
Python編碼問題整理
認識常見編碼
GB2312是中國規定的漢字編碼,也可以說是簡體中文的字符集編碼
GBK 是 GB2312的擴充套件 ,除了相容GB2312外,它還能顯示繁體中文,還有日文的假名
cp936:中文字地系統是Windows中的cmd,預設codepage是CP936,cp936就是指系統裡第936號編碼格式,即GB2312的編碼。
(當然有其它編碼格式:cp950 繁體中文、cp932 日語、cp1250 中歐語言。。。)
Unicode是國際組織制定的可以容納世界上所有文字和符號的字元編碼方案。UTF-8、UTF-16、UTF-32都是將數字轉換到程式資料的編碼方案。
UTF-8 (8-bit Unicode Transformation Format)是最流行的一種對 Unicode 進行傳播和儲存的編碼方式。它用不同的 bytes 來表示每一個程式碼點。ASCII 字元每個只需要用一個 byte ,與 ASCII 的編碼是一樣的。所以說 ASCII 是 UTF-8 的一個子集。
在開發Python程式的過程中,會涉及到三個方面的編碼:
- Python程式檔案的編碼
- Python程式執行時環境(IDE)的編碼
- Python程式讀取外部檔案、網頁的編碼
Python程式檔案的編碼
例如:
Python2自帶的IDE,當建立了一個檔案儲存的時候提示:
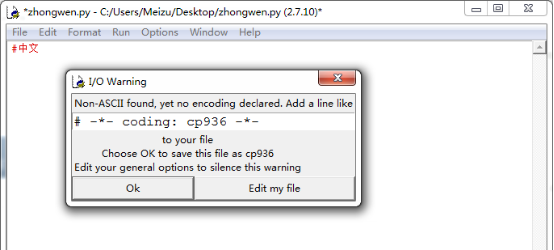
這是因為Python2編輯器預設的編碼是ASCII,它是無法識別中文的,所以會彈出這樣的提示。這也是我們在大多情況下寫python2程式的時候習慣在程式的第一行加上:#coding=utf-8
其實,這裡的編碼檔案是很容易解決的。
Python程式執行時環境(IDE)的編碼
執行下面的一段程式。
#coding=utf-8 from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 返回百度頁面底部備案資訊 text = driver.find_element_by_id("cp").text print(text) driver.close()
在windows cmd下執行:
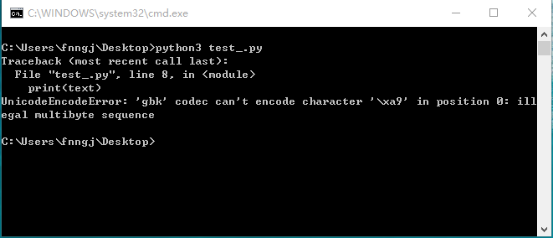
我們要獲取的資訊是:
©2015 Baidu 使用百度前必讀 意見反饋 京ICP證030173號
Windows cmd 用的是cp936,也就是中文的GB2312,在GBK的字符集裡沒有“©”,這就導致通過GBK解析的時候出現編碼問題。
這就像你在翻譯英文的時候,出現了一個單詞,這個單詞你查遍了牛津大詞典都沒找到對應的含義解釋,那麼自然是會有問題的。
那假設,我還就想在cmd下執行這個python程式了,那麼可以去修改cmd的預設編碼型別為utf-8,對應的編碼為CHCP 65001(utf-8)。在cmd 下輸入:chcp 65001 命令回車。
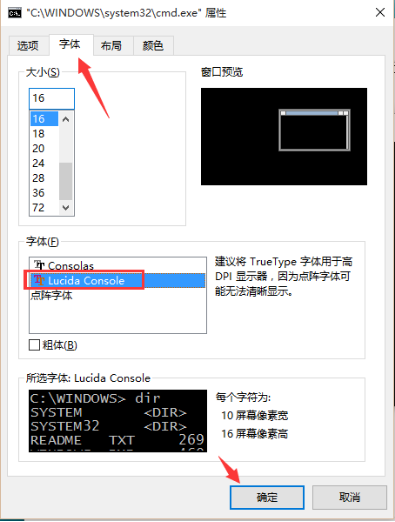
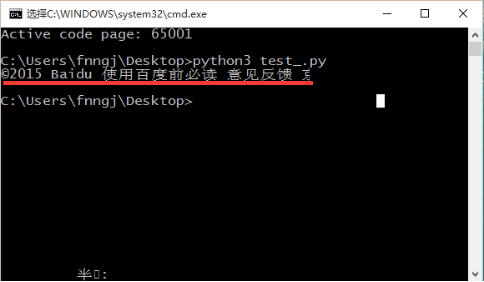
然後,修改cmd的字型為“Lucida Console”,再來執行程式就可以被正確輸出了。
Python程式讀取外部檔案、網頁的編碼
#這一塊,暫時沒有找到合適的例子
檢視Python系統編碼
檢視Python2 或Python3的系統編碼。
Python2:
Python 2.7.10 (default, May 23 2015, 09:40:32) [MSC v.1500 32 bit (Intel)] on win32 Type "copyright", "credits" or "license()" for more information. >>> import sys >>> sys.getdefaultencoding() 'ascii'
Python3:
Python 3.5.0 (v3.5.0:374f501f4567, Sep 13 2015, 02:27:37) [MSC v.1900 64 bit (AMD64)] on win32 Type "copyright", "credits" or "license()" for more information. >>> import sys >>> sys.getdefaultencoding() 'utf-8'
那麼如何修改Python2的系統編碼為urf-8呢?
import sys reload(sys) sys.setdefaultencoding('utf-8')
所以,在你的程式執行的過程中,遇到下面的報錯資訊時。
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1....
可以將上面的三行程式碼加到Python程式的頭部。
decode()與encode()
- decode 的作用是將其他編碼的字串轉換成 Unicode 編碼,eg name.decode(“GB2312”),表示將GB2312編碼的字串name轉換成Unicode編碼。
- encode 的作用是將Unicode編碼轉換成其他編碼的字串,eg name.encode(”GB2312“),表示將GB2312編碼的字串name轉換成GB2312編碼。
例如,前面獲取百度底部資訊的例子。我還可以通過decode()與encode()來解決:
#coding=utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get("http://www.baidu.com") # 返回百度頁面底部備案資訊 text = driver.find_element_by_id("cp").text text2 = text.encode("gbk","ignore").decode("gbk") print(text2)
這裡通過encode()將Unicode編碼轉換成gbk編碼,在轉換的過程中通過“ignore”忽略掉gbk不能識別的字元(©),然後再把gbk轉換成Unicode編碼。當然,這並不是一種完美的方式,畢竟犧牲部分字串。
chardet模組
chardet是一個非常優秀的編碼識別模組。
通過pip 安裝:
>pip install chardet
使用:
>>> from chardet import detect >>> a = "中文" >>> detect(a) {'confidence': 0.682639754276994, 'encoding': 'KOI8-R'}
大概有68%的把握為KOI8-R編碼型別。
相關推薦
PEP8 Python 編碼規範整理[轉]
長度 sys ret 換行 效率 一行 操作 style 命名沖突 PEP8 Python 編碼規範,僅供參考,不必完全遵守。 一 代碼編排1 縮進。4個空格的縮進(編輯器都可以完成此功能),不使用Tab,更不能混合使用Tab和空格。2 每行最大長度79,換行可以使用反斜杠
PEP8 Python 編碼規範整理
都是 深入學習 編程語言 即使 sys 功能 func 下午 函數默認參數 決定開始Python之路了,利用業余時間,爭取更深入學習Python。編程語言不是藝術,而是工作或者說是工具,所以整理並遵循一套編碼規範是十分必要的。所以今天下午我根據PEP 8整理了一份,以後都照
python 編碼規範整理
PEP8 Python 編碼規範 一 程式碼編排 1 縮排。4個空格的縮排(編輯器都可以完成此功能),不要使用Tap,更不能混合使用Tap和空格。 2 每行最大長度79,換行可以使用反斜槓,最好使用圓括號。換行點要在操作符的後邊敲回車。 3 類和top-leve
Python編碼問題整理
認識常見編碼 GB2312是中國規定的漢字編碼,也可以說是簡體中文的字符集編碼 GBK 是 GB2312的擴充套件 ,除了相容GB2312外,它還能顯示繁體中文,還有日文的假名 cp936:中文字地系統是Windows中的cmd,預設codepage是CP936,cp936就是指系統裡第
Python編碼問題整理(好用)
python語句: filea=open("養老補繳明細表.csv", 'r') print("檢測點A", filea, "監測點B") df3=pd.read_csv(filea) print(df3.dtyp
python unicode 編碼整理
unicode 是 character set character set 是把每個字元對應成數字的集合,比如unicode中 A對應0041,漢字『我』對應 ‘6211’ unicode 是個很大的集合,幾乎覆蓋世界上所有的字元,現在的規模已經可以容納100萬個字元。 utf-8 是對 unicode
Python 1 初識python 編碼 註釋
機器碼 作用 程序員 python 1 人性 後綴 命令 裏的 軟件 1.Python介紹 Python是一種高級語言,與JAVA C# 等同。可以編寫各種應用程序,每種語言都有其合適的應用場景。而Python 的優勢在於更加人性化、簡便的語法規則,以及針對各種具體場景
linux之系統編碼,python編碼,文件編碼
python 編碼 文件編碼 linux編碼 1 前言如果你對python2和python3的中編解碼很清楚,這裏我認為你很清楚。具體參考文檔:“python2 encode和decode函數說明.docx”“字符編碼——從ASCII開始.docx”以上所有文檔均為本地文檔。2
python編碼及類型轉換
chardet 只讀 字符串 class log oop 文件 判斷字符串 () 使用chardet模塊來判斷數據的編碼;輸入參數為str類型。 #coding:utf-8 import cchardet f =open(‘hadoop.txt‘,‘r‘) #打開
VS2013+PTVS,python編碼問題
img 編碼 data ood clas ply 描述 技術分享 href 1.調試,input(‘中文‘),亂碼2.調試,print(‘中文‘),正常3.不調試,input(‘中文‘),正常4.不調試,print(‘中文‘),正常 頁面編碼方式已經加了“# -- cod
python 編碼問題:'ascii' codec can't encode characters in position 的解決方案
解釋器 rac python 編碼 att 文件 tde pla pytho net 問題描述: Python在安裝時,默認的編碼是ascii,當程序中出現非ascii編碼時,python的處理常常會報這樣的錯UnicodeDecodeError: ‘ascii‘ co
第三篇.python 編碼的轉換
utf-8 python3 python2 第三篇 pytho pan span 需要 enc !/usr/bin/python2# -*- coding:utf-8 -*-temp = "豬"#解碼,需要指定原來是什麽編碼,解碼成Unicodetemp_unicode =
windows環境下python編碼問題
info 輸出 win python編碼 code aaa 獲得 python 執行命令 log.info(u"你好" + "aaa") os.path.join(u"你好", "aaaa") os.popen((u"你好" + "aaa").encode("GBK"))即
python基礎整理(一)
sci 可變 python break job continue ont mat con 1、字符編碼: ASCIl碼 255個 每個字符一個字節, Unicode 每個字符兩個字節, UTF8 可變長的Unicode編碼,英文一個字節,中文三個字節。 2、格式化字
python 編碼
沒有 示例 ext left com keyword python 編碼 解碼 使用 字符編碼解釋: ASCII,8個bit,1個Byte GB2312,2個Byte,7000多個漢字 GBK,2個Byte,21886個漢字,最常用, GB18030,2個Byt,27484
Python編碼——常見的編碼設置
logs local pen lte n) system port stderr 讀取 1、查看自己電腦的python的編碼設置 # -*- coding: utf8 -*- import sys, locale """ locale.getpreferrede
Python 編碼規範(Google) (轉)
present clas stmt 刪除 規範 實的 things code uno Python 風格規範(Google) 本項目並非 Google 官方項目, 而是由國內程序員憑熱情創建和維護。 如果你關註的是 Google 官方英文版, 請移步 Google St
python編碼問題,從隱隱作痛到除去病根
range 一個 test dev 寫代碼 code 字符 all 不同 查閱的資料鏈接 python編碼為什麽這麽蛋疼 python2.7手冊str函數 python源文件默認編碼與內部默認編碼 1.源文件默認編碼為ASCII,所以,如果不顯示聲明當前代碼用什麽編
Python 編碼
其他 常見 python3 操作系統 網絡傳輸 聲明 keyword 文件頭 特殊字符 .編碼類型: ASCII 占1個字節,只支持英文 GB2312 占2個字節,支持6700+漢字 GBK GB2312的升級版,支持21000+漢字 Shift-JIS 日本字符 k
python編碼
數據 asc 通過 -m 所有 文字 計算 nco pre python在內存中對所有數據都是ascii碼存儲的 所有要解析出來 你首頁要 把當前計算的的編碼告訴Python 如 #python2 s = "你好" #假如你計算機當前編碼是gbk 要想轉換成utf8 s.