
Netflix Media Database - 起源和資料模型
前言
Netflix(美國最大的PGC視訊內容商)在18年下半年陸續發了幾篇文章來講述他們內部的NMDB系統的設計和實現,NMDB的全稱是Netflix Media Database,用於解決Netflix內部視訊結構化資料的統一儲存和分析問題。NMDB是完全由其內部業務需求驅動而孵化出來的,Netflix內部有足夠多的資料和最複雜的場景。所以NMDB是一個在視訊結構化資料處理這個垂直領域內被大量資料和複雜場景錘鍊過的一個產品,值得有相同場景需求的公司借鑑一下。
Netflix共釋出了三篇文章來講述NMDB,第一篇講述NMDB的起源、解決的問題以及設計目標,第二篇講述NMDB的資料模型,第三篇講述NMDB的架構實現,而本文是對這三篇內容的一個綜合解讀。本人非視訊分析和資料處理這個垂直領域的專家,不過擁有類似場景結構化資料儲存的經驗,如果有一些表述錯誤的地方,歡迎指正和交流。
附上原文連結:
- 《The Netflix Media Database》
- 《Netflix Media Database — the Media Timeline Data Model》
- 《Implementing the Netflix Media Database》
NMDB的起源
Netflix是全美最大的PGC視訊內容提供商,其商業成功的核心是內容和產品,產品的核心是使用者體驗,而驅動其產品使用者體驗提升的關鍵是資料和演算法。Netflix擁有龐大的視訊內容資料和使用者資料,如何利用這些資料通過演算法來驅動使用者體驗提升,是Netflix產品和技術上的最大挑戰。
友好的使用者介面、精準的個性化推薦、流暢的播放流以及豐富的分類目錄是Netflix使用者體驗最關鍵的幾個組成部分,需要各種各樣複雜的工作流結合在一起才能實現這種體驗。源源不斷越來越龐大的新的內容的產生和輸入,促使Netflix去思考如何開發一個系統,能夠幫助創意團隊高效的對這些新內容進行處理,及時合成高質量的數字資產。
通過對不同業務、需求和工作流的抽象,Netflix萌生了構建一個基礎平臺的想法。這個基礎平臺提供統一的演算法、計算工作流以及結構化元資料儲存,讓不同業務方能夠共享演算法和元資料,避免重複的計算來提升資料質量和提高工作效率。其中很重要的一個元件就是元資料儲存,它是一個統一的儲存平臺,用於儲存視訊資料經過演算法處理分析後產生的結構化元資料,持久化的同時提供高效索引,滿足不同維度靈活快捷的查詢和分析需求,這個統一的元資料庫就是NMDB。
為了更好的理解這一產品存在的意義,文中給了幾個實際應用場景的例子。
場景一:個性化推薦
上圖是各大視訊網站中常見的頁面,內容推薦系統如何根據使用者的喜好進行精準的個性化推薦,是提升訪問量、使用者留存和DAU的關鍵。個性化推薦系統以機器學習為核心,以媒體檔案(視訊、音訊和字幕)和元資料(分配標籤、概要)為輸入。
場景二:視訊和音訊編碼優化
高效的視訊和音訊編碼能夠大大提升媒體檔案的壓縮率,是保證更高質量流媒體流暢度的關鍵。對視訊內容時間和空間維度的分析,例如監測場景變化、識別視訊幀中的突出差異部分,這類資料是編碼系統非常關鍵的輸入。
場景三:源內容的質量稽核

上圖是一個典型的烏龍例子,畫面中出現了一個不該出現的物體。這類問題目前是可以通過技術手段探測和解決的,演算法能自動識別並標記特殊物體的位置。
以上是Netflix優化使用者體驗的幾個典型場景,雖然看上去不相關的幾個場景,但其實其底層依賴的資料和核心演算法,是有很多重疊的。例如探測視訊的『shot-change』,可以應用在視訊編碼優化,也可應用在視訊剪輯。再例如視訊文字識別,可應用於上述場景三,也可應用於電影海報挑選(自動規避包含文字的截圖)。
綜上,Netflix內部擁有非常多的業務場景,底層依賴相同的資料和核心演算法,需要抽象這麼一個底層產品:
- 提供統一的資料儲存。
- 避免對同一份資料的重複的計算分析(視訊分析的計算是非常非常昂貴的),統一儲存分析結果。
- 統一的模型,抽象並通用。
這個底層產品就是NMDB - Netflix Media Database。
NMDB的設計目標
NMDB用於儲存多媒體元資料(deeply technical metadata),並支援近實時(near real-time)查詢和分析。設計目標主要包括:
- 為結構化資料服務(Affinity to structured data):可定義結構化資料的schema,對資料進行儲存和索引,靈活支援查詢、搜尋和分析等不同需求。
- 時間線模型(Efficient media timeline modeling):支援對媒體的Timeline類資料進行建模,例如視訊截幀、字幕等擁有時間線屬性的資料。
- 時間和空間查詢(Spatio-temporal query-ability):支援時間(截幀、字幕等資料)和空間(視訊截幀部分割槽域資料)維度的查詢。
- 多租戶(Multi-tenancy)
- 高可擴充套件(Scalability)
NMDB就是Netflix底層多媒體資料的通用儲存,可支援對資料的任意時間和空間維度的查詢和分析,為Netflix內部不同的應用系統提供核心資料服務。
NMDB資料模型
NMDB提出的資料模型稱之為『Media Document』,這是一個靈活的通用的資料模型,它的首要設計目標是能相容不同型別Media資料對資料建模的需求,希望能通過同一套規範定義的資料模型來表達,並且具備靈活的可擴充套件性,來適應未來更多場景的建模需求。例如當前需要對視訊、音訊、字幕等資料建模,包含靜態和動態的,層次複雜的資料。
基本要素
這套模型的設計關鍵點在於抽象,NMDB認為『Media Document』本質上就是用於描述Media的時間線資料,外加額外的空間屬性。所以基於此理解,它提出了『Media Document』的三個基本要素:時間模型(Timing Model)、空間模型(Spatial Model)和巢狀結構(Nested Structure)。前面兩個點是對核心資料型別的抽象,第三點是對複雜組織結構的一個抽象,下面我們來分別看下這三個點分別代表什麼。
Timing Model
『Media Document』要建模的第一類資料是時間線資料,對這類資料的表示它提出了『Timed events』的概念。 『Timed events』即帶有時間屬性的事件,可以用來表示週期性連續的事件,也可用來表示零散的事件。例如連續的視訊幀就是連續的事件,而視訊中的『shot change』就是零散的事件,直接來看一個直觀的例子就能理解清楚。


上圖就是對字幕資料的一個表示,每段字幕為不同的事件,每個事件中包含覆蓋的時間區域。『Media Document』對事件間的關係不做任何假設和約束,每個事件覆蓋的時間區域可以是連續的、跳躍的或者是重疊的。定義了使用startTime和endTime來表示時間區域,使用metadata來表示事件內容,具備足夠的靈活性。
Spatial Model
空間維度是基於時間維度的另一層次擴充套件,我們直接看一個例子。

 『Media Document』定義了使用regions來表示空間屬性,是在『Timing Model』資料上的一個補充。例如上面是一個video_face_detection的例子,定義了一類event來表示人臉檢測的結果,在『Timed events』上帶了『regions』來描述人臉所屬的空間屬性。
『Media Document』定義了使用regions來表示空間屬性,是在『Timing Model』資料上的一個補充。例如上面是一個video_face_detection的例子,定義了一類event來表示人臉檢測的結果,在『Timed events』上帶了『regions』來描述人臉所屬的空間屬性。
Nested Structure
『Timing Model』和『Spatial Model』用於描述Media Document中的一系列事件,例如某一視訊幀、某段字幕或者某個特徵物體等。事件串起來構成事件流,Media中允許存在多類事件流,例如音訊事件流、視訊截幀事件流或者字幕事件流等。『Nested Structure』定義了這些事件流是如何組織的,Media Document定義了兩層的巢狀結構,分別為『track』和『component』,來看下一些示例:
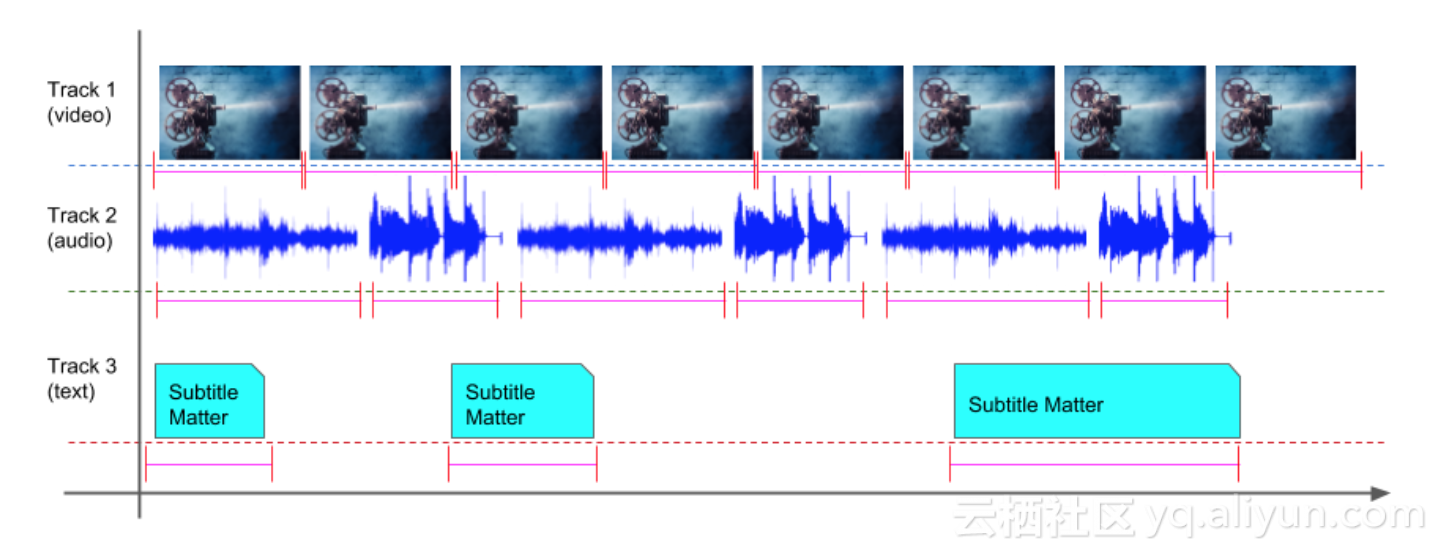
上述例子中視訊、音訊和字幕,分別由不同的track來表示,每個track內有一個component,component下就是時間和空間模型表示的事件流資料。
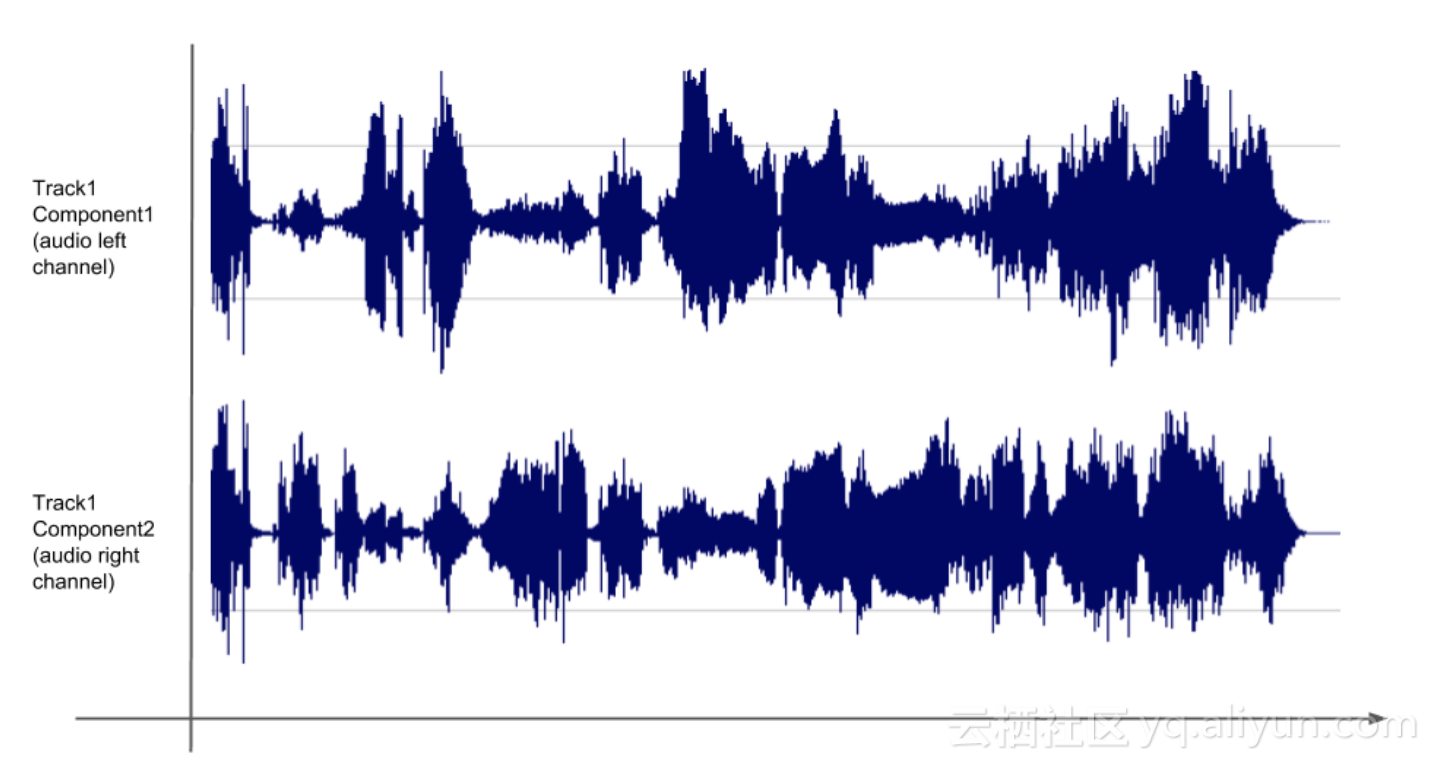
上述例子中雙聲道音訊,用同一個track但是不同的component來分別記錄左聲道和右聲道的記錄。
不過『Media Document』對把哪類資料定義為『track』或『component』並沒有限制,例如記錄雙聲道的音訊,可以有兩種組織形式:
- 和上述例子相同,使用一個track代表音訊,用兩個component分別代表左聲道和右聲道。
- 分兩個不同的track,一個是左聲道,另一個是右聲道。
Media Document
模型定義
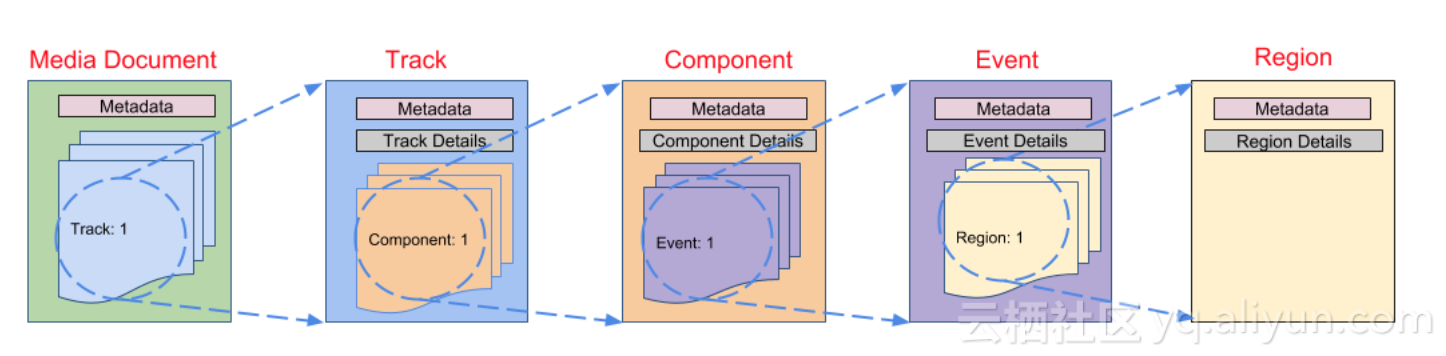
來看下『Media Document』的完整組成部分和各部分的組成關係:
- 一個Document由一個或多個Track組成
- 一個Track由一個或多個Component組成
- 一個Component由一個或多個Timed events組成
- 一個Event內可以包含零個或多個Region
另外還有一些強制性的約束:
- 每個Track和Component必須包含一個id屬性,來做唯一標識。
- Component層必須包含一些靜態資訊,包括:時間精度(幀率)和空間精度(解析度)。
- Event層必須包含時間屬性:startTime和endTime。
- Region層面必須包含空間熟悉。
- 每一層都可以有metadata屬性,用於儲存自定義的元資料
NMDB選擇用Json作為『Media Document』的表現格式,一個原因是已有一些開源的文件索引系統例如MongoDB和Elasticsearch,天然支援Json格式。一個完整的Json例子如下:

Document Schema
從上面關於『Media Document』的模型描述可以看到,NMDB提出了一些對這個模型的結構和約束的定義,就好比關係資料庫對關係模型的的行、列、主鍵索引等的定義。關係資料庫在建立表時需要定義Table Schema,NMDB也是一樣,需要定義Document Schema。
Document Schema是一個巢狀的文件結構,它描述了具體欄位的型別,例如可以明確哪個Event是字幕、某個欄位的具體型別等,方便查詢以及強型別校驗。NMDB底層索引系統採用了Elasticsearch,索引的Schema也需要給定欄位的明確的索引型別,例如對字幕資料需要指定全文索引,對空間資料需要指定空間索引等,依賴於Document Schema的定義。
NMDB支援Document Schema的動態更改,但是隻允許增加optional欄位,來同時保證向下和向上相容。
最後
想了解NMDB的架構設計和實現,請看下一篇。