
Python爬蟲+requests+偽裝瀏覽器 爬取小說入門總結
前言:
Python越來越流行,跟著時代的程序,我也不用全身心的投入訓練,我也來玩玩Python,想著以後工作應該不會有windows的所以我就去安裝了Ubuntu 和win10的雙系統,這個現在網上到處都是教程我就不細說了,按著教程來就是,百度是個萬能的東西,至於pycharm也一樣的。
我的配置:Ubuntu16.04+pycharm2018.3(Professional)。
預備知識:
爬蟲我的理解:
爬蟲(spider)故名思議就是像一個蜘蛛一樣在網頁上爬來爬去獲取我們想要的東西。
爬蟲的原理:
這個需要一點的計算機網路的知識啦,當我們瀏覽網頁的時候,我們想訪問那個網站就可以在瀏覽器輸入網址就好,用專業術語來解釋一下,就是我們的瀏覽器也就是客服端像網站的伺服器傳送一個請求,這個過程就叫請求,當伺服器收到我們傳送的請求的後就把我們訪問的資料給們傳送過來,這個稱之為響應,當然傳送的是自己HTML的程式碼,當我們的瀏覽器接收到這些響應後就編譯HTML程式碼給我們看,我們要得是這些資料,所以我們用了python的requests的庫函式去模擬瀏覽器就可以收到伺服器的資料。
資料的提取:
python最強到的地方就是它有各種各樣的庫你能想到的庫它都有,沒有的是你不知道,對於伺服器返回的資料有很多是我們不需要的,所以需要我們把有用的資料提取出來,這個用到了正則表示式,Python的re庫正則表示式我覺得十分複雜,不過我相信等我們用過很多次後一定會認為這個正則表示式也不過如此,對於不同的網頁網頁結構不同,我們提取內容的正則表示式也不一樣,感興趣的自己去詳細學習一下,在這裡為了直接用我們就舉個例子:
content=re.findall('<title>(.*?)</title>',html)
這個式子中,htm l表示我們傳送請求的後伺服器返回給我們的資料(一個很長很大的列表),content表示我們提取後得到的內容,而re.findall()這個函式表示的正是用正則表示式re庫中的findall函式去提取內容,最重要的就是這個''<title>(.*?)</title>',其中,<title>為html中的內用,而 (.*?) 則是我們需要提取的內容,其中“.*?”表示任意內容,這個括號表示提取出來,這兩個<title>用於定位,整體的的意思就是在html中提取所有兩個'<title>'中間的任意內容。
求情訪問以及偽裝:
Python就是這麼方便你想爬蟲,只需要需要直接呼叫庫函式就好,我用的是requests庫:response=requests.get(url) 其中response就是其響應,包括了所有內容,有的時候需要response.encoding='utf-8' 來確定其編碼,然後html=response.text,然後輸出html就是在網頁上按F12下面出現內容一樣的東西啦。我以爬取noel_url='http://www.tianyashuku.com/wuxia/7/'為例,初步程式碼為:
novl_url='http://www.tianyashuku.com/wuxia/7/'#小說的url
response=requests.get(novl_url)#模擬瀏覽器進行訪問
response.encoding='utf-8'#確定編碼規則
html=response.text
print(html)

這是爬取後的《倚天屠龍記》小說的主頁面Python輸出的結果以及在瀏覽器上按F12,看到的網頁編輯框。
現在隨著爬蟲越來越火熱越來越多的人會爬蟲,然後如果一個網站有爬蟲程式大量的訪問的話一定會使網路癱瘓,使那些正常使用者又不好的正常體驗,所以一般都有一定的反爬機制,一般有三種方法第一種是對你的訪問進行識別如果你不是瀏覽器的話直接拒絕訪問了,可以讓你的爬蟲偽裝成一個瀏覽器就好,第二種則是發現你有異常的訪問直接封你的ip23333,也有技術手段可以讓你邊訪問邊修改你的ip地址,第三種是設計動態網頁,也可以用技術手段解決。參考見:最全反爬蟲技術介紹。對於本蒟蒻,以及我們本次訪問的網站我們就只使用偽裝成瀏覽器的方法來成功的爬取。
在requests去訪問網站時會如實的告訴伺服器自己是什麼,所以這時需要我們把爬蟲偽裝一下,一般只需要這樣(來源):
socket.setdefaulttimeout(10)#socket訪問時延
send_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}#偽裝成瀏覽器
response=requests.get(novl_url,send_headers)#訪問
response.close()#訪問後就關閉訪問在我沒發現伺服器拒絕我訪問的時候我還不知道是什麼問題,各種百度,先讓我設定套接字的延時以及訪問後就關閉訪問,最後才知道要偽裝成瀏覽器233333,最後本網站不受阻的訪問一個網站就是這樣完成了。
提取小說的標題以及章節資訊:
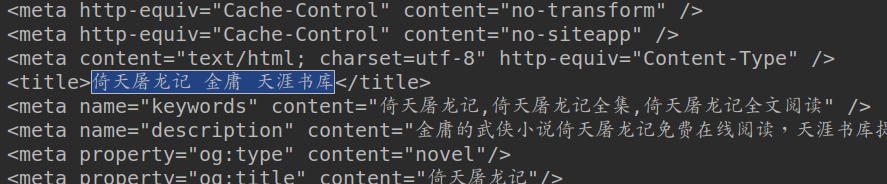
看到這個標題沒有這就是我們需要的東西,如果網頁規範的話其他小說也是這樣的格式(<title>標題</title>)可以自需要更改小說的主頁的url就好,不過這個網站不規範,每部小小說都不一樣2333,爬其他的都需要換正則表示式....
我們再把這個從 html 中標題提取出來
title=re.findall('<title>(.*?)</title>',html)[0]#返回的是一個列表提 [0]取出來
print(title)
可以了,可是我們爬取的是整本小說又不是隻有這個標題,看這個小說的主介面不但有每個章節的連結以及標題:


這就是我們需要的每一章節的url以及標題,我們需要把每個章節的標題以及url都提取出來,那麼我們就需要類似的提取標題一樣的方法將其提取出來:
chapter_info=re.findall('<a href="(.*?)" title="(.*?)">.*?</a>',html)
print(chapter_info)
所有的章節的url以及標題都被提取出來了,然後就是依次的進行訪問。
小說內容的爬取與內容儲存到txt:
在上面的每個小說章節的url都被提取出來啦剩下的就是依次訪問啦,可能你們以及注意到了,除了第一個我們提取的url中只有一半是不能正常訪問的,會報錯,所以我們把殘缺的內容補上就好了,問題又來了如果我們全在訪問前補全網址我們第一個正確的url也會出錯,無法正常訪問,問題是無窮無盡的我們在不斷學習的過程中發現問題解決問題,這就是學習的過程,正好第一個是網站的主頁,是我們不需要的,我們可以chapter_info.pop(0)把第一個刪除了,也可以在特判第一個不補全,但是我採用的是try:except:語句,這樣如果我們不但可以解決第一個有出錯的的問題,又可以處理在在不是第一個url無法訪問的時候出錯了我們還可以爬取下一章節,十分強大。
對於寫入txt文件,就是按照模板來就好啦,先寫入標題,然後訪問每一個章節的url爬取小說的內容,可氣的是最後的一章和前面的所有章節都有一個不同點,那就是前面的章節都是<p>(一自然段)</p>唯獨只有最後一個章節是<P>(一自然段)</P>,最開始我還沒發現,我看成果的時候才發現,最開始我用的是
re.findall(r'[<P>|<p>] (.*?)[<P>|<p>]',chapter_html);
最後一章的確可以爬取啦,不過就是最後一章每一自然段都會差那麼一段而且還有部分亂碼,不知道為什麼,最後改成現在這樣就啥問題沒有了,難受。然後就是可能是配置問題我爬取的內容中的有些符號會便成程式碼為了讓我的爬取的小說更加美觀我們需要把這些程式碼都替換回來。
訪問url都是一樣的我就不說細說啦看程式碼:
fp=open('%s.txt'%title,'w',encoding='utf-8')#建立這個txt,%s十分智慧2333
fp.write(title)#先將標題寫入文件
fp.write('\n\n')#兩個回車
for chapter in chapter_info:
chapter_title=chapter[1]
#由於正則表示式中有兩個(.*?)所以章節都是二維列表 0是標題 1是url
chapter_url='http://www.tianyashuku.com' +chapter[0]#補全url
print(chapter_url,chapter_title)#列印url以及標題,這樣在爬蟲的時候我們能看我們爬取到哪裡了
try:
chapter_response=requests.get(chapter_url,send_headers)
chapter_response.encoding='utf-8'
chapter_html=chapter_response.text
chapter_response.close()
#print(chapter_html)
chapter_content=re.findall(r'<[P/p]> (.*?)</[P/p]>',chapter_html);
#匹配每一自然段
fp.write(chapter_title)
fp.write('\n')#寫入每一章節的標題並回車
try :
for content in chapter_content:
#因為正則表示式的原因我們爬取每一個章節的內容都是每一個元素為一自然段的列表,所以我們需要在來一個迴圈來寫入
#print(content)
temp=str(content)
temp=temp.replace('·','.')
temp=temp.replace('”','”')
temp=temp.replace('“','“')
temp=temp.replace('…','…')
temp=temp.replace('—','—')
temp=temp.replace('’','’')
temp=temp.replace('‘','‘')
#標點符號替換標點符號程式碼
fp.write(temp)
fp.write('\n ')
print("成功訪問並寫入:%s"%chapter_title)
fp.write('\n')
except:
print("寫入出錯!")
except:
print("訪問失敗!")
成果:
完整程式碼:
import requests
import re
import time
import socket
socket.setdefaulttimeout(10)
novl_url='http://www.tianyashuku.com/wuxia/7/'
send_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}#偽裝成瀏覽器
#小說的url
response=requests.get(novl_url,send_headers)#訪問
response.close()
response.encoding='utf-8'
html=response.text
#print(html)
title=re.findall('<title>(.*?)</title>',html)[0]
fp=open('%s.txt'%title,'w',encoding='utf-8')
print(title)
fp.write(title)
fp.write('\n\n')
chapter_info=re.findall('<a href="(.*?)" title="(.*?)">.*?</a>',html)
for chapter in chapter_info:
chapter_title=chapter[1]
chapter_url='http://www.tianyashuku.com' +chapter[0]
print(chapter_url,chapter_title)
try:
chapter_response=requests.get(chapter_url,send_headers)
chapter_response.encoding='utf-8'
chapter_html=chapter_response.text
chapter_response.close()
print(chapter_html)
chapter_content=re.findall(r'<[P/p]> (.*?)</[P/p]>',chapter_html);
fp.write(chapter_title)
fp.write('\n')
try :
for content in chapter_content:
temp=str(content)
temp=temp.replace('·','.')
temp=temp.replace('”','”')
temp=temp.replace('“','“')
temp=temp.replace('…','…')
temp=temp.replace('—','—')
temp=temp.replace('’','’')
temp=temp.replace('‘','‘')
fp.write(temp)
fp.write('\n ')
print("成功訪問並寫入:%s"%chapter_title)
fp.write('\n')
except:
print("寫入出錯!")
except:
print("訪問失敗!")
#fp.close()
print(len(chapter_info))爬取的小說(95w字,10s不到,2.9MB23333):
