
2線性分類器基本原理-2.3線性分類器之SoftMax和交叉熵損失(Cross-Entropy)
影象分類器模型的整體結構:
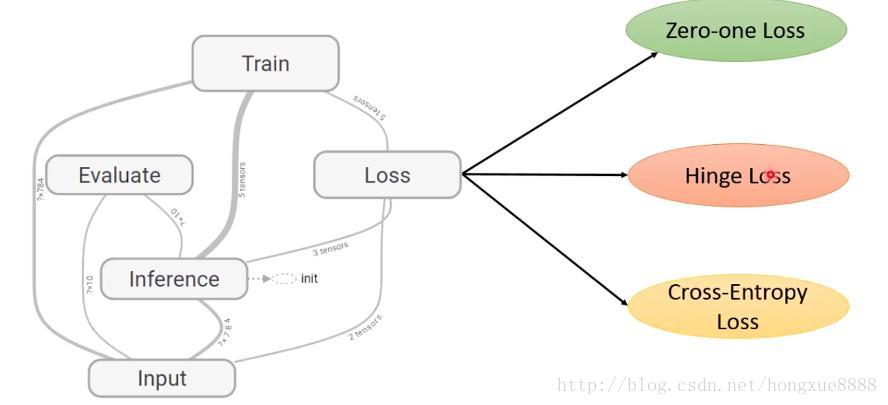
交叉熵(Cross-Entropy)損失 和 SoftMax
SVM是最常用的兩個分類器之一,而另一個就是Softmax分類器,它的損失函式與SVM損失函式不同。對於學習過二元邏輯迴歸分類器的讀者來說,SoftMax分類器就可以理解為邏輯迴歸分類器面對多個分類的一般化歸納。SVM將輸出
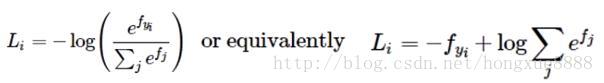
在上式中,使用
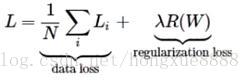
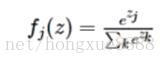
(參考:https://en.wikipedia.org/wiki/Softmax_function)
被稱為softmax函式:其輸入值是一個向量,向量中元素為任意實數的評分值(z中的),函式對其進行壓縮,輸出一個向量,其中每個元素值在0到1之間,且所有元素之和為1。所以,包含softmax函式的完整交叉熵損失看起來唬人,實際上還是比較容易理解的。
資訊理論視角:在“真實”分佈p和估計分佈q之間的交叉熵定義如下:
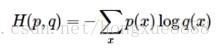
。。。
讓人迷惑的命名規則:
精確的說,SVM分類器使用的是折葉損失(hinge loss),有時候又被稱為最大邊界損失(max-margin loss)。Softmax分類器使用的是交叉熵損失(cross-entropy loss)。Softmax分類器的命名是從softmax函式那裡得到的,softmax函式將原始分類評分變成正的歸一化數值,所有數值和為1,這樣處理後交叉熵損失才能應用。注意從技術說“softmax損失(softmax loss)”是沒有意義的,因為softmax只是一個壓縮數值的函式。但是在這個說法常常被用來簡稱。
SVM 和 Softmax比較:
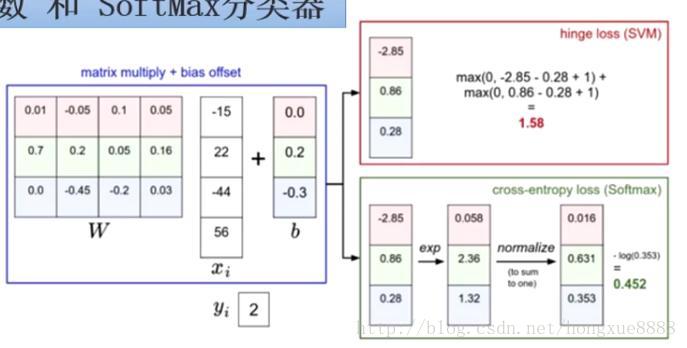
針對一個數據點,SVM和Softmax分類器的不同處理方式的例子。兩個分類器都計算了同樣的分值向量f(本節中是通過矩陣乘來實現)。不同之處在於對f中分值的解釋:SVM分類器將他們看做是分類評分,它的損失函式鼓勵正確的分類(本例中藍色的類別2)的分值比其他分類的分值高出至少一個邊界值。Softmax分類器將這些數值看做是每個分類沒有歸一化的對數概率
Softmax分類器為每個分類提供了“可能性”:SVM的計算式無標定的,而且難以針對所有分類的評分值給出直觀解釋。Softmax分類器則不同,它允許我們計算出對於所有分類標籤的可能性。舉個例子,針對給出的影象,SVM分類器可能給你的是一個[12.5,0.6,-23.0]對應分類“貓”、“狗”,“船”。而softmax分類器可以計算出這三個標籤的“可能性”是[0.9,0.09,0.01],這就讓你能看出對於不同分類準確性的把握。為什麼我們要在“可能性”上面打引號呢?這是因為可能性分佈的集中或離散程度是由正則化引數
現在,如果正則化引數
現在看起來,概率的分佈就更加分散了。還有,隨著正則化引數
在實際使用中,SVM和Softmax經常是相似的:
通常說來,兩種分類器的表現差別很小,不同的人對於哪個分類器更好有不同的看法。相對於Softmax分類器,SVM更加“區域性目標化(local objective)”,這既可以看做是一個特性,也可以看做是一個劣勢。考慮一個評分是[10,-2,3]的資料,其中第一個分類是正確的。那麼一個SVM(
對於softmax分類器,情況則不同。對於[10,9,9]來說,計算出的損失值就遠遠高於[10,-100,-100]的。換句話說,softmax分類器對於分數是永遠不會滿意的:正確分類總能得到更高的可能性,錯誤分類總能得到更低的可能性,損失值總是能夠更小。但是,SVM只要邊界值被滿足了就滿意了,不會超過限制去細微的操作具體分數。這可以被看做是SVM的一種特性。舉例說來,一個汽車的分類器應該把他的大量精力放在如何分辨小轎車和大卡車上,而不應該糾結於如何與青蛙進行區分,因為區分青蛙得到的評分已經足夠低了。
章末小節:
- 定義了從影象畫素對映到不同類別的分類評分的評分函式。在本節中,評分函式是一個基於權重W和偏差b的線性函式。
- 與KNN分類器不同,引數方法的優勢在於一旦通過訓練學習到了引數,就可以將訓練資料丟棄了。同時該方法對於心得測試資料的預測非常快,因為只需要與權重W進行一個矩陣乘法運算。
- 介紹了偏差技巧,讓我們能夠將偏差向量和權重矩陣合二為一,然後就可以只跟蹤一個矩陣。
定義了損失函式(介紹了SVM和Softmax線性分類器最常用的2個損失函式)。損失函式能夠衡量給出的引數集和訓練集資料真實類別情況之間的一致性。在損失函式的定義中可以看到,對於訓練集資料做出良好預測與得到一個足夠低的損失值這兩件事是等價的。
現在我們知道了如何基於引數,將資料集中的影象對映成為分類的評分,也知道了兩種不同的損失函式,他們都能用來衡量演算法分類預測的質量。但是,如何高效地得到能夠使損失值最小的引數呢?這個求得最優引數的過程被稱為最優化,將在下節介紹。
相關推薦
2線性分類器基本原理-2.3線性分類器之SoftMax和交叉熵損失(Cross-Entropy)
影象分類器模型的整體結構: 交叉熵(Cross-Entropy)損失 和 SoftMax SVM是最常用的兩個分類器之一,而另一個就是Softmax分類器,它的損失函式與SVM損失函式不同。對於學習過二元邏輯迴歸分類器的讀者來說,SoftMax分類器就可
【苦讀官方文檔】2.Android應用程序基本原理概述
project 做出 系統默認 體驗 告訴 sta 執行過程 顏色 硬件配置 官方文檔原文地址 應用程序原理 Android應用程序是通過Java編程語言來寫。Android軟件開發工具把你的代碼和其它數據、資源文件一起編譯、打包成一個APK文件
爬蟲基本原理2
alt option mongo 種類型 瀏覽器 get 部分 json 頭部 什麽是爬? 請求?網站並提取數據的?自動化程序 爬蟲的基本流程 發起請求 通過HTTP庫向?目標站點發起請求,即發送?個Request,請求可以包含額外的headers等信息,等待服務器
4.2 門電路的基本原理
知識 與或非 感嘆號 電源 關閉 中一 5.4 了解 把手 計算機組成 4 算術邏輯單元 4.2 門電路的基本原理 現代計算機的CPU和其它很多功能部件都是基於晶體管的集成電路,想要了解計算機組成的基本原理,還是需要有一些集成電路的基本知識。就讓我們從最簡單的門電路的實現
hadoop-2.X HA的基本原理
1 概述 在hadoop2.0之前,namenode只有一個,存在單點問題(雖然hadoop1.0有secondarynamenode,checkpointnode,buckcupnode這些,但是單點問題依然存在),在hadoop2.0引入了HA機制。hadoop2.0的HA機制官方介紹了有2種方
裝飾器基本原理
put *args raw sleep 因此 實參 eas 函數的調用 username #coding=utf-8 #裝飾器本質為函數(用來裝飾其他函數)為其他函數添加附加功能 #原則:1、不能修改被裝飾函數的源代碼 #2、不能修改函數的調用方式 #實現裝飾器 #1、函
Spring核心技術原理-(3)-Spring歷史版本變遷和如今的生態帝國
前幾篇: 前兩篇從Web開發史的角度介紹了我們在開發的時候遇到的一個個坑,然後一步步衍生出Spring Ioc和Spring AOP的概念雛形。Spring從2004年第一個正式版1.0 Final Released發展至今,儼然已經成為了一個生態帝國
css_day02_各種選擇器基本使用(相鄰兄弟選擇器+,兄弟選擇器~)
1.交集選擇器 格式: 選擇器1選擇器2{ } 效果: 2.並集選擇器 . . . . . . . . . . <———————————-華
【深度學習原理】交叉熵損失函式的實現
交叉熵損失函式 一般我們學習交叉熵損失函式是在二元分類情況下: L = −
直觀理解為什麼分類問題用交叉熵損失而不用均方誤差損失?
目錄 交叉熵損失與均方誤差損失 損失函式角度 softmax反向傳播角度 參考 部落格:blog.shinelee.me | 部落格園 | CSDN 交叉熵損失與均方誤差損失 常
自己動手實現深度學習框架-4 使用交叉熵損失函式支援分類任務
程式碼倉庫: https://github.com/brandonlyg/cute-dl 目標 增加交叉熵損失函式,使框架能夠支援分類任務的模型。 構建一個MLP模型, 在mnist資料集上執行分類任務準確率達到91%。 實現交叉熵損失函式 數學原理 分解交叉熵損失函式 &n
易學筆記-系統分析師考試-第3章 作業系統基本原理/3.3 記憶體管理/3.3.2 分割槽儲存管理
記憶體儲存管理方式分類 分割槽儲存管理方式 分頁式儲存管理方式 分段式儲存管理方式 虛擬儲存器 分割槽儲存管理方式 固定分割槽 分割槽方法:在裝入作業前,記憶體被操作管理員分為N個區,分割槽大小和分割槽數量不可以修改
易學筆記-系統分析師考試-第3章 作業系統基本原理/3.2 程序管理/3.2.3 死鎖問題
死鎖 概念:兩個程序A與B都需要一個資源a,當程序A佔用資源a時,同時又申請程序B正在佔用的資源b,這時候程序A需要資源b,程序B需要資源a,這樣就進入了一個相互等待狀態,這種狀態成為死鎖 產生原因 系統資源不夠 互斥資源的共享 併發執
易學筆記-系統分析師考試-第3章 作業系統基本原理/3.2 程序管理/3.2.2 訊號量與PV操作
程序制約方式 間接相互制約:也稱為程序互斥;程序A與程序B都需要資源C(例如印表機),系統已將C分配給A使用,等待A使用完成後系統再將C分配給B使用 直接相互制約:也稱為程序同步;A通過緩衝區向B提供資料,當緩衝區為空時B不能獲取資料而阻塞;當A把資料放入緩衝區後B將被喚醒
易學筆記-系統分析師考試-第3章 作業系統基本原理/3.2 程序管理/3.2.1 程序的狀態
程序 概念:是資料集合的一次並行執行的執行活動,是系統進行資源分配和排程的最基本單位 特點 動態性:與程式對比,它是動態的,程式是靜態的 併發性:允許多個同時進行 資源性:需要排程系統的資源,包括記憶體、檔案、I/O裝置等
2.常用演算法(推導) 演算法分類,演算法原理,演算法設計,推導---SVM,DTree,樸素貝葉斯,線性迴歸等;
演算法: 以wx+b=0為基礎的演算法: 感知機->誤分點(xi,yi | i->m)到wx+b的距離和最小,求最優解; 支援向量機->最大間隔; 邏輯迴歸->將wx+b的值作為邏輯函式輸入,進行分類; 線性迴歸->勾畫線性曲線,對
二維碼資料 目錄 1. 二維碼QR Code 1 2. 發展歷程 1 3. 特點 2 4. 儲存 3 5. 分類 3 5.1.1. 按原理分 3 6. 區別 與條碼區別 5 7. 什麼是碼制?
二維碼資料 目錄 1. 二維碼QR Code 1 2. 發展歷程 1 3. 特點 2 4. 儲存 3 5. 分類 3 5.1.1. 按原理分 3 6. 區別 與條碼區別 5 7. 什麼是碼制?Q
易學筆記-系統分析師考試-第3章 作業系統基本原理/3.4 檔案管理/3.4.2 儲存空間管理
易學筆記 十年IT經驗個人學習筆記分享: 開發語言:C/C++/JAVA/PYTHON/GO/JSP WEB架構:Servlets/springMVC/springBoot/springClound 容器架構:Docker容器/Docker叢集/Docker與微服務整合/
數據結構(嚴蔚敏、吳偉民)——讀書筆記-2、 線性表及其基本運算、順序存儲結構
content pri 線性 時間復雜度 length 將他 ron 個數 p s 第二章 線性表 2.1 線性表及其基本運算 2.2 線性表的順序存儲結構 2.3 線性表的鏈式存儲結構 1、線性表:是n個數據元素的有限序列。
3.2《深入理解計算機系統》筆記(二)內存和高速緩存的原理【插圖】
img sram 本質 text ddr rate too 是我 很大的 《深入計算機系統》筆記(一)主要是講解程序的構成、執行和控制。接下來就是運行了。我跳過了“處理器體系結構”和“優化程序性能”,這兩章的筆記繼續往後延遲! 《深入計算機系統》的一個很大的用處