
Using Amazon Redshift for Fast Analytical Reports
With digital data growing at an incomprehensible rate, enterprises are finding it difficult to ingest, store, and analyze the data quickly while keeping costs low. Traditional data warehouse systems need constant upgrades in terms of compute and storage to meet these challenges.
In this post, we provide insights into how AWS Premier Partner Wipro helped their customer (a leading US business services company) move their workload from on-premise data warehouse to
Current data warehouse environment and challenges faced
The customer was running commercial enterprise data warehouse that contained aggregated data from different internal reporting systems across geographies. Their primary goal was to provide quick and accurate analytics to drive faster business decisions. The user base was distributed globally. Meeting this goal was difficult due to the following challenges:
- The data warehouse (5 TB) was growing at over 20 percent year over year (YoY), with higher growth expected in the future. This growth required them to keep upgrading the hardware to meet the storage and compute needs, which was expensive.
- The Analytical Dashboard experienced performance issues because of the growing data and user base.
- Licensing was based on CPU cores, so adding hardware to support the growth also required additional investment in licenses, further spiraling the costs.
Migrating to Amazon Redshift
Wipro used their Cloud Data Warehouse Readiness Solution (CDRS) strategy to migrate data to Amazon Redshift. Using CDRS, they migrated 4.x billion records to Amazon Redshift. CDRS has a Source Analyzer that created the target data model and generated the data definition language (DDL) for tables that needed to be migrated to Amazon Redshift. The architecture included Talend (a data integration platform) running on Amazon EC2 to extract data from various source systems for ongoing change data capture (CDC) and then load it to Amazon Redshift. Talend has several built-in connectors to connect to various sources and extract the data.
The following diagram shows the architecture of this migration setup:
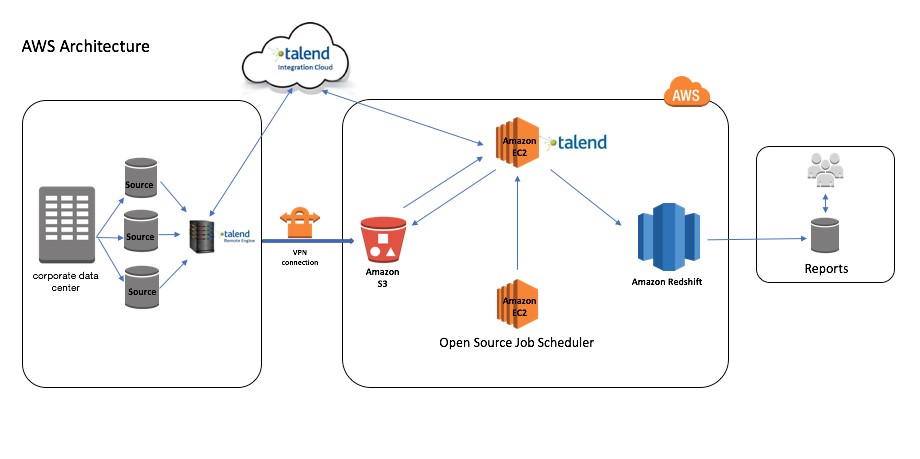
AWS also offers other technologies, like AWS Database Migration Service (AWS DMS) and AWS Schema Conversion Tool (AWS SCT), to migrate your data to and from most widely used commercial and open-source databases and data warehouses. Customers use AWS SCT to convert and migrate their schema objects (table definitions, indexes, triggers, and other execution logic) from legacy data warehouse platforms. They use the AWS SCT data extraction agents to migrate Oracle, Microsoft SQL Server, Teradata, IBM Netezza, Greenplum, and Vertica to Amazon Redshift. For more information, see the following posts:
The AWS data warehouse consisted of three node Amazon Redshift clusters using dc1.8xlarge instances. After migration, queries showed a 2.5x performance improvement compared to an on-premises environment. They also realized a 5x performance improvement while loading data to big tables. The following table lists the data load time for big or complex tables for the two environments.
| Table | Load time (sec) | End-to-end time (sec) | |||||
| On-premises | Amazon Redshift | Improvement | On-premises | Amazon Redshift | Improvement | ||
| Table 1 | 617 | 129 | 5x | 732 | 320 | 2x | |
| Table 2 | 1766 | 184 | 9x | 1767 | 305 | 6x | |
| Table 3 | 308 | 63 | 5x | 309 | 130 | 2x | |
| Table 4 | 154 | 102 | 1.5x | 2115 | 2126 | 0x | |
Setting up an analytical reporting data warehouse on Amazon Redshift
The on-premises data warehouse environment was an extension of the transactional system. Analytical queries experienced performance issues when they were executed against large datasets because queries scanned wide row-based blocks of data that were ultimately discarded in the end SQL results. Customers reporting queries on an average took 152 seconds for execution, and it impacted the interactive experience for their dashboards. With data growing by 20 percent YoY, the query performance further degraded. The customer realized a need for a dedicated analytical environment to address the performance and scale issues for user reports.
Amazon Redshift was identified as the ideal solution for setting up this new analytical reporting environment. The following are the key guidelines and best practices that were followed while migrating to Amazon Redshift:
- Tables were encoded using the
COPYcommandAUTOfeature to reduce the I/O spend by analytical queries. - The analytical queries used date ranges to query the large FACT tables (which took 40 percent of the total database size). The FACT tables were set up using the
dataset_datecolumn as theSORTThis allows the pruning of blocks when the SQL scans the data, and further optimizing the I/O. - The dimension tables were set up with
DIST ALLto avoid theDS_BCAST_INNERandDS_DIST_BOTHdata broadcast in the SQL joins. - Amazon Redshift
ANALYZEwas executed as the pre-ultimate step in the ETL (extract, transform, and load) data loading so that reporting end-user queries benefited by an optimal execution plan. - On an average, 20 percent of the data changed weekly.
VACUUMwas scheduled as a weekly job to re-sort the time series FACT tables and claim the deleted blocks to avoid theDELETED BLOCK SCAN. STL_EVENTSandSTL_SCANtables were used to identify and prioritize tables that neededVACUUM.
The following table shows the performance impact between the two environments. On an average, there was a 8x improvement in query execution time with six queries running in parallel.
| Report names | On-premises (sec) | AWS prod (sec) | Improvement |
| Report 1 | 481 | 176 | 3x |
| Report 2 | 310 | 59 | 5x |
| Report 3 | 208 | 7 | 29x |
| Report 4 | 763 | 210 | 3x |
| Report 5 | 630 | 193 | 3x |
| Report 6 | 748 | 207 | 4x |
Cost benefits
By migrating to Amazon Redshift, the customer saw an 83 percent reduction in their operational expenses over a period of three years. Their current license, hardware, and software costs attributed to approximately $750K per year. But using the three-year Reserved Instances (RI) feature, they were able to bring down the operating cost to $133K per year. For information about this data warehousing environment, see the AWS Simple Monthly Calculator.
Conclusion
Using Amazon Redshift, the customer saw immediate performance improvements at significantly lower costs. Data users were able to query and obtain reports quickly using column-level compression and massively parallel processing (MPP) features of Amazon Redshift. This migration also enabled the customer to be more agile with their data warehouse infrastructure—relieving them of the burden of planning additional licensing costs and effort for software and hardware upgrades. Finally, using the broad partner ecosystem in AWS, customers can accelerate their cloud journey and solve many business-critical challenges.
About the Authors
 Vivek Raju is a partner solutions architect at Amazon Web Services. He works with our partners to provide guidance and technical assistance on migration projects, helping them improving the value of their solutions when using AWS. In his spare time, loves to cook and play volleyball.
Vivek Raju is a partner solutions architect at Amazon Web Services. He works with our partners to provide guidance and technical assistance on migration projects, helping them improving the value of their solutions when using AWS. In his spare time, loves to cook and play volleyball.
 Thiyagarajan Arumugam is a Big Data Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
Thiyagarajan Arumugam is a Big Data Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
相關推薦
Using Amazon Redshift for Fast Analytical Reports
With digital data growing at an incomprehensible rate, enterprises are finding it difficult to ingest, store, and analyze the data quickly while k
How Annalect built an event log data analytics solution using Amazon Redshift
Ingesting and analyzing event log data into a data warehouse in near real-time is challenging. Data ingest must be fast and efficient. The data wa
Using Amazon’s Mechanical Turk for Machine Learning Data
How to build a model from Mechanical Turk resultsAmazon Mechanical Turk will notify you when your results are ready and you will finally have a labelled da
Quickly Filter Data in Amazon Redshift Using Interleaved Sorting
My colleague Tina Adams sent a guest post to introduce another cool and powerful feature for Amazon Redshift. — Jeff; Ama
AWS Marketplace: Matillion ETL for Amazon Redshift
Matillion ETL for Amazon Redshift makes loading and transforming data on Redshift fast, easy, and affordable. Prices start at $1.37/hour with no c
Disc Jam Case Study: Supporting a Mission for Fast-Paced Competitive Gameplay with Amazon Gamelift
About High Horse Entertainment Having gained over 20 years’ experience at both Treyarch and Activision, where they worked on succ
Top 10 Performance Tuning Techniques for Amazon Redshift
Ian Meyers is a Solutions Architecture Senior Manager with AWS Zach Christopherson, an Amazon Redshift Database Engineer, contributed to this post
Understand Connection Limits for Amazon Redshift
Amazon Web Services is Hiring. Amazon Web Services (AWS) is a dynamic, growing business unit within Amazon.com. We are currently hiring So
AWS Marketplace: Attunity Compose for Amazon Redshift (BYOL)
Amazon EC2 running Microsoft Windows Server is a fast and dependab
Build More Reliable and Secure Windows Services Using Amazon Kinesis Agent for Microsoft Windows
We’ve all been there. You’ve deployed a new service on Windows servers. Maybe it’s based on Microsoft technology such as IIS, AD, DHCP, Microsoft
PL/SQL Developer登錄出現——Using a filter for all users can lead to poor performance!
objects default devel http mage eve 配置 tool cnblogs 用PL/SQL Developer登錄Oracle時提示:Using a filter for all users can lead to poor performan
[Tools] Using mobile device for debugging your mobile web site
per ins conn build mode github and gpo actions 1. First you have enable "Developer mode" on your mobile device. (Different device might b
【論文速讀】Shitala Prasad_ECCV2018】Using Object Information for Spotting Text
Shitala Prasad_ECCV2018】Using Object Information for Spotting Text 作者和程式碼 關鍵詞 文字檢測、水平文字、FasterRCNN、xywh、multi-stage 方法亮點 作者argue影象中的文字不可能單獨出現,文字一定是寫
MSCNN論文解讀-A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
多尺度深度卷積神經網路進行快速目標檢測: 兩階段目標檢測器,與faster-rcnn相似,分為an object proposal network and an accurate detection network. 文章主要解決的是目標大小不一致的問題,尤其是對小目標的檢測,通過多
影象檢索入門:CVPR2015《Deep Learning of Binary Hash Codes for Fast Image Retrieval》
研究背景 在基於內容的影象檢索(CBIR)中,影象表示和計算成本都起著至關重要的作用。由於近幾年影象數量的增長,在大型資料庫中的快速搜尋成為新興需求。許多研究旨在回答如何從大規模資料庫中有效檢索相關資料的問題。由於高計算成本,傳統的線性搜尋
Paper Review: FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference FINN:一個用於建立高效能可擴充套件二值神經網路推測器的框架 基本資訊 發表日期:2016年12月 主要作者:Yaman Umuroglu
影象檢索入門:CVPR2016《Deep Supervised Hashing for Fast Image Retrieval》
TensorFlow程式碼:馬上新增 研究背景 在使用離散化時希望輸出的特徵的關於某個值對稱,所以如《Deep Learning of Binary Hash Codes for Fast Image Retrieval》用了 sigmoid 作為特徵層的輸出的
Hierarchical deep semantic hashing for fast image retrieval
本文主要是採用基於分層的思想進行模型構建,結合了概率語義層面相似(Probability-based semantic-level similarity)和雜湊層面相似(Hashing-level similarity)。 摘要 為解決大規模影
編譯Robust Stereo Visual Inertial Odometry for Fast Autonomous Flight
賓夕法尼亞大學kumar實驗室2018年釋出《Robust Stereo Visual Inertial Odometry for Fast Autonomous Flight 》,基於MSCKF基礎上實現雙目視覺慣導里程計。剛好這篇很新穎,又是雙目,我這個方向深入瞭解進去才
Dynamic Zoom-in Network for Fast Object Detection in Large Images 閱讀筆記
摘要 我們引入了一個通用框架, 它降低了物體檢測的計算成本, 同時保留了不同大小的物體在高解析度影象中出現的情況的準確性。檢測過程中以coarse-to-fine的方式進行,首先對影象的down-sampled版本,然後在一系列較高解析度區域上,識別出哪些可能