of Denmark.
Dr. Caroline Draxl is a senior scientist at NREL. She supports the research and modeling activities of the US Department of Energy from mesoscale to wind plant scale. Caroline uses mesoscale models to research wind resources in various countries, and participates in on- and offshore boundary layer research and in the coupling of the mesoscale flow features (kilometer scale) to the microscale (tens of meters). She holds a M.S. degree in Meteorology and Geophysics from the University of Innsbruck, Austria, and a PhD in Meteorology from the Technical University of Denmark.
 John Readey has been a Senior Architect at The HDF Group since he joined in June 2014. His interests include web services related to HDF, applications that support the use of HDF and data visualization.Before joining The HDF Group, John worked at Amazon.com from 2006–2014 where he developed service-based systems for eCommerce and AWS.
John Readey has been a Senior Architect at The HDF Group since he joined in June 2014. His interests include web services related to HDF, applications that support the use of HDF and data visualization.Before joining The HDF Group, John worked at Amazon.com from 2006–2014 where he developed service-based systems for eCommerce and AWS.
 Jordan Perr-Sauer is an RPP intern with the Data Analysis and Visualization Group within the Computational Sciences Center at the National Renewable Energy Laboratory. Jordan hopes to use his professional background in software engineering and his academic training in applied mathematics to solve the challenging problems facing America and the world.
Jordan Perr-Sauer is an RPP intern with the Data Analysis and Visualization Group within the Computational Sciences Center at the National Renewable Energy Laboratory. Jordan hopes to use his professional background in software engineering and his academic training in applied mathematics to solve the challenging problems facing America and the world.
相關推薦
Power from wind: Open data on AWS
Data that describe processes in a spatial context are everywhere in our day-to-day lives and they dominate big data problems. Map data, for instan
Registry of Open Data on AWS
agricultureclimateearth observationelevationenvironmentalgismappingmeteorologicalsustainabilityweather Earth & Atmosphe
Open Data on AWS
Amazon Web Services is Hiring. Amazon Web Services (AWS) is a dynamic, growing business unit within Amazon.com. We are currently hiring So
Time Inc. Secures Customer Data on AWS Case Study
O’Sullivan says a lot of his peers at enterprise organizations remain skeptical about—or simply won’t discuss—cloud security. His response is t
雲端計算之路-出海記-小目標:Hello World from .NET 5.0 on AWS
品嚐過船上的免費晚餐,眺望著 aws 上搭建部落格園海外站的巨集偉目標,琢磨著眼前可以實現的小目標,不由自主地在螢幕上敲出了 —— "Hello World!",就從這個最簡單樸實的小目標開始吧 —— 用 ASP.NET Core on .NET 5.0 在 A
Learnings from a Data Science Conference, Open Data Science Europe
Learnings from a Data Science Conference, Open Data Science EuropeLast week I attended Open Data Science Europe hosted at the Novotel, London West. This is
Using Presto in our Big Data Platform on AWS
Using Presto in our Big Data Platform on AWSby Eva Tse, Zhenxiao Luo, Nezih Yigitbasi @ Big Data Platform teamAt Netflix, the Big Data Platform team is res
Informatica Data Lake Management on AWS
This Quick Start builds a data lake environment on the Amazon Web Services (AWS) Cloud by deploying the Informatica Data Lake Management solution
Hybrid Data Lake on AWS
This Quick Start deploys a hybrid cloud environment that integrates on-premises Hadoop clusters with a data lake on the Amazon Web Services (AWS)
Data Lake on AWS with Talend
An out-of-the-box open data lake solution with AWS and Talend allows you to build, manage, and govern your cloud data lake in the AWS Cloud so tha
Informatica Enterprise Data Catalog on AWS
This Quick Start deploys Enterprise Data Catalog from Informatica on the AWS Cloud. Enterprise Data Catalog helps you discover and catalog assets
Deploy a Data Warehouse on AWS
Data warehousing is a critical component for analyzing and extracting actionable insights from your data. Amazon Redshift allows you to
Informatica Big Data Management on AWS
This Quick Start deploys Informatica Big Data Management automatically into an AWS Cloud configuration of your choice. Big Data Managemen
Predictive Data Science with Amazon SageMaker and a Data Lake on AWS
This Quick Start builds a data lake environment for building, training, and deploying machine learning (ML) models with Amazon SageMaker on the Am
Data Lake Foundation on AWS
This Quick Start deploys a data lake foundation that integrates various AWS Cloud services and components to help you migrate data to the AWS Clou
Data Warehouse Modernization on AWS
This Quick Start helps you deploy a modern enterprise data warehouse (EDW) environment that is based on Amazon Redshift and includes the analytics
Machine Learning with Data Lake Foundation on AWS
The Machine Learning with Data Lake Foundation on Amazon Web Services (AWS) solution integrates with a variety of AWS services to provide a fully
Modern Data Warehouse on AWS
APN Partners help you modernize your data warehouse environments to squeeze out new efficiencies, simplify operations, and accelerate your tim
Building a Software/SaaS Business on AWS – the ISV Partner Playbook from Splunk
The following is a guest post from our friends at Splunk, an all-in AWS Technology Partner, and AWS SaaS Partner. As AWS increasingly bec
Informatica Data Lake on AWS
Informatica’s intelligent data lake management solution significantly reduces the complexity of deploying and deriving value from a data lake on A