
Run Mixed Workloads with Amazon Redshift Workload Management
Mixed workloads run batch and interactive workloads (short-running and long-running queries or reports) concurrently to support business needs or demand. Typically, managing and configuring mixed workloads requires a thorough understanding of access patterns, how the system resources are being used and performance requirements.
It’s common for mixed workloads to have some processes that require higher priority than others. Sometimes, this means a certain job must complete within a given SLA. Other times, this means you only want to prevent a non-critical reporting workload from consuming too many cluster resources at any one time.
Without workload management (WLM), each query is prioritized equally, which can cause a person, team, or workload to consume excessive cluster resources for a process which isn’t as valuable as other more business-critical jobs.
This post provides guidelines on common WLM patterns and shows how you can use WLM query insights to optimize configuration in production workloads.
Workload concepts
You can use WLM to define the separation of business concerns and to prioritize the different types of concurrently running queries in the system:
- Interactive: Software that accepts input from humans as it runs. Interactive software includes most popular programs, such as BI tools or reporting applications.
- Short-running, read-only user queries such as Tableau dashboard query with low latency requirements.
- Long-running, read-only user queries such as a complex structured report that aggregates the last 10 years of sales data.
- Batch: Execution of a job series in a server program without manual intervention (non-interactive). The execution of a series of programs, on a set or “batch” of inputs, rather than a single input, would instead be a custom job.
- Batch queries includes bulk INSERT, UPDATE, and DELETE transactions, for example, ETL or ELT programs.
Amazon Redshift Workload Management
Amazon Redshift is a fully managed, petabyte scale, columnar, massively parallel data warehouse that offers scalability, security and high performance. Amazon Redshift provides an industry standard JDBC/ODBC driver interface, which allows customers to connect their existing business intelligence tools and re-use existing analytics queries.
Amazon Redshift is a good fit for any type of analytical data model, for example, star and snowflake schemas, or simple de-normalized tables.
Managing workloads
Amazon Redshift Workload Management allows you to manage workloads of various sizes and complexity for specific environments. Parameter groups contain WLM configuration, which determines how many query queues are available for processing and how queries are routed to those queues. The default parameter group settings are not configurable. Create a custom parameter group to modify the settings in that group, and then associate it with your cluster. The following settings can be configured:
- How many queries can run concurrently in each queue
- How much memory is allocated among the queues
- How queries are routed to queues, based on criteria such as the user who is running the query or a query label
- Query timeout settings for a queue
When the user runs a query, WLM assigns the query to the first matching queue and executes rules based on the WLM configuration. For more information about WLM query queues, concurrency, user groups, query groups, timeout configuration, and queue hopping capability, see Defining Query Queues. For more information about the configuration properties that can be changed dynamically, see WLM Dynamic and Static Configuration Properties.
For example, the WLM configuration in the following screenshot has three queues to support ETL, BI, and other users. ETL jobs are assigned to the long-running queue and BI queries to the short-running queue. Other user queries are executed in the default queue.

Guidelines on WLM optimal cluster configuration
1. Separate the business concerns and run queries independently from each other
Create independent queues to support different business processes, such as dashboard queries and ETL. For example, creating a separate queue for one-time queries would be a good solution so that they don’t block more important ETL jobs.
Additionally, because faster queries typically use a smaller amount of memory, you can set a low percentage for WLM memory percent to use for that one-time user queue or query group.
2. Rotate the concurrency and memory allocations based on the access patterns (if applicable)
In traditional data management, ETL jobs pull the data from the source systems in a specific batch window, transform, and then load the data into the target data warehouse. In this approach, you can allocate more concurrency and memory to the BI_USER group and very limited resources to ETL_USER during business hours. After hours, you can dynamically allocate or switch the resources to ETL_USER without rebooting the cluster so that heavy, resource-intensive jobs complete very quickly.
Note: The example AWS CLI command is shown on several lines for demonstration purposes. Actual commands should not have line breaks and must be submitted as a single line. The following JSON configuration requires escaped quotes.

To change WLM settings dynamically, AWS recommends a scheduled Lambda function or scheduled data pipeline (ShellCmd).
3. Use queue hopping to optimize or support mixed workload (ETL and BI workload) continuously
WLM queue hopping allows read-only queries (BI_USER queries) to move from one queue to another queue without cancelling them completely. For example, as shown in the following screenshot, you can create two queues—one with a 60-second timeout for interactive queries and another with no timeout for batch queries—and add the same user group, BI_USER, to each queue. WLM automatically re-routes any only BI_USER timed-out queries in the interactive queue to the batch queue and restarts them.
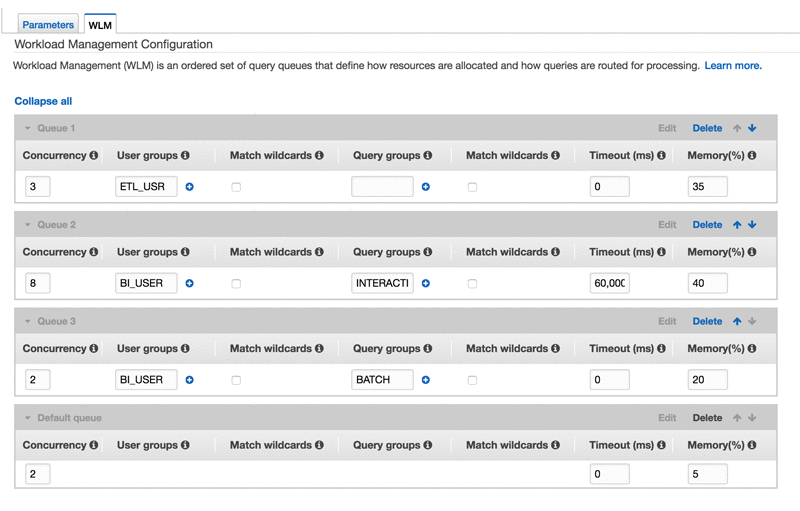
In this example, the ETL workload does not block the BI workload queries and the BI workload is eventually classified as batch, so that long-running, read-only queries do not block the execution of quick-running queries from the same user group.
4. Increase the slot count temporarily for resource-intensive ETL or batch queries
Amazon Redshift writes intermediate results to the disk to help prevent out-of-memory errors, but the disk I/O can degrade the performance. The following query shows if any active queries are currently running on disk:
SELECT query, label, is_diskbased FROM svv_query_state
WHERE is_diskbased = 't';Query results:
query | label | is_diskbased
-------+--------------+--------------
1025 | hash tbl=142 | tTypically, hashes, aggregates, and sort operators are likely to write data to disk if the system doesn’t have enough memory allocated for query processing. To fix this issue, allocate more memory to the query by temporarily increasing the number of query slots that it uses. For example, a queue with a concurrency level of 4 has 4 slots. When the slot count is set to 4, a single query uses the entire available memory of that queue. Note that assigning several slots to one query consumes the concurrency and blocks other queries from being able to run.
In the following example, I set the slot count to 4 before running the query and then reset the slot count back to 1 after the query finishes.
set wlm_query_slot_count to 4;
select
p_brand,
p_type,
p_size,
count(distinct ps_suppkey) as supplier_cnt
from
partsupp,
part
where
p_partkey = ps_partkey
and p_brand <> 'Brand#21'
and p_type not like 'LARGE POLISHED%'
and p_size in (26, 40, 28, 23, 17, 41, 2, 20)
and ps_suppkey not in (
select
s_suppk
from
supplier
where
s_comment like '%Customer%Complaints%'
)
group by
p_brand,
p_type,
p_size
order by
supplier_cnt desc,
p_brand,
p_type,
p_size;
set wlm_query_slot_count to 1; -- after query completion, resetting slot count back to 1
Note: The above TPC data set query is used for illustration purposes only.
Example insights from WLM queries
The following example queries can help answer questions you might have about your workloads:
- What is the current query queue configuration? What is the number of query slots and the time out defined for each queue?
- How many queries are executed, queued and executing per query queue?
- What is my workload look like for each query queue per hour? Do I need to change my configuration based on the load?
- How is my existing WLM configuration working? What query queues should be optimized to meet the business demand?
WLM configures query queues according to internally-defined WLM service classes. The terms queue and service class are often used interchangeably in the system tables.
Amazon Redshift creates several internal queues according to these service classes along with the queues defined in the WLM configuration. Each service class has a unique ID. Service classes 1-4 are reserved for system use and the superuser queue uses service class 5. User-defined queues use service class 6 and greater.
Query: Existing WLM configuration
Run the following query to check the existing WLM configuration. Four queues are configured and every queue is assigned to a number. In the query, queue number is mapped to service_class (Queue #1 => ETL_USER=>Service class 6) with the evictable flag set to false (no query timeout defined).
select service_class, num_query_tasks, evictable, eviction_threshold, name
from stv_wlm_service_class_config
where service_class > 5;
The query above provides information about the current WLM configuration. This query can be automated using Lambda and send notifications to the operations team whenever there is a change to WLM.
Query: Queue state
Run the following query to monitor the state of the queues, the memory allocation for each queue and the number of queries executed in each queue. The query provides information about the custom queues and the superuser queue.
select config.service_class, config.name
, trim (class.condition) as description
, config.num_query_tasks as slots
, config.max_execution_time as max_time
, state.num_queued_queries queued
, state.num_executing_queries executing
, state.num_executed_queries executed
from
STV_WLM_CLASSIFICATION_CONFIG class,
STV_WLM_SERVICE_CLASS_CONFIG config,
STV_WLM_SERVICE_CLASS_STATE state
where
class.action_service_class = config.service_class
and class.action_service_class = state.service_class
and config.service_class > 5
order by config.service_class;
Service class 9 is not being used in the above results. This would allow you to configure minimum possible resources (concurrency and memory) for default queue. Service class 6, etl_group, has executed more queries so you may configure or re-assign more memory and concurrency for this group.
Query: After the last cluster restart
The following query shows the number of queries that are either executing or have completed executing by service class after the last cluster restart.
select service_class, num_executing_queries, num_executed_queries
from stv_wlm_service_class_state
where service_class >5
order by service_class;
Service class 9 is not being used in the above results. Service class 6, etl_group, has executed more queries than any other service class. You may want configure more memory and concurrency for this group to speed up query processing.
Query: Hourly workload for each WLM query queue
The following query returns the hourly workload for each WLM query queue. Use this query to fine-tune WLM queues that contain too many or too few slots, resulting in WLM queuing or unutilized cluster memory. You can copy this query (wlm_apex_hourly.sql) from the amazon-redshift-utils GitHub repo.
WITH
-- Replace STL_SCAN in generate_dt_series with another table which has > 604800 rows if STL_SCAN does not
generate_dt_series AS (select sysdate - (n * interval '1 second') as dt from (select row_number() over () as n from stl_scan limit 604800)),
apex AS (SELECT iq.dt, iq.service_class, iq.num_query_tasks, count(iq.slot_count) as service_class_queries, sum(iq.slot_count) as service_class_slots
FROM
(select gds.dt, wq.service_class, wscc.num_query_tasks, wq.slot_count
FROM stl_wlm_query wq
JOIN stv_wlm_service_class_config wscc ON (wscc.service_class = wq.service_class AND wscc.service_class > 4)
JOIN generate_dt_series gds ON (wq.service_class_start_time <= gds.dt AND wq.service_class_end_time > gds.dt)
WHERE wq.userid > 1 AND wq.service_class > 4) iq
GROUP BY iq.dt, iq.service_class, iq.num_query_tasks),
maxes as (SELECT apex.service_class, trunc(apex.dt) as d, date_part(h,apex.dt) as dt_h, max(service_class_slots) max_service_class_slots
from apex group by apex.service_class, apex.dt, date_part(h,apex.dt))
SELECT apex.service_class, apex.num_query_tasks as max_wlm_concurrency, maxes.d as day, maxes.dt_h || ':00 - ' || maxes.dt_h || ':59' as hour, MAX(apex.service_class_slots) as max_service_class_slots
FROM apex
JOIN maxes ON (apex.service_class = maxes.service_class AND apex.service_class_slots = maxes.max_service_class_slots)
GROUP BY apex.service_class, apex.num_query_tasks, maxes.d, maxes.dt_h
ORDER BY apex.service_class, maxes.d, maxes.dt_h;For the purposes of this post, the results are broken down by service class.

In the above results, service class#6 seems to be utilized consistently up to 8 slots in 24 hrs. Looking at these numbers, no change is required for this service class at this point.

Service class#7 can be optimized based on the above results. Two observations to note:
- 6am- 3pm or 6pm- 6am (next day): The maximum number of slots used is 3. There is an opportunity to rotate concurrency and memory allocation based on these access patterns. For more information about how to rotate resources dynamically, see the guidelines section earlier in the post.
- 3pm-6pm: Peak is observed during this period. You can leave the existing configuration during this time.
Summary
Amazon Redshift is a powerful, fully managed data warehouse that can offer significantly increased performance and lower cost in the cloud. Using the WLM feature, you can ensure that different users and processes running on the cluster receive the appropriate amount of resource to maximize performance and throughput.
If you have questions or suggestions, please leave a comment below.
About the Author
 Suresh Akena is a Senior Big Data/IT Transformation Architect for AWS Professional Services. He works with the enterprise customers to provide leadership on large scale data strategies including migration to AWS platform, big data and analytics projects and help them to optimize and improve time to market for data driven applications when using AWS. In his spare time, he likes to play with his 8 and 3 year old daughters and watch movies.
Suresh Akena is a Senior Big Data/IT Transformation Architect for AWS Professional Services. He works with the enterprise customers to provide leadership on large scale data strategies including migration to AWS platform, big data and analytics projects and help them to optimize and improve time to market for data driven applications when using AWS. In his spare time, he likes to play with his 8 and 3 year old daughters and watch movies.
Related
相關推薦
Run Mixed Workloads with Amazon Redshift Workload Management
Mixed workloads run batch and interactive workloads (short-running and long-running queries or reports) concurrently to support business
Narrativ is helping producers monetize their digital content with Amazon Redshift
Narrativ, in their own words: Narrativ is building monetization technology for the next generation of digital content producers. Our product portf
Modernize Your Data Warehouse with Amazon Redshift
Data in every organization is growing in volume and complexity faster than ever. Yet, only a small fraction of this invaluable asset is available
How to Troubleshoot High or Full Disk Usage with Amazon Redshift
SELECT q.query, trim(q.cat_text) FROM ( SELECT query, replace( listagg(text,' ') WITHIN GROUP (ORDER BY sequence), '\\n', ' ') AS cat_text FROM
Amazon Redshift Data Warehouse with Matillion ETL on AWS
AWS offers a common architectural structure that enables you to leverage new and existing big data technologies and data warehouse methods. Throug
Managing Application Workloads with Database Services
procedure middle req evel osi oge contains nds ice Managing Application Workloads with Database Services This section contains: About
spring boot 新建專案後執行有錯To display the conditions report re-run your application with 'debug' enabled.
錯誤: ror starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled. 2018-10-19 20:42:26.6
Error starting ApplicationContext. To display the conditions report re-run your application with 'de
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'upHomeController': Unsatisfied d
Segmenting brain tissue using Apache MXNet with Amazon SageMaker and AWS Greengrass ML Inference
In Part 1 of this blog post, we demonstrated how to train and deploy neural networks to automatically segment brain tissue from an MRI scan in a s
How Annalect built an event log data analytics solution using Amazon Redshift
Ingesting and analyzing event log data into a data warehouse in near real-time is challenging. Data ingest must be fast and efficient. The data wa
Tutorial for building a Web Application with Amazon S3, Lambda, DynamoDB and API Gateway
Tutorial for building a Web Application with Amazon S3, Lambda, DynamoDB and API GatewayI recently attended Serverless Day at the AWS Loft in downtown San
How Will Google Shopping Compete With Amazon? With Sci
This story is for Medium members.Continue with FacebookContinue with GoogleMedium curates expert stories from leading publishers exclusively for members (w
Save time and money by filtering faces during indexing with Amazon Rekognition
Amazon Rekognition is a deep-learning-based image and video analysis service that can identify objects, people, text, scenes, and activities, as w
How SimilarWeb analyze hundreds of terabytes of data every month with Amazon Athena and Upsolver
This is a guest post by Yossi Wasserman, a data collection & innovation team leader at Similar Web. SimilarWeb, in their own words: Si
Quickly Filter Data in Amazon Redshift Using Interleaved Sorting
My colleague Tina Adams sent a guest post to introduce another cool and powerful feature for Amazon Redshift. — Jeff; Ama
Amazon Redshift Pricing
Reserved Instances (a.k.a. Reserved Nodes) are appropriate for steady-state production workloads, and offer significant discounts over On-Deman
啟動錯誤事件:“NLB 群集 0.0.0.0 : 由於引數錯誤 和 Error with Microsoft Firewall Client Management
1.錯誤:NLB 群集 0.0.0.0 : 由於引數錯誤,群集模式無法被啟用。所有通訊都會被傳遞給 TCP/IP。在執行 'wlbs reload' 後執行 'wlbs start' 糾正問題後,重新啟動群集操作。” 因為裝了Microsoft Firewall Clien
Using Amazon Redshift for Fast Analytical Reports
With digital data growing at an incomprehensible rate, enterprises are finding it difficult to ingest, store, and analyze the data quickly while k
Authenticate Using AWS Directory Service with Amazon QuickSight
Amazon Web Services is Hiring. Amazon Web Services (AWS) is a dynamic, growing business unit within Amazon.com. We are currently hiring So