
Netflix Media Database - 架構設計和實現
前言
前面一文主要講了NMDB的起源、業務場景以及Media Document資料模型,而本節主要講述NMDB的系統架構、核心模組以及底層技術。在深入瞭解其架構之前,我們先要明確NMDB的定位和功能設計目標,先看下Netflix內部視訊處理的整個流程:
- 演算法處理:Netflix內部有一個Archer平臺,在其上執行各種演算法來提取視訊資料中的元資料,例如提取視訊幀中文字資訊,提取的元資料為一個Media Document。
- 將Media Document寫入NMDB,對其進行持久化和索引。
- 業務方通過NMDB提供的API對Media Document資料進行查詢和分析,通常是一些帶特定領域特徵的時間和空間維度查詢。
- 查詢結果處理後展示給終端使用者。
NMDB主要負責2,3步驟,也就是說不負責演算法的執行,但負責對Media Document的儲存和索引,提供寫入、查詢和分析的功能支援。引用下原文中給NMDB的定義:
NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries. At any given time there could be several applications that are trying to persist data about a media asset (e.g., image, video, audio, subtitles) and/or trying to harness that data to solve a business problem.
接下來我們分別看下NMDB的架構和底層實現的一些細節,原文中對核心模組的巨集觀的東西描述較多,對一些功能點的實現細節描述較少。介紹了一些優化經驗以及未來的方向,不過對踩過的坑描述較少。
DataStore
資料模型章節介紹了『Media Document』的結構,『Media Document』就好比關係資料庫中表內的行的概念。
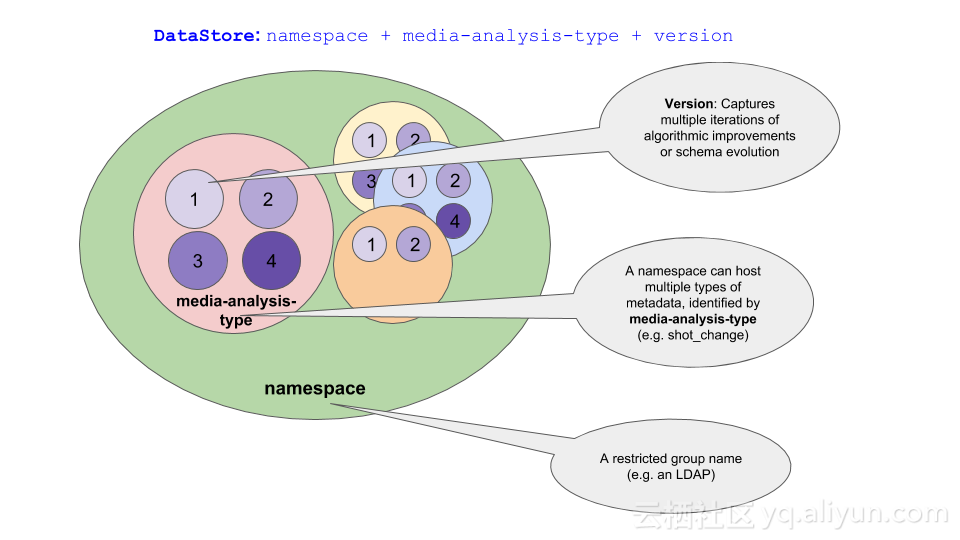
看上圖,其中namespace可以類比為mysql的database的概念,而DataStore可以類比為mysql的table的概念,document儲存於DataStore之中。NMDB中允許在namespace上定義訪問許可權,達到資料共享的目的。在namespace內,一個DataStore根據media-analysis-type和version來區分,這是一個比較直觀的概念,例如某個人臉檢測演算法的不同版本對應了不同的DataStore。Namespace可以認為是定義了同類資料的聚集以及共享的策略,media-analytis-type定義了演算法的類別,version定義了演算法的版本,這三者唯一定位一個DataStore。
DataStore需要定義MID Schema和Document Schema,其中Document Schema已經在上文中提到,是對文件內容的schema預定義以及同時保證向下和向上相容。MID是Document的一組附加屬性,由一個或多個String的Key/Value對構成。MID Schema是對MID的描述,一旦定義則不可再更改。除了MID外,每個Document還擁有一個DocumentID,是Document的唯一標識。
在NMDB中,可以通過DocumentID來查詢某個Document,也可以通過MID來查詢符合條件的所有Document。
資料儲存
NMDB中主要儲存的資料是Media Document,再來看下Media Document的資料組成:
- DocumentID:Document的唯一標識。
- MID:由MID Schema定義好的String型別的Key/Value對。
- Document:由Document Schema定義的可擴充套件的巢狀文件資料。
Media Document的資料有幾個關鍵的特徵,一是資料不可更改,二是弱關係無約束,三是單個Document資料較大。底層儲存首要考慮是資料的可靠性、儲存的規模以及寫入的吞吐。所以使用分散式NoSQL資料庫來持久化資料是比較合理的選擇,國外比較知名的是Cassandra,Netflix也是選擇了使用Cassandra作為持久化資料儲存。
Cassandra的特徵是Schemaless,Schemaless的特徵是『schema-on-read』,也就是說在查詢後才能知曉結構。而上文中提到NMDB其實對Schema是需要預定義的,即『schema-on-write』,需要保證寫入的資料符合Schema定義。為了在一個Schemaless的儲存上達到強Schema的約束,NMDB中引入了一個服務MDVS(Media Data Validation Service),主要作用就是在Document寫入NMDB前,根據Document Schema對Document做資料檢查。
在NMDB內部,由一個專門的服務MDPS(Media Data Persistence Service)來管理Cassandra叢集。MDPS接收Media Document(MID + Document)作為輸入,生成UUID作為DocumentID,也作為Cassandra表的Primary Key。MDPS中隱藏了Media Document到Cassandra表中Row的對映,文中對關係對映也沒有更多的描述。不過可以大概猜到應該是一個寬行的結構,一行為一個Document,MID和Document中的部分內容應該是拆分為多個欄位,為了方便後續的條件過濾以及區域性內容查詢。
資料索引
從文中的描述看,NMDB提供的查詢功能比較豐富,主要是對時間線(Media Timeline)資料的時間和空間維度的查詢,也有對非結構化資料的檢索(全文索引)。有覆蓋全文件的搜尋,也有文件內的區域性資料的條件查詢。
NMDB中處理查詢的模組有兩個,一個是MDQS(Media Data Query Service),另一個是MDAS(Media Data Analysis Service)。文中對MDQS的描述比較少,看不出它提供的功能主要是什麼,不過大致可以猜到應該主要是對Cassandra的查詢的封裝。
NMDB內選型用Elasticsearch作為文件的索引引擎,Elasticsearch本身就是一個分散式、高效能的文件模型索引資料庫,能夠同時滿足結構化資料(靈活的多欄位組合)以及非結構化資料(文字)的查詢和檢索需求,滿足擴充套件性以及高效能的要求。這也是業界比較成熟的一個架構,Cassandra + Elasticsearch或者HBase + Solr,Cassandra/HBase提供高吞吐、可靠的儲存,Elasticsearch/Solr提供對儲存的資料的索引,兩者結合打造一個整合高可靠資料儲存、高吞吐資料寫入、高效的多維度查詢、結構化及非結構化資料檢索一體的線上資料服務。MDAS管理了Elasticsearch叢集的寫入和查詢,並且對Media Document的儲存和索引做了非常多的優化,這個在後面的章節會細講。
資料查詢
在NMDB內部,主要常見的是兩種查詢模式:
- DataStore級別覆蓋所有文件的搜尋,搜尋的條件是任意欄位的條件組合。
- 指定DocumentID查詢某個特性的Document,條件獲取文件的部分資料。
文中沒有細說這兩種查詢場景分別是怎麼實現的,不過可以大致猜中第一種應該是利用了Elasticsearch的索引來做海量資料內的多條件組合查詢,而第二種場景應該是直接查詢Cassandra做條件過濾。
架構概覽
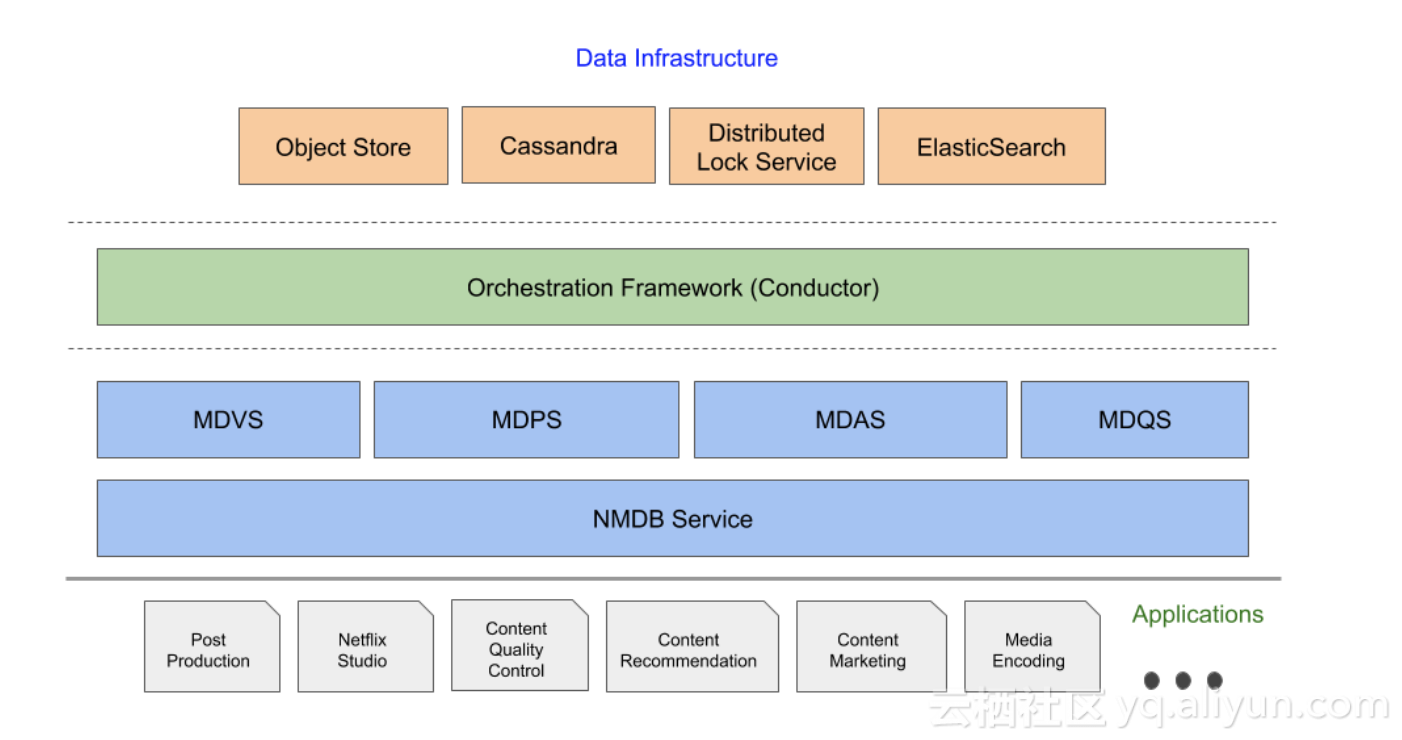
來看下NMDB的整體架構,核心服務包括MDVS、MDPS、MDAS以及MDQS,底層核心元件主要是Object Store(採用AWS的S3)、Cassandra、Distributed Lock Service以及Elasticsearch,外加一個用於協調所有流程的核心元件-Conductor。
Object Store在架構內部是作為資料交換的中樞,起了非常重要的作用。它儲存了原始的Media Document資料,一個Media Document的大小可能會非常大(數百MB,例如可能會儲存每一幀的元資料和空間屬性資訊等,會有較大的膨脹)。NMDB內部微服務架構的各個元件之間可能需要傳遞這些元資料,為了避免大量資料在傳輸鏈路中傳遞,所以採用了中心化的資料傳輸模式。
NMDB提供的讀操作是同步的,但是對於寫操作以及較長時間的分析操作均採取非同步化的方式,所有非同步的操作均通過Conductor的工作流來協調。『非同步化』是比較關鍵的一個設計點,大大簡化了系統設計。各元件之間被解耦,依賴被弱化,一個元件的失效不會影響其他元件,大大增加了架構的容錯性。不過『非同步化』也帶來一些By disign的不足,例如資料可查詢需要等資料被非同步的索引完成後,只能提供最終一致性的讀。這是一種架構設計需要做的權衡,相比提供業務非必需的強一致讀,還是優先保證架構的簡單幹淨,相信是一個比較容易作出的選擇。
寫流程
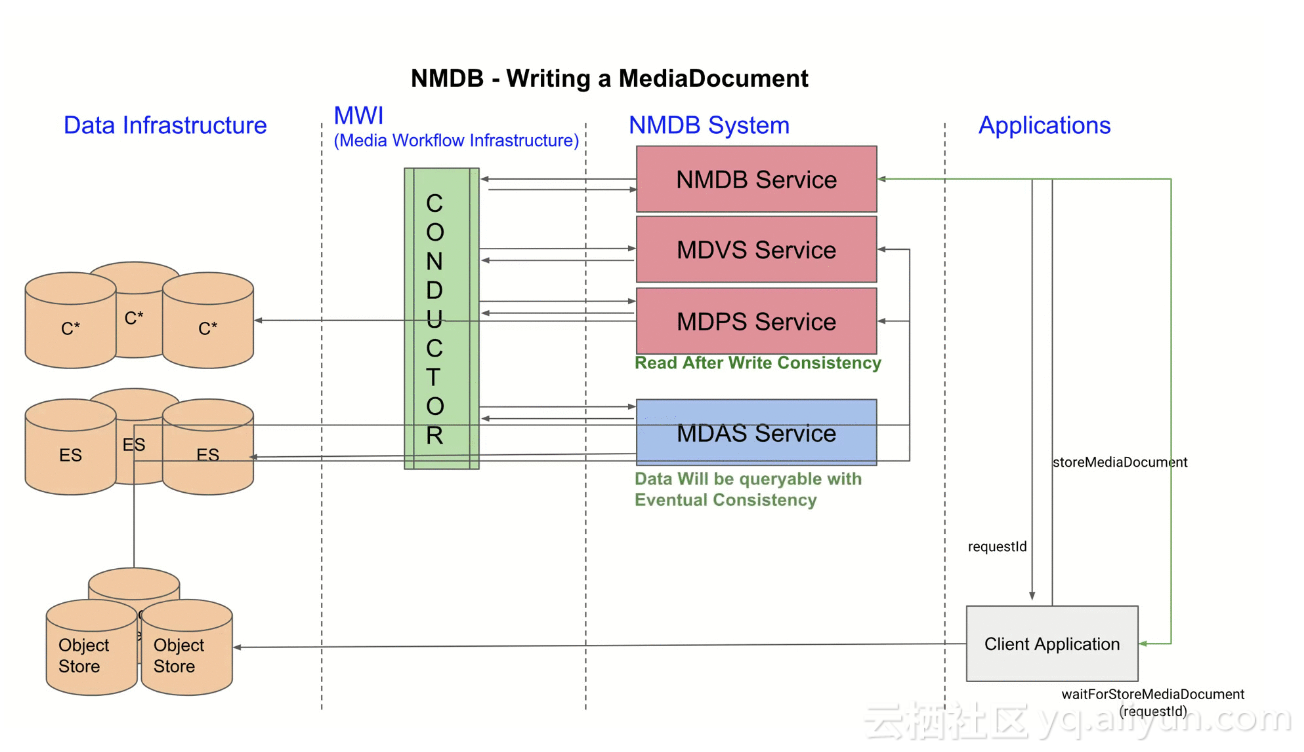
為加深對NMDB內部各模組功能及如何協作的理解,我們看下Media Document的整個寫入流程:
- Application將通過演算法平臺分析視訊檔案提取的Media Document存入Object Store。
- Application通知NMDB處理文件(通過傳遞Media Document在Object Store內的位置),整個處理過程是非同步的,所以NMDB會返回給應用一個requestId,可通過這個requestId來查詢工作流狀態。
- NMDB內部接到處理請求後,會開始一個新的Conductor工作流:
- 呼叫MDVS,根據Document Schema對Document內容進行校驗。
- 呼叫MDPS,將Document持久化入Cassandra,持久化完畢後即可提供資料讀取(read)。
- 呼叫MDAS,將Document通過Elasticsearch進行索引,索引完畢後即可提供搜尋和查詢(search and queries)
- 工作流結束後,該Document處理完成。
一些優化
Scaling strategies
NMDB內包含多個核心服務,分服務節點和資料節點,對於這些元件有不同的水位管理方式以及擴容策略。對於服務節點,需要關注服務是計算密集型還是IO密集型,例如對於MDVS是計算密集型服務,而對於MDAS是IO密集型服務,不同型別的服務需要關注不同的指標。另外對於提供同步請求的服務還是非同步請求的服務,關注點也不一樣,同步請求服務需要關注CPU和RPS(request per second),而非同步請求服務需要關注任務佇列長度。
對於服務節點的擴容,相對來說還是比較簡單的。一旦遇到瓶頸,擴容也比較容易,並且如果是做到無狀態的服務,那擴容基本上是很迅速以及無影響的操作。但對於資料節點,擴容就比較複雜,通常來說週期比較長,對於水位管理的挑戰的也更大。NMDB內部的資料節點主要是Object Store、Cassandra和Elasticsearch,對於Object Store無需關心水位,因為使用的是AWS的S3,而對於Cassandra和Elasticsearc則需要NMDB自己管理。
對於資料節點的擴容,就是水平擴充套件更多機器。但水平擴充套件是否有效,還取決於資料節點內的資料分佈以及是否儲存計算分離。對於儲存計算分離的架構,擴容機器後能很快的擴充儲存以及遷移計算壓力。而對於非儲存計算分離架構,則需要先搬遷資料後才能遷移計算壓力。典型的資料分佈有Range Partition和Hash Partition,對於Range Partition的資料庫例如HBase,水平擴容後只需要對Region進行Split,則很快就能打散計算壓力。而對於Hash Partition的資料庫例如Cassandra和Elasticsearch,則稍微有點不同。Cassandra採用一致性雜湊,擴容後也比較簡單能打散儲存和計算。但是Elasticsearch採用簡單的取模雜湊,水平擴容對於打散計算就不一定有效。
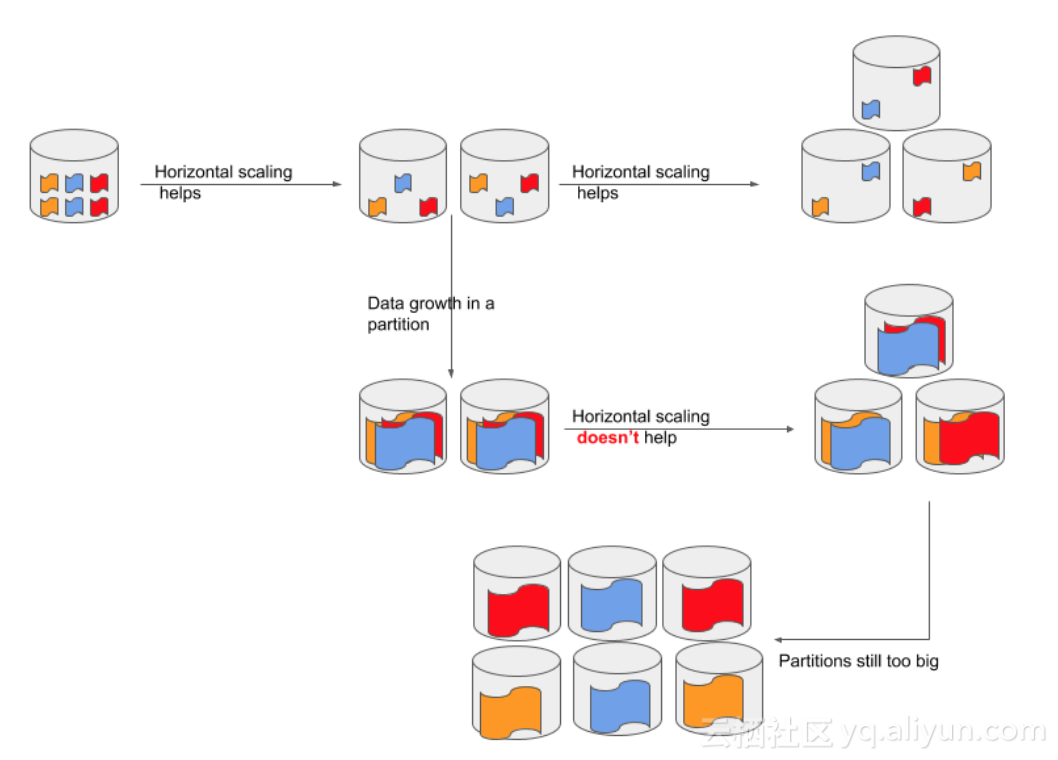
就如上圖所示,當Elasticsearch的一個Shard資料量不算大,那擴容後通過relocation shard,是能把資料和計算打散。但如果一個Shard的資料規模和計算消耗都很大,那擴容後即使對Shard做了一個打散,還是沒啥用。這個時候就需要對索引做Reindex,分配更多的Shard。但是Reindex是一個對計算消耗較大,非常耗時的一個操作,特別是當Index資料量已經很大的時候。
所以基於Elasticsearch當前的模式,NMDB採用了另外的策略,如下圖。
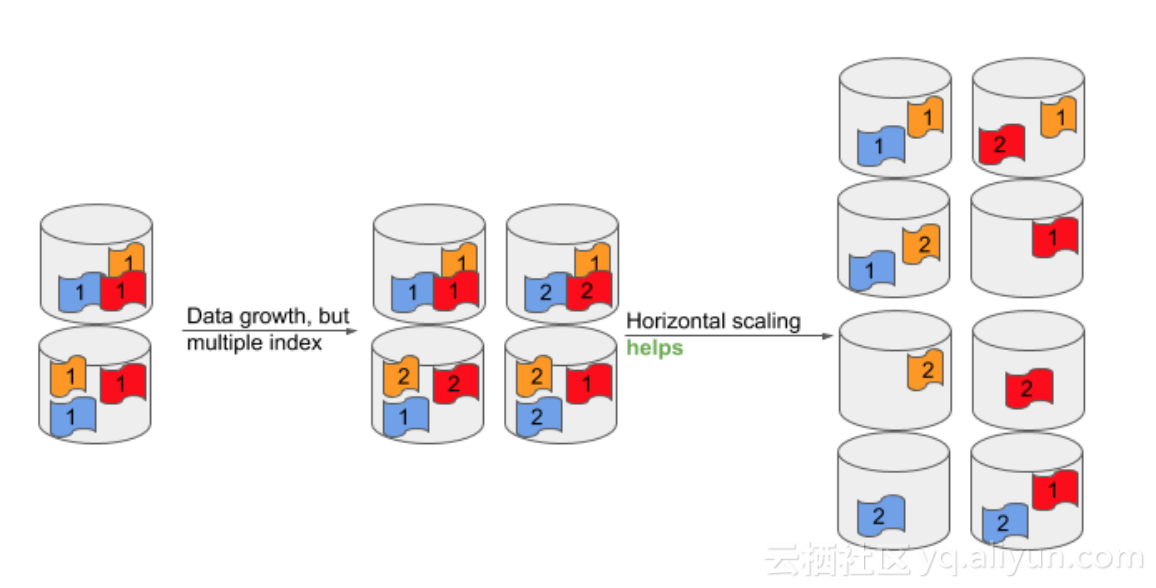
NMDB對Elasticsearch採用了多Index的設計,這也是利用了Media Document不可修改的特性(類似於ELK內日誌儲存的解決方案),所以可以按時間或大小來分Index。NMDB會控制一個Index的大小,來保證最優的讀寫速度。Elasticsearch本身也提供了index alias的功能,能夠跨索引做查詢。
Large Document
NMDB中一個Document可能達到數百MB,甚至是數GB的大小。在Elasticsearch內,對一個Document的大小會有限制。如果Document很大,那這一行資料整體也會很大,對於寫入和查詢都不是很友好(對寫入速度、並行處理度以及對CPU和記憶體的消耗都有影響)。
NMDB中設計了一個策略來解決Large Document的問題,思路比較簡單,就是將一個大文件分而治之,拆成多個小文件。Elasticsearch有提供兩種機制來做文件之間的關聯,一種是parent-child document,另一種是nested document。nested document支援多級巢狀,結構與Media Document比較匹配。不過當巢狀比較深的時候,查詢效能會急劇下降,而Media Document會有5層巢狀(Document -> Track -> Component -> Event -> Region)。parent-child document只支援兩級的關係,所以Media Document最多拆成量級,例如按照Event或Region來拆。不過這樣拆會導致child document數量很多,也會導致效能的極具下降。
NMDB採用的方案是parent-child,不過為了避免產生過多child,又採取了另一種策略 - chunking。『chunking』的思想是採取反正規化設計(SQL到NoSQL的思想之一),將一個大的文件拆成無關聯關係的多個小的文件,將需要保留的關聯資料複製到各個chunk中。這樣做之後有諸多好處,包括: 能並行處理、更均衡的資源消耗、避免熱點以及更快的索引速度。
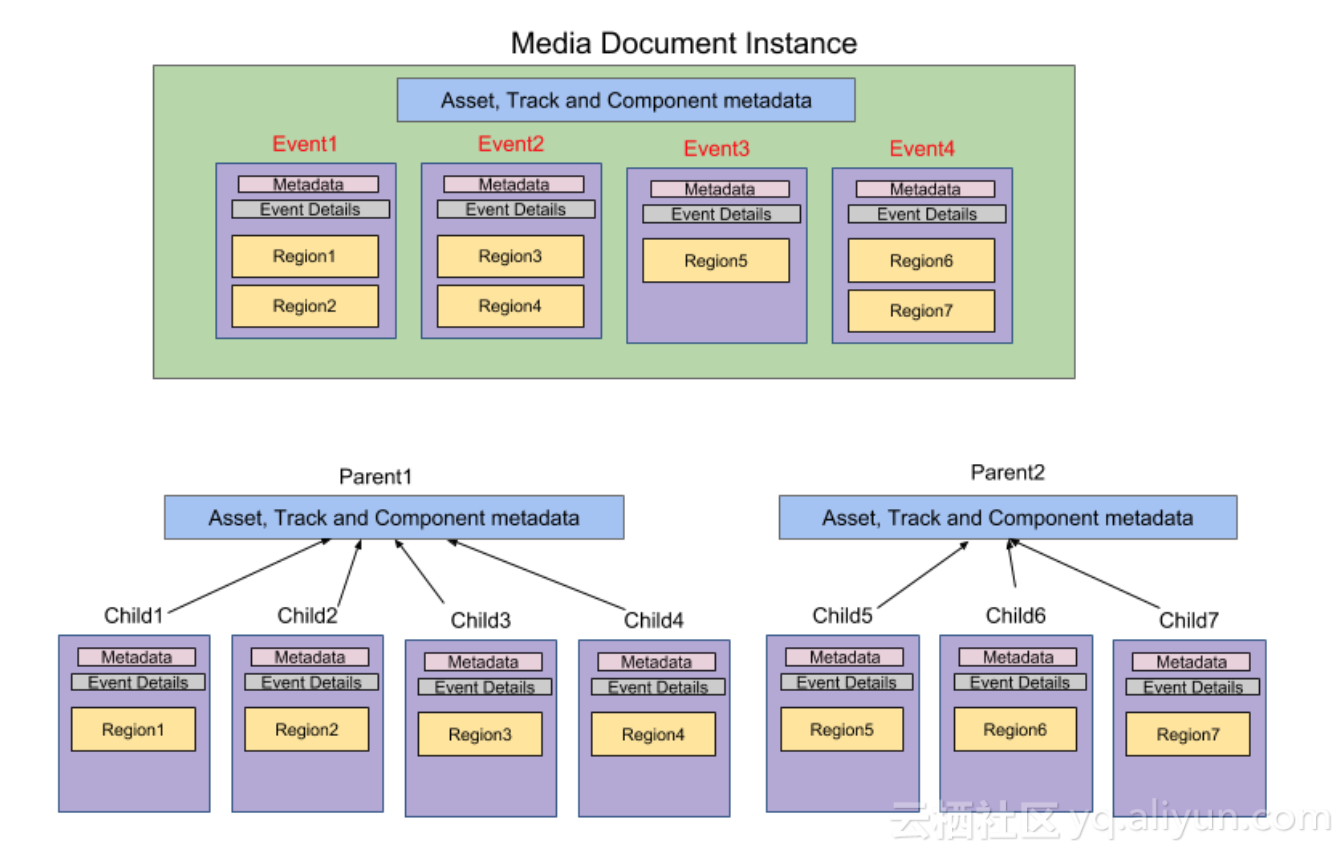
上圖就是對一個大文件進行『chunking』處理的例子,其中有幾個關鍵點:
- 以Event為最小單位,將一個Media Document拆分成大小均勻的多組父子文件,每個父文件中重複儲存Track和Component的元資料。
- 按每個Region變成一個子文件,每個子文件中重複儲存Event的元資料。
what's next
文中最後提出了幾個未來會去調研和改進的點:
- 模型改進:Media Document的資料模型是比較直觀的巢狀層次結構模型,但是不利於並行處理(上文提到是反正規化的設計來拆解)。一種對平行計算更友好的結構應該是組合結構,例如將一條時間線拆成多個小的時間線,每個小的時間線為一個Media Document。
- 計算優化:NMDB面臨越來越多的跨DataStore的大資料分析,會去調研引入其他的大資料計算方案。
最後,NMDB發源自Netflix,擁有最多的客戶需求,最豐富的資料以及最複雜的場景。只有不斷的做架構迭代,探索並引入新的技術,才能從容的面臨挑戰。